
There are 3 mechanisms for making sure that your data stays in sync and consistent.
- Read Repair
- Hinted Handoff
- Anti-Entropy Repair
Read Repairs compare values and updates (repairs) any out of sync. Read Repairs happen when a read is done — the coordinator node then compares the data from all the remaining replicas that own the row in the background and if they are inconsistent, issues writes to the out-of-date replicas to update the row with the most recently written values.
Read Repairs can be configured per column family and is enabled by default.
There are 2 types of read repair, foreground and background. Foreground means blocking. We complete all operations before returning to the client. Background means non-blocking. We begin the background repair operation and then return to the client before it has been completed.
Foreground (Blocking) Read Repair
Foreground read repair is always performed on queries which use a consistency level greater than ONE or LOCAL_ONE.
The coordinator asks one replica for data and the others for digests of their data. If there’s a mismatch, we resolve it by doing a data read from all replicas and then merging the results. After we’ve determined the latest version of the record, we write it back to only the replicas involved in the request.
For consistency level of LOCAL_QUORUM read with RF=3, we would have originally queried two replicas, so those will be the only two that we repair.
For consistency level of ONE or LOCAL_ONE, a query can’t cause a blocking read repair because we must have a data mismatch to trigger the read repair and we if only queried one replica, there is no comparison, so mismatch.
So basically, if the two chosen replicas disagree in LOCAL_QUORUM example, a blocking read repair is done to ensure you get the latest value from the 2 replicas.
Background (Non-Blocking) Read Repair
The two read repairs that are governed by “chance” parameters (read_repair_chance and dc_local_read_repair_chance) are both background repairs.
Background read repairs happens as follows. If the read repair chance properties are not zero on a table, then during each query we ask a random number generator for a number between 0.0 and 1.0. We first see if the random number is less than or equal to read_repair_chance. If it is, we perform a non-block global read repair.
If it is, we perform a non-blocking read repair in the local DC only. We use a single random value for both of these chance repair tests and global read repair is evaluated first.
How to look at read repair statistics?
- nodetool tpstats in the ReadRepairStage row
- nodetool netstats (is better) will show you stats on number of attempted read repairs and whether they were blocking or background
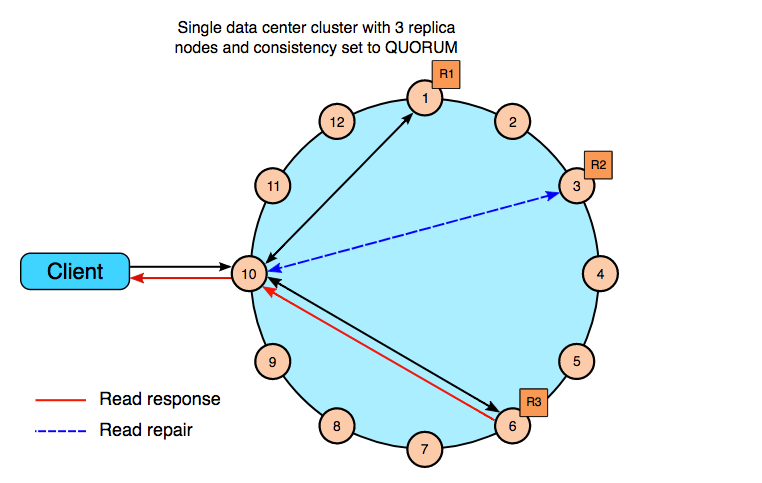
Examples of Read Repairs
The above example is a single data center cluster with a consistency level of QUORUM and a replication factor of 3. This means that 2 of the 3 replicas for the given row must respond to fulfill the read request. If contacted replicas have different versions of the row, the replica with the most recent version will return the requested data. In the background, the third replica is checked for consistency with the first two, and if needed a read repair is initiated for the out of data replicas.





