In our previous post, “Should you use incremental repair?”, we recommended to use subrange full repairs instead of incremental repair as CASSANDRA-9143 could generate some severe instabilities on a running cluster. As the 4.0 release approaches, let’s see how incremental repair was modified for the next major version of Apache Cassandra in order to become reliable in production.
Incremental Repair in Pre-4.0 Clusters
Since Apache Cassandra 2.1, incremental repair was performed as follows:
- The repair coordinator will ask all replicas to build Merkle trees only using SSTables with a RepairedAt value of 0 (meaning they haven’t been part of a repair yet).
Merkle trees are hash trees of the data they represent, they don’t store the original data. - Mismatching leaves of the Merkle trees will get streamed between replicas
- When all streaming is done, anticompaction is performed on all SSTables that were part of the repair session
But during the whole process, SSTables could still get compacted away as part of the standard automatic compactions. If that happened, the SSTable would not get anticompacted and all the data it contains would not be marked as repaired. In the below diagram, SSTable 1 is compacted with 3, 4 and 5, creating SSTable 6 during the streaming phase. This happens before anticompaction is able to split apart the repaired and unrepaired data:
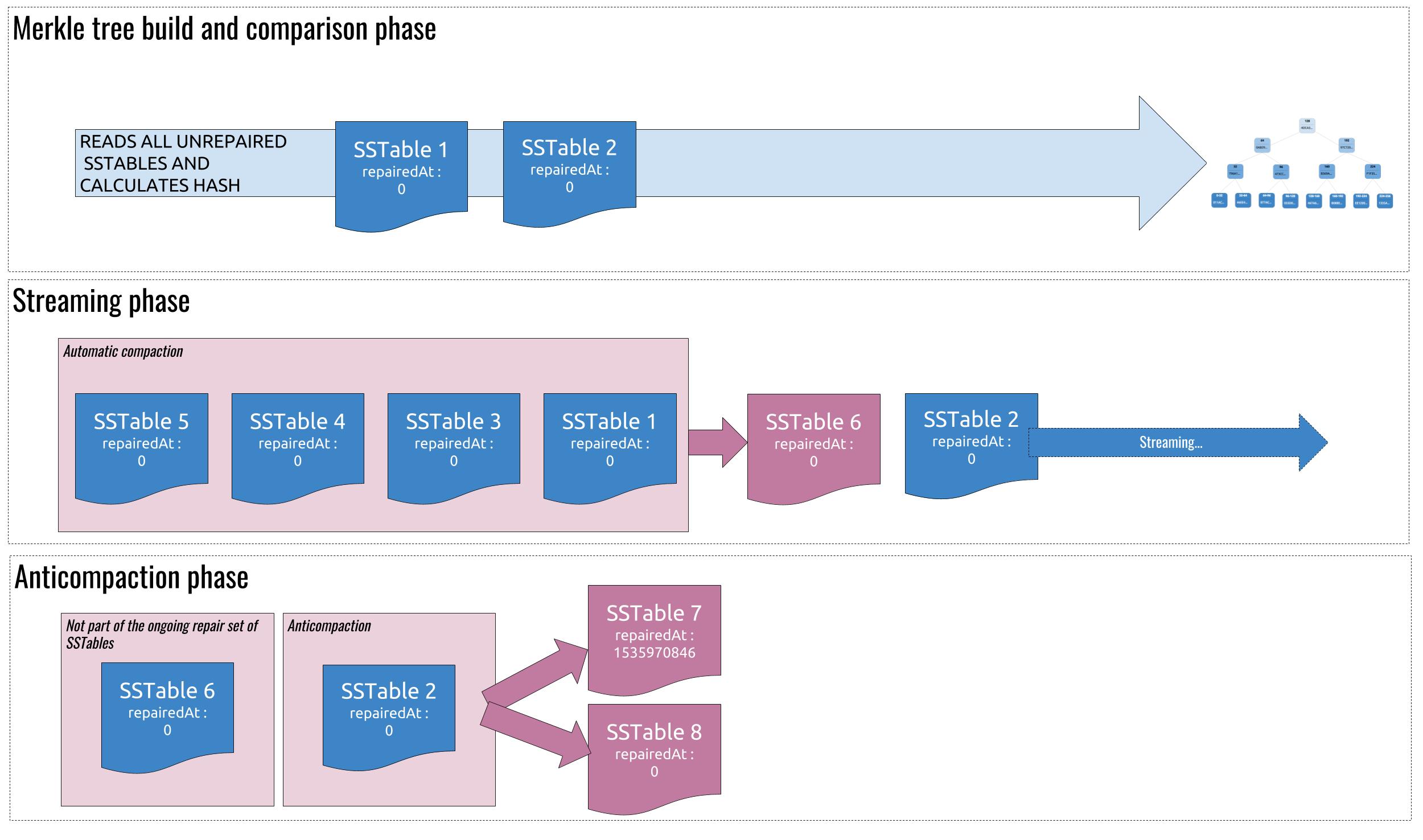
SSTable 1 gets compacted away before anticompaction could kick in.
If this happens on a single node, the next incremental repair run would find differences as the previously repaired data would be skipped on all replicas but one, which would lead potentially to a lot of overstreaming. This happens because Merkle trees only contain hashes of data, and in Cassandra, the height of the tree is bounded to prevent over allocation of memory. The more data we use to build our tree, the larger the tree would be. Limiting the height of the tree means the hashes in the leaves are responsible for bigger ranges of data.
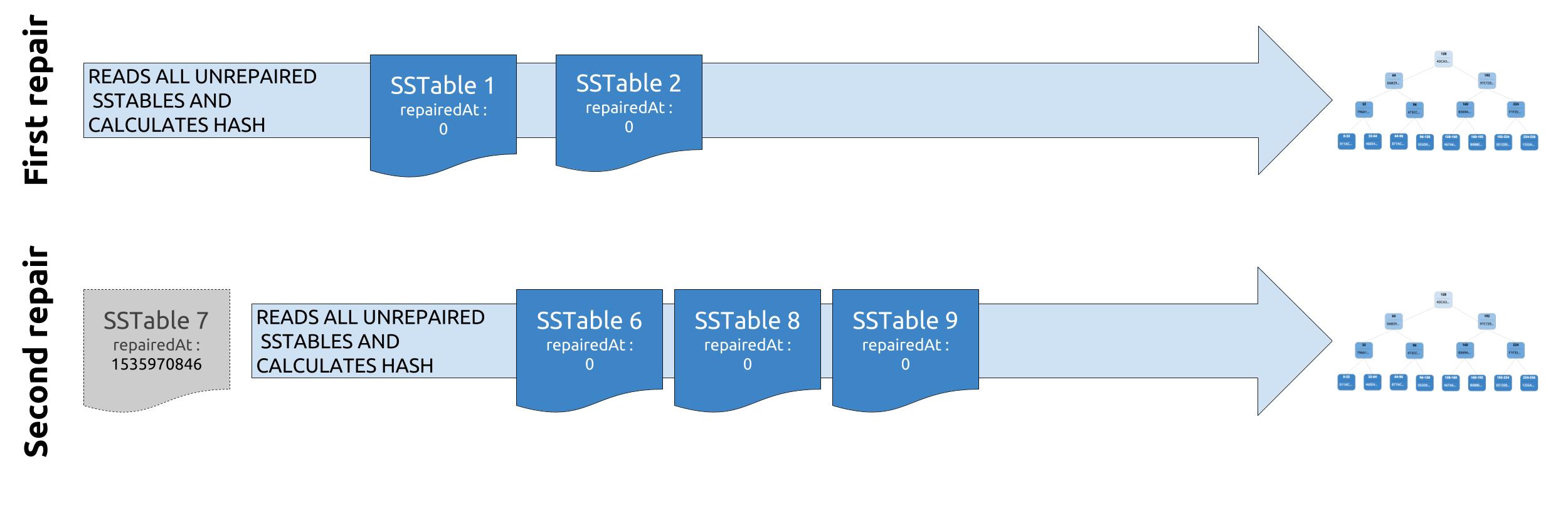
Already repaired data in SSTable 6 will be part of the Merkle tree computation.
If you wonder what troubles can be generated by this bug, I invite you to read my previous blog post on this topic.
Incremental repair in 4.0, the theory
The incremental repair process is now supervised by a transaction to guarantee its consistency. In the “Prepare phase”, anticompaction is performed before the Merkle trees are computed, and the candidate SSTables will be marked as pending a specific repair. note that they are not marked as repaired just yet to avoid inconsistencies in case the repair session fails.
If a candidate SSTable is currently part of a running compaction, Cassandra will try to cancel that compaction and wait up to a minute. If the compaction successfully stops within that time, the SSTable will be locked for future anticompaction, otherwise the whole prepare phase and the repair session will fail.
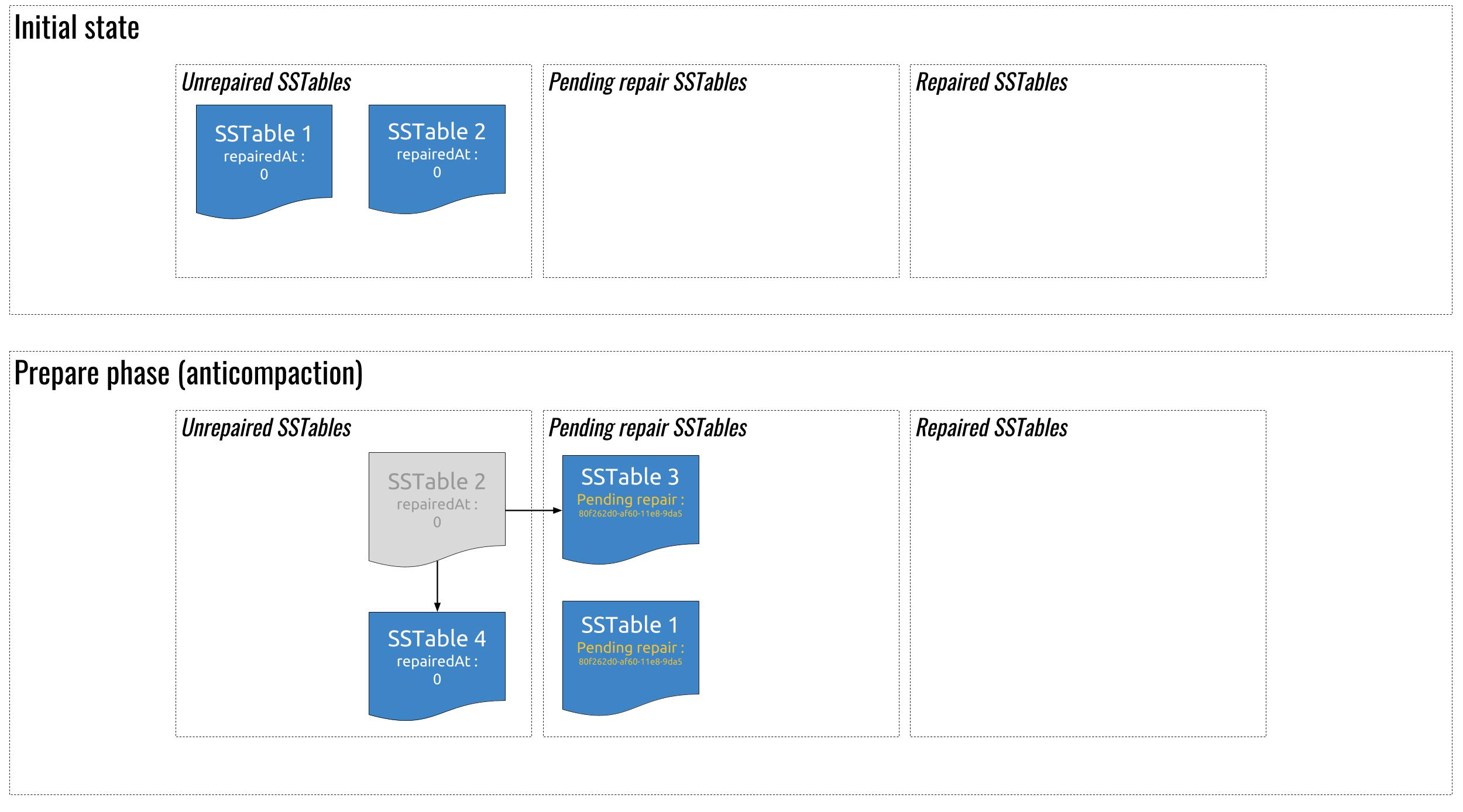
SSTables marked as pending repair are only eligible to be compacted with other tables marked as pending.
SSTables in the pending repair pool are the only ones participating in both Merkle tree computations and streaming operations :
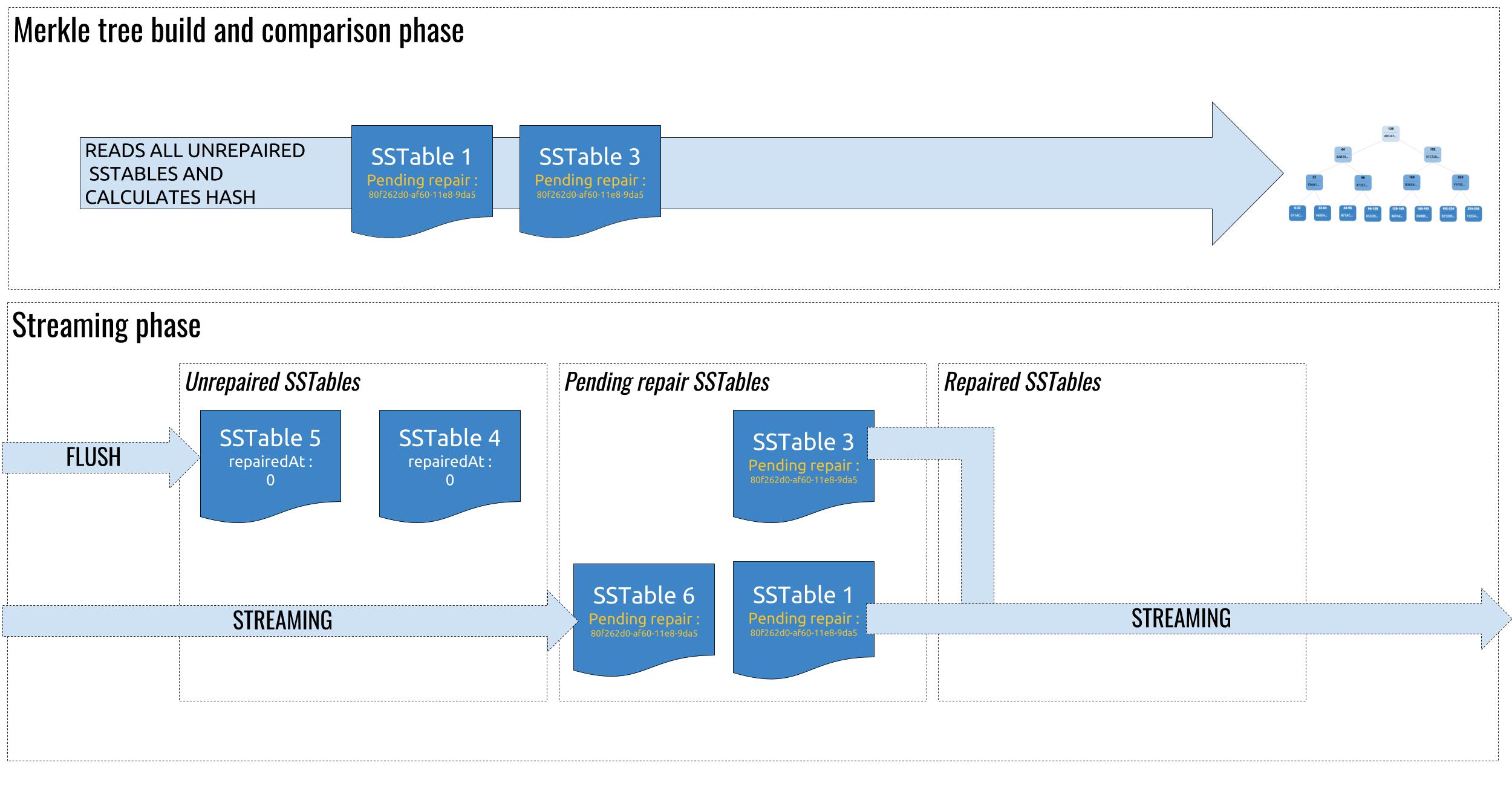
During repair, the pool of unrepaired SSTables receives newly flushed ones and compaction takes place as usual within it. SSTables that are being streamed in are part of the “pending repair” pool. This prevents two potential problems: If the streamed SSTables were put in the unrepaired pool, it could get compacted away as part of normal compaction tasks and would never be marked as repaired If the streamed SSTables were put in the repaired pool and the repair session failed, we would have data that is marked as repaired on some nodes and not others, which would generate overstreaming during the next repair
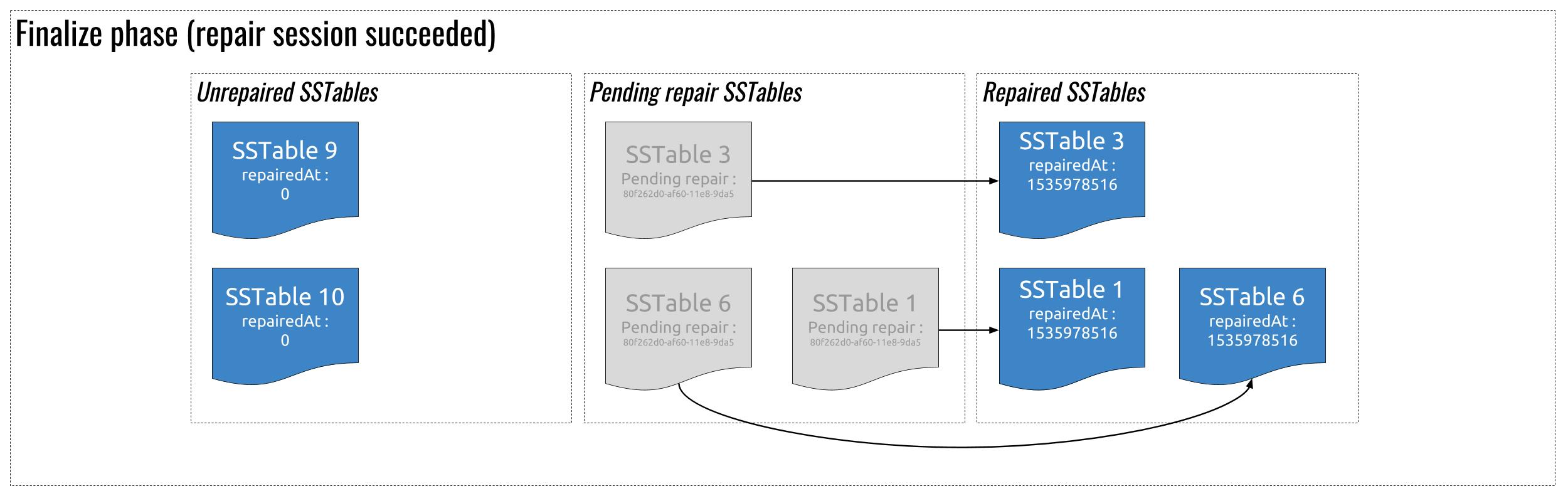
Once the repair succeeds, the coordinator sends a request to all replicas to mark the SSTables in pending state as repaired, by setting the RepairedAt timestamp (since anticompaction already took place, Cassandra just needs to set this timestamp).
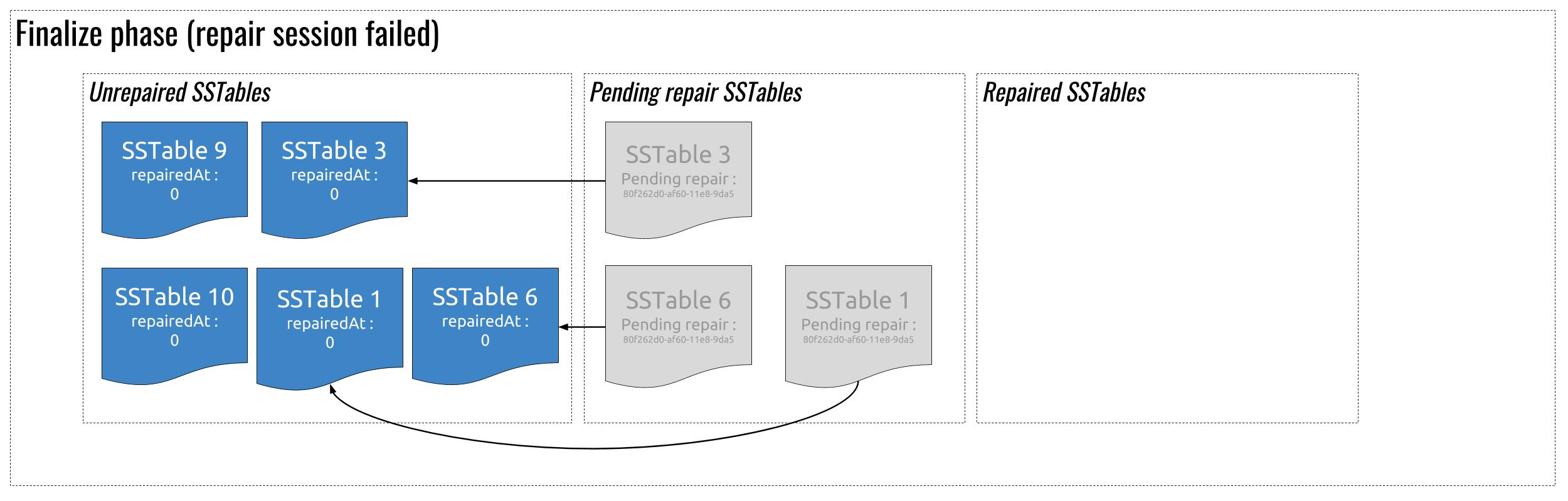
If some nodes failed during the repair, the “pending repair” SSTables will be released and eligible for compaction (and repair) again. They will not be marked as repaired :
The practice
Let’s see how all of this process takes place by running a repair and observing the behavior of Cassandra.
To that end, I created a 5 node CCM cluster running locally on my laptop and used tlp-stress to load some data with a replication factor of 2 :
bin/tlp-stress run BasicTimeSeries -i 1M -p 1M -t 2 --rate 5000 --replication "{'class':'SimpleStrategy', 'replication_factor':2}" --compaction "{'class': 'SizeTieredCompactionStrategy'}" --host 127.0.0.1
Node 127.0.0.1 was then stopped and I deleted all the SSTables from the tlp_stress.sensor_data table :
Datacenter: datacenter1
=======================
Status=Up/Down
|/ State=Normal/Leaving/Joining/Moving
-- Address Load Tokens Owns Host ID Rack
UN 127.0.0.1 247,07 KiB 1 ? dbccdd3e-f74a-4b7f-8cea-e8770bf995db rack1
UN 127.0.0.2 44,08 MiB 1 ? 3ce4cca5-da75-4ede-94b7-a37e01d2c725 rack1
UN 127.0.0.3 44,07 MiB 1 ? 3b9fd30d-80c2-4fa6-b324-eaecc4f9564c rack1
UN 127.0.0.4 43,98 MiB 1 ? f34af1cb-4862-45e5-95cd-c36404142b9c rack1
UN 127.0.0.5 44,05 MiB 1 ? a5add584-2e00-4adb-8949-716b7ef35925 rack1
I ran a major compaction on all nodes to easily observe the anticompactions. On node 127.0.0.2, we then have a single SSTable on disk :
sensor_data-f4b94700ad1d11e8981cd5d05c109484 adejanovski$ ls -lrt *Data*
-rw-r--r-- 1 adejanovski staff 41110587 31 aoû 15:09 na-4-big-Data.db
The sstablemetadata tool gives us interesting information about this file :
sstablemetadata na-4-big-Data.db
SSTable: /Users/adejanovski/.ccm/inc-repair-fix-2/node2/data0/tlp_stress/sensor_data-f4b94700ad1d11e8981cd5d05c109484/na-4-big
Partitioner: org.apache.cassandra.dht.Murmur3Partitioner
Bloom Filter FP chance: 0.01
Minimum timestamp: 1535720482962762 (08/31/2018 15:01:22)
Maximum timestamp: 1535720601312716 (08/31/2018 15:03:21)
SSTable min local deletion time: 2147483647 (no tombstones)
SSTable max local deletion time: 2147483647 (no tombstones)
Compressor: org.apache.cassandra.io.compress.LZ4Compressor
Compression ratio: 0.8694195642299255
TTL min: 0
TTL max: 0
First token: -9223352583900436183 (001.0.1824322)
Last token: 9223317557999414559 (001.1.2601952)
minClusteringValues: [3ca8ce0d-ad1e-11e8-80a6-91cbb8e39b05]
maxClusteringValues: [f61aabc1-ad1d-11e8-80a6-91cbb8e39b05]
Estimated droppable tombstones: 0.0
SSTable Level: 0
Repaired at: 0
Pending repair: --
Replay positions covered: {CommitLogPosition(segmentId=1535719935055, position=7307)=CommitLogPosition(segmentId=1535719935056, position=20131708)}
totalColumnsSet: 231168
totalRows: 231168
Estimated tombstone drop times:
Drop Time | Count (%) Histogram
Percentiles
50th 0
75th 0
95th 0
98th 0
99th 0
Min 0
Max 0
Partition Size:
Size (bytes) | Count (%) Histogram
179 (179 B) | 56330 ( 24) OOOOOOOOOOOOOOOOOOo
215 (215 B) | 78726 ( 34) OOOOOOOOOOOOOOOOOOOOOOOOOO.
258 (258 B) | 89550 ( 39) OOOOOOOOOOOOOOOOOOOOOOOOOOOOOO
310 (310 B) | 158 ( 0)
372 (372 B) | 1166 ( 0) .
446 (446 B) | 1691 ( 0) .
535 (535 B) | 225 ( 0)
642 (642 B) | 23 ( 0)
770 (770 B) | 1 ( 0)
Percentiles
50th 215 (215 B)
75th 258 (258 B)
95th 258 (258 B)
98th 258 (258 B)
99th 372 (372 B)
Min 150 (150 B)
Max 770 (770 B)
Column Count:
Columns | Count (%) Histogram
1 | 224606 ( 98) OOOOOOOOOOOOOOOOOOOOOOOOOOOOOO
2 | 3230 ( 1) .
3 | 34 ( 0)
Percentiles
50th 1
75th 1
95th 1
98th 1
99th 2
Min 0
Max 3
Estimated cardinality: 222877
EncodingStats minTTL: 0
EncodingStats minLocalDeletionTime: 1442880000 (09/22/2015 02:00:00)
EncodingStats minTimestamp: 1535720482962762 (08/31/2018 15:01:22)
KeyType: org.apache.cassandra.db.marshal.UTF8Type
ClusteringTypes: [org.apache.cassandra.db.marshal.ReversedType(org.apache.cassandra.db.marshal.TimeUUIDType)]
StaticColumns:
RegularColumns: data:org.apache.cassandra.db.marshal.UTF8Type
It is worth noting the cool improvements sstablemetadata has gone through in 4.0, especially regarding the histograms rendering. So far, and as expected, our SSTable is not repaired and it is not pending a running repair.
Once the repair starts, the coordinator node executes the Prepare phase and anticompaction is performed :
sensor_data-f4b94700ad1d11e8981cd5d05c109484 adejanovski$ ls -lrt *Data*
-rw-r--r-- 1 adejanovski staff 20939890 31 aoû 15:41 na-6-big-Data.db
-rw-r--r-- 1 adejanovski staff 20863325 31 aoû 15:41 na-7-big-Data.db
SSTable na-6-big is marked as pending our repair :
sstablemetadata na-6-big-Data.db
SSTable: /Users/adejanovski/.ccm/inc-repair-fix-2/node2/data0/tlp_stress/sensor_data-f4b94700ad1d11e8981cd5d05c109484/na-6-big
...
Repaired at: 0
Pending repair: 8e584410-ad23-11e8-ba2c-0feeb881768f
Replay positions covered: {CommitLogPosition(segmentId=1535719935055, position=7307)=CommitLogPosition(segmentId=1535719935056, position=21103491)}
na-7-big remains in the “unrepaired pool” (it contains tokens that are not being repaired in this session) :
sstablemetadata na-7-big-Data.db
SSTable: /Users/adejanovski/.ccm/inc-repair-fix-2/node2/data0/tlp_stress/sensor_data-f4b94700ad1d11e8981cd5d05c109484/na-7-big
Partitioner: org.apache.cassandra.dht.Murmur3Partitioner
Bloom Filter FP chance: 0.01
...
Repaired at: 0
Pending repair: --
Once repair finishes, another look at sstablemetadata on na-6-big shows us that it is now marked as repaired :
sstablemetadata na-6-big-Data.db
SSTable: /Users/adejanovski/.ccm/inc-repair-fix-2/node2/data0/tlp_stress/sensor_data-f4b94700ad1d11e8981cd5d05c109484/na-6-big
...
Estimated droppable tombstones: 0.0
SSTable Level: 0
Repaired at: 1535722885852 (08/31/2018 15:41:25)
Pending repair: --
…
Again, I really appreciate not having to compute the repair date by myself thanks to an sstablemetadata output that is a lot more readable than it was before.
Reliable incremental repair
While Apache Cassandra 4.0 is being stabilized and there are still a few bugs to hunt down, incremental repair finally received the fix it deserved to make it production ready for all situations.
The transaction that encloses the whole operation will shield Cassandra from inconsistencies and overstreaming, making cyclic repairs a fast and safe operation.
Orchestration is still needed though as SSTables cannot be part of 2 distinct repair sessions that would run at the same time, and it is advised to use a topology aware tool to perform the operation without hurdles.
It it worth noting that full repair in 4.0 doesn’t involve anticompaction anymore and does not mark SSTables as repaired. This will bring full repair back to its 2.1 behavior and allow to run it on several nodes at the same time without fearing conflicts between validation compactions and anticompactions.