After seeing a lot of questions surrounding incremental repair on the mailing list and after observing several outages caused by it, we figured it would be good to write down our advices in a blog post.
Repair in Apache Cassandra is a maintenance operation that restores data consistency throughout a cluster.
It is advised to run repair operations at leasts every gc_grace_seconds to ensure that tombstones will get replicated consistently to avoid zombie records if you perform DELETE statements on your tables.
Repair also facilitates recovery from outages that last longer than the hint window, or in case hints were dropped. For those operators already familiar with the repair concepts, there were a few back-to-basics moments when the behavior of repair changed significantly in the release of Apache Cassandra 2.2. The introduction of incremental repair as the default along with the generalization of anti-compaction created a whole new set of challenges.
How does repair work?
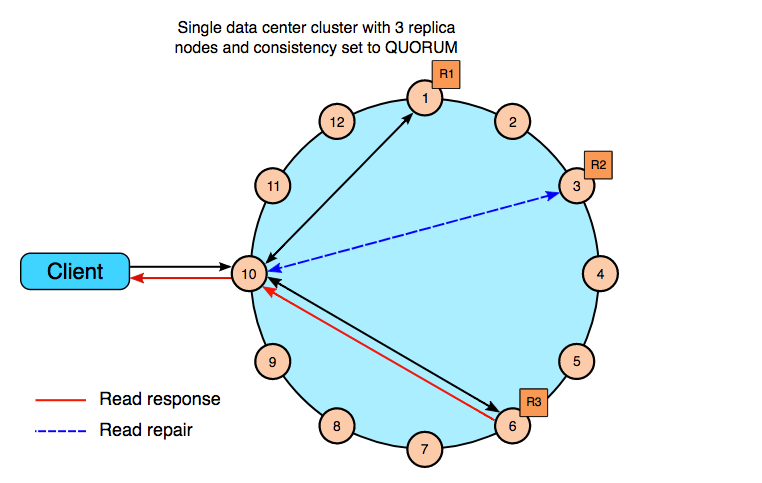
To perform repairs without comparing all data between all replicas, Apache Cassandra uses merkle trees to compare trees of hashed values instead.
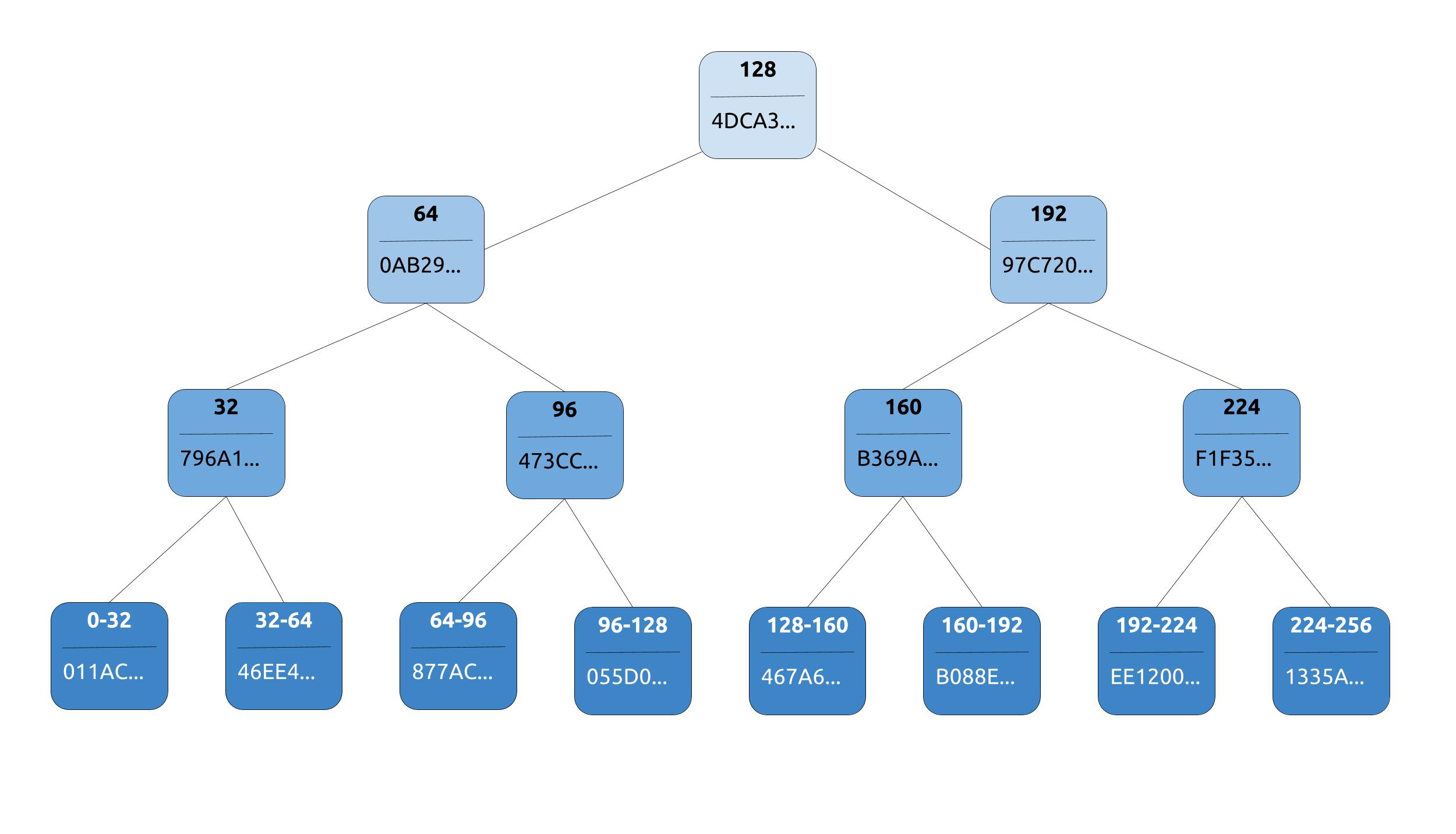
During a repair, each replica will build a merkle tree, using what is called a “validation compaction”. It is basically a compaction without the write phase, the output being a tree of hashes.
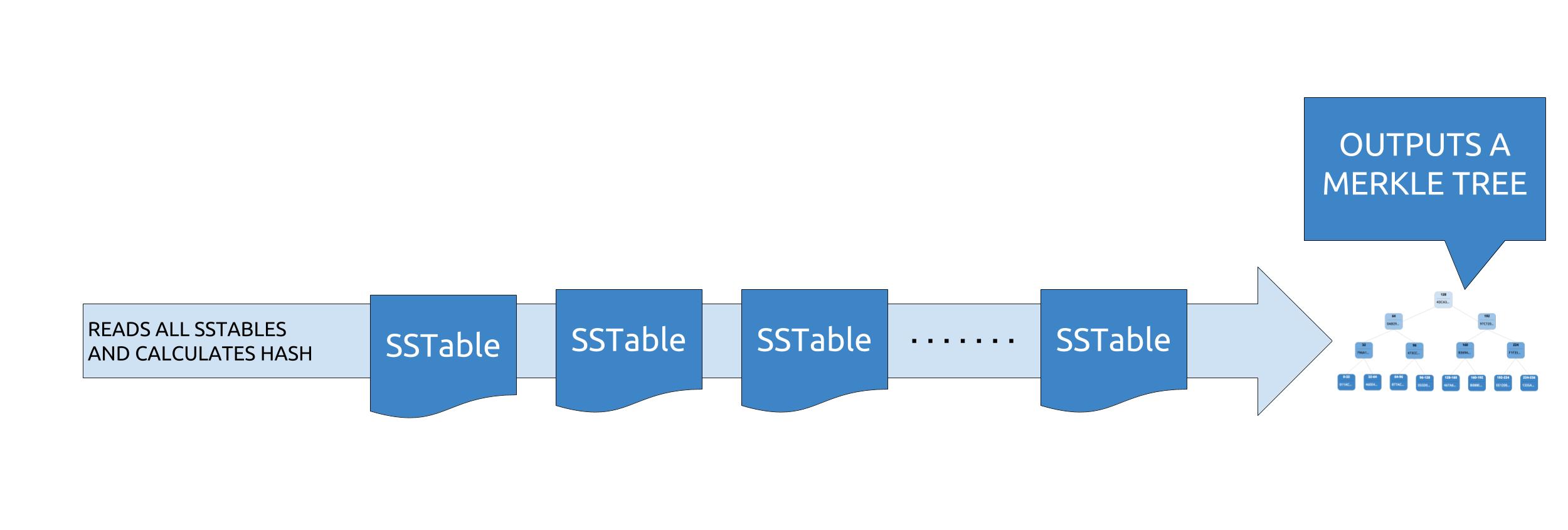
Merkle trees will then be compared between replicas to identify mismatching leaves, each leaf containing several partitions. No difference check is made on a per partition basis : if one partition in a leaf is not in sync, then all partitions in the leaf are considered as not being in sync. When more data is sent over than is required it’s typically called overstreaming. Gigabytes of data can be streamed, even for one bit of difference. To mitigate overstreaming, people started performing subrange repairs by specifying the start/end tokens to repair by smaller chunks, which results in having less partitions per leaf.
With clusters growing in size and density, performing repairs within gc_grace_seconds started to get more and more challenging, with repairs sometimes lasting for tens of days.
Some clever folks leveraged the immutable nature of SSTables and introduced incremental repair in Apache Cassandra 2.1.
What is incremental repair?
The plan with incremental repair was that once some data had been repaired, it would be marked as such and never needed to be repaired anymore.
Since SSTables can contain tokens from multiple token ranges, and repair is performed by token range, it was necessary to be able to separate repaired data from unrepaired data. That process is called anticompaction.
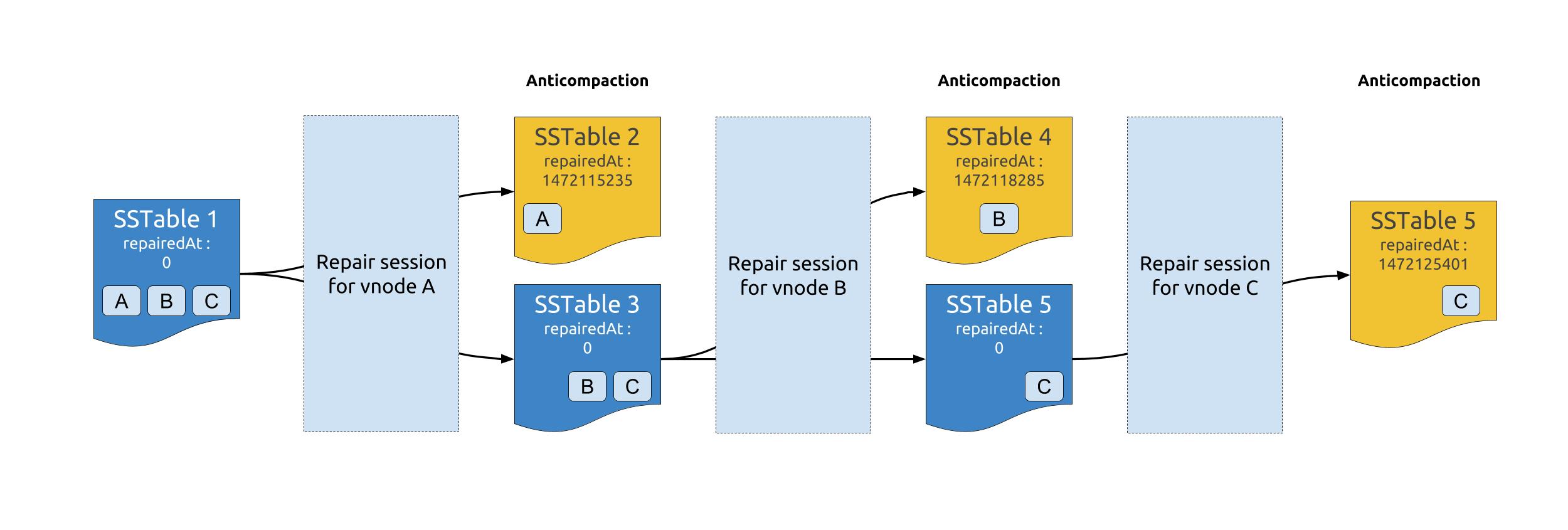
Once a repair session ends, each repaired SSTable will be split into 2 SSTables : one that contains the data that was repaired in the session (ie : data that belonged to the repaired token range) and another one with the remaining unrepaired data. The newly created SSTable containing repaired data will be marked as such by setting its repairedAt timestamp to the time of the repair session.
When performing validation compaction during the next incremental repair, Cassandra will skip the SSTables with a repairedAt timestamp higher than 0, and thus only compare data that is unrepaired.
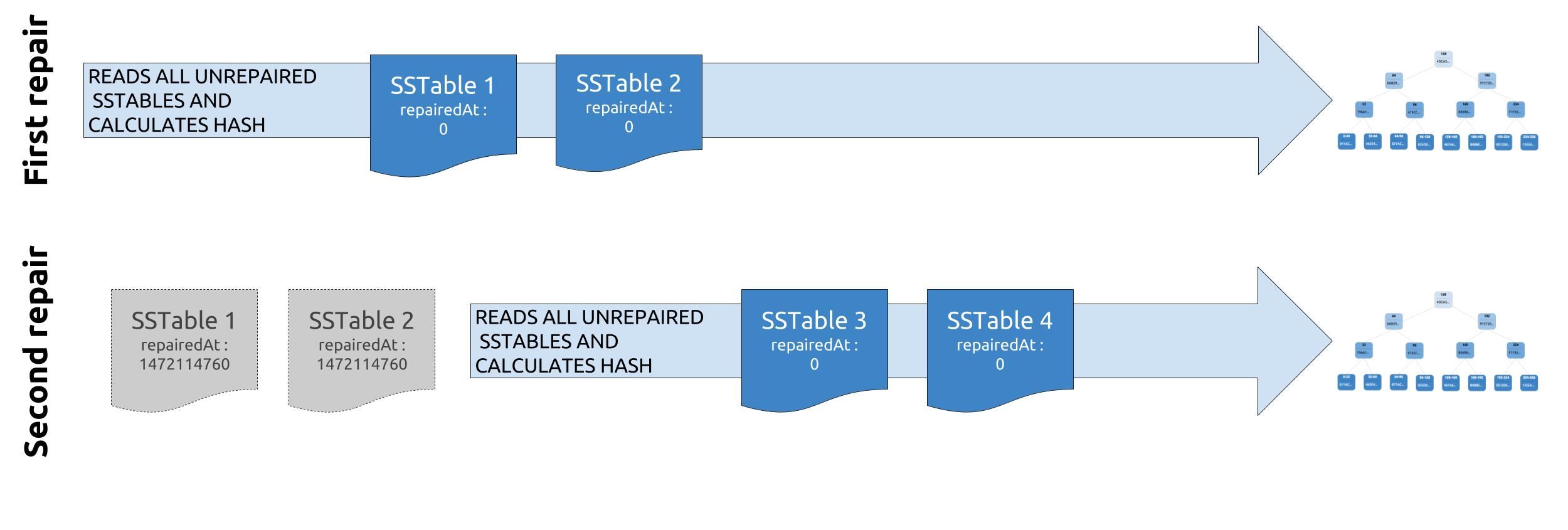
Incremental repair was actually promising enough that it was promoted as the default repair mode in C* 2.2, and anticompaction was since then also performed during full repairs.
To say the least, this was a bit of a premature move from the community as incremental repair has a few very annoying drawbacks and caveats that would make us consider it an experimental feature instead.
The problems of incremental repair
The most nasty one is filed in the Apache Cassandra JIRA as CASSANDRA-9143 with a fix ready for the unplanned 4.0 release. Between validation compaction and anticompaction, an SSTable that is involved in a repair can be compacted away as part of the standard compaction process on one node and not on the others. Such an SSTable will not get marked as repaired on that specific node while the rest of the cluster will consider the data it contained as repaired.
Thus, on the next incremental repair run, all the partitions contained by that SSTable will be seen as inconsistent and it can generate a fairly large amount of overstreaming.
This is a particularly nasty bug when incremental repair is used in conjunction with Level Compaction Strategy (LCS). LCS is a very intensive strategy where SSTables get compacted way more often than with STCS and TWCS.
LCS creates fixed sized SSTables, which can easily lead to have thousands of SSTables for a single table. The way streaming occurs in Apache Cassandra during repair makes that overstreaming of LCS tables could create tens of thousands of small SSTables in L0 which can ultimately bring nodes down and affect the whole cluster. This is particularly true when the nodes use a large number of vnodes.
We have seen happening on several customers clusters, and it requires then a lot of operational expertise to bring back the cluster to a sane state.
In addition to the bugs related to incorrectly marked sstables, there is significant overhead of anti-compaction. It was kind of a big surprise for users upgrading from 2.0/2.1 to 2.2 when trying to run repair. If there is already a lot of data on disk, the first incremental repair can take a lot of time (if not forever) and create a similar situation as above with a lot of SSTables being created due to anticompaction. Keep in mind that anticompaction will rewrite all SSTables on disk to separate repaired and unrepaired data.
While it’s not necessary anymore to “prepare” the migration to incremental repair, we would strongly advise against running it on a cluster with a lot of unrepaired data, without first marking SSTables as repaired. This would require to run a full repair first to make sure data is actually repaired, but now even full repair performs anticompaction, so… you see the problem.
A safety measure has been set in place to prevent SSTables going through anticompaction to be compacted, for valid reasons. The problem is that it will also prevent that SSTable from going through validation compaction which will lead repair sessions to fail if an SSTable is being anticompacted. Given that anticompaction also occurs with full repairs, this creates the following limitation : you cannot run repair on more than one node at a time without risking to have failed sessions due to concurrency on SSTables. This is true for incremental repair but also full repair, and it changes a lot of the habit you had to run repair in previous versions.
The only way to perform repair without anticompaction in “modern” versions of Apache Cassandra is subrange repair, which fully skips anticompaction. To perform a subrange repair correctly, you have three options :
- Compute valid token subranges yourself and script repairs accordingly
- Use the Cassandra range repair script which performs subrange repair
- Use Cassandra Reaper, which also performs subrange repair
Regardless, it is extremely important to note that repaired and unrepaired SSTables can never be compacted together. If you stop performing incremental repairs once you started, you could end up with outdated data not being cleaned up on disk due to the presence of the same partition in both states. So if you want to continue using incremental repair, make sure it runs very regularly, and if you want to move back to full subrange repairs you will need to mark all SSTables as unrepaired using sstablerepairedset.
Note that due to subrange repair not performing anti-compaction, is not possible to perform subrange repair in incremental mode.
Here’s our advice at the time of writing this blog post, based on our experience with customers : perform full subrange repair exclusively for now and do not ever run incremental repair. Just pretend that feature does not exist for now.
While the idea behind incremental repair is brilliant, the implementation still has flaws that can cause severe damage to a production cluster, especially when using LCS and DTCS. The improvements and fixes planned for 4.0 will need to be thoroughly tested to prove they fixed incremental repair and allow it to be safely used as a daily routine.
We are confident that future releases will make incremental repair better, allowing the operation to be safe and blazing fast compared to full repairs.