Successfully reported this slideshow.
Cassandra + Spark + Elk

Upcoming SlideShare
Loading in …5
×
- 1. Cassandra+Spark+ELK Dmitriy Kalyada @ 2015
- 2. What is Spark? • Master: Driver program • Workers: Executors • High Availability • Standby Masters with ZooKeeper • Single-Node Recovery with Local File System
- 3. Under the hood • Resilient Distributed Dataset (RDD) • Scala + Akka Framework • Java, Scala, Python API • Spark SQL, MLib, Spark Streaming, GraphX
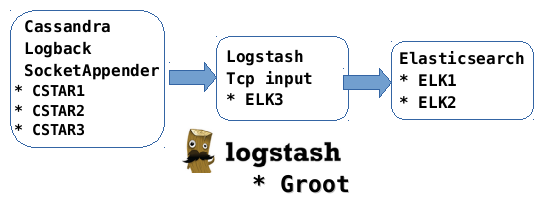
- 4. Our particular case Devices Cassandra Spark ELK
- 5. Data flow Fetcher Transformer Saver Input Source(s) x-RDD x-RDD Output Source
- 6. Spark Cassandra Connector • Represents Cassandra tables as Spark RDDs • Write Spark RDDs to Cassandra tables • Execute CQL queries in Spark applications https://github.com/datastax/spark-cassandra-connector
- 7. CassandraRDD settings • Connection params • Fetching params 1. input.split.size: C* partitions in a Spark Partition. 2. input.page.row.size: number of CQL rows fetched per roundtrip.
- 8. Fetching essentials … … … … -968391295277638458 … -893783532241185833 -968391295277638458, -893783532241185833 -7378580094811526501, -7340240117176401239 6426215139012569257, 6428979455828914106 -6094480671546553265, -6016282219056649738 -7259249675596554667, -7237838231745167324 -6734336817058726139, -6684208157211348972 -3891103372671105499, -3822513456325086923 4453206019575747361,4462441725813855391 7855385326468991461,7906589648045207141 -129433796439502583,-101280166181350027 -2233788032218452383,-2066644620711092198 3248662132571799756,3396129453515776704 7744134136205124749,7812918342246679728 -1408208314239486033,-1403736406052004344 • Support Murmur3Partitioner and RandomPartitioner • Retrieve token ranges from Cassandra • Prediction on base of 16 random token ranges
- 9. Data to RDD … Tokens Per RDD [input.split.size] Token Range #N Slurp amount [input.page.row.size]
- 10. Token range vs rows number
- 11. What to do? • Change read strategy • Split data on a smaller pieces • Increase cluster strength • Reorganize Cassandra schema
- 12. Elastic Search
- 13. Elastic Search & Kibana • Index initialization: TransportClient • Create/Delete Index • Setup Mappings • Indexing: ScalaEsRDD • Data presentation: Kibana
- 14. Kibana
- 15. Deployment • Build package: Spark Job + Dependent Jars + Configs • Upload to the Spark Master Node • Start job submit script
- 16. Thank you dkaliada@exadel.com Dmitriy Kalyada @ 2015
Public clipboards featuring this slide
No public clipboards found for this slide