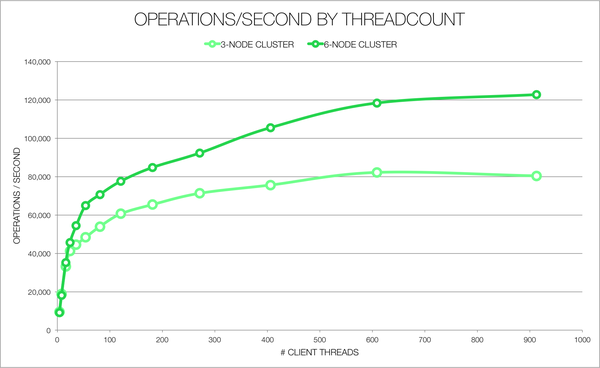
If you’re a frequent reader of our blog, you may have noticed we’ve been spending a lot of time looking at performance tuning. We’ve looked at tuning Compression, Garbage Collection, and how you can use Flame Graphs to better understand Cassandra’s internals. To do any sort of reasonable performance tuning you need to be able to apply workloads to test clusters. With Cassandra, that means either writing a custom tool to mimic your data model or using Cassandra stress to try to put load on a cluster.
Unfortunately, in the wise words of Alex Dejanovski, modeling real life workloads with cassandra-stress is hard. Writing a stress profile that gives useful results that can be very difficult, sometimes impossible. As Alex mentions in his post, cassandra-stress will do batches whether or not you’ve asked it to, and disabling that functionality is far from straightforward.
Outside of the world of Cassandra, I’ve done a fair bit of benchmarking and performance profiling. One of the tools I’ve been most impressed with is fio. The author, Jens Axboe, recognizes that when doing performance testing there’s a handful of patterns that come up frequently. With very little work, fio can be configured to benchmark reads, writes, mixed, and the operations can be random or sequential. The idea is that you start with a predefined idea of a job, and configure it via parameters to run the workload you’re interested in. Once you understand the tool, creating a new workload takes minutes, not hours, and is fairly straightforward. It can output the results as JSON, so when you’re done it’s easy to archive and process.
Benchmarking Cassandra is, of course, different than benchmarking a filesystem. Workloads vary significantly between applications, but ultimately we still see a lot of patterns. Time series and key value workloads are very common, for instance. We decided to create a stress tool that shipped with a variety of commonly run workloads, and allow the tool to tweak their behavior. If the desired workload could not be configured based on what we ship, it should be straightforward to create a new one.
Thus, tlp-stress was born.
tlp-stress is written in Kotlin, so it runs on the JVM. We make use of the Datastax Java Driver and make use of best practices to maximize query throughput. Metrics are tracked using the same instrumentation as the Java driver itself, which will make exporting them to tools like Prometheusa no brainer in the long run (see related issue). We chose Kotlin because it gives us access to stable Java libraries and runs on the JVM without a lot of the mental overhead of Java. We’ve used Kotlin internally for over a year at TLP and have found it to be as easy to write as Python while still providing static typing, great IDE support, while not giving up the libraries we rely on and know well.
There’s documentation for tlp-stress, which includes examples generated by the tool itself.
Let’s take a look at a practical example. Let’s say we’re looking to understand how Cassandra will perform when we’ve got a key-value style workload that’s 90% reads. This isn’t the usual use case people talk about a lot - usually we’re discussing optimizing Time Series and similar write heavy workloads.
We can put together this workload rather trivially.
Note: For demonstration purposes I’m only running 10 million operations - for real testing we’d want to set this up to run over several days.
We’ll fire up a test using the run subcommand, specifiying one of the available tests, this one is KeyValue. We’ll limit ourselves to 10,000 partition keys by specifiying -p 10k (note the human friendly inputs) 90% reads with -r .9 and specify the compaction option:
$ tlp-stress run KeyValue -n 10M -p 10k -r .9 --compaction "{'class':'LeveledCompactionStrategy'}"
Creating schema
Executing 10000000 operations
Connected
Creating tlp_stress:
CREATE KEYSPACE
IF NOT EXISTS tlp_stress
WITH replication = {'class': 'SimpleStrategy', 'replication_factor':3 }
Creating Tables
CREATE TABLE IF NOT EXISTS keyvalue (
key text PRIMARY KEY,
value text
) WITH compaction = {'class':'LeveledCompactionStrategy'}
Preparing queries
Initializing metrics
Connecting
Preparing
1 threads prepared.
Running
Writes Reads Errors
Count Latency (p99) 5min (req/s) | Count Latency (p99) 5min (req/s) | Count 5min (errors/s)
13415 15.61 0 | 122038 25.13 0 | 0 0
33941 15.02 5404.6 | 306897 16.6 48731.6 | 0 0
54414 15.56 5404.6 | 490757 24.15 48731.6 | 0 0
Note that we didn’t have to write a single query or a schema. That’s because tlp-stress includes common workloads and features out of the box. We can find out what those workloads are by running the list command:
$ tlp-stress list
Available Workloads:
BasicTimeSeries
Maps
CountersWide
MaterializedViews
KeyValue
LWT
Done.
What if we have a use case that this test is close to, but doesn’t match exactly? Perhaps we know our workload will be fairly heavy on each request,
The next thing we can do is customize the data in specific fields. Note the schema in the above table has a table called keyvalue, which has a value field. Let’s suppose our workload is caching larger blobs of data, maybe 100,000 - 150,000 characters per request. Not a problem, we can tweak the field.
$ tlp-stress run KeyValue -n 10M -p 10k -r .9 --compaction "{'class':'LeveledCompactionStrategy'}" --field.keyvalue.value='random(100000,150000)'
Creating schema
Executing 10000000 operations
Connected
Creating tlp_stress:
CREATE KEYSPACE
IF NOT EXISTS tlp_stress
WITH replication = {'class': 'SimpleStrategy', 'replication_factor':3 }
Creating Tables
CREATE TABLE IF NOT EXISTS keyvalue (
key text PRIMARY KEY,
value text
) WITH compaction = {'class':'LeveledCompactionStrategy'}
keyvalue.value, random(100000,150000)
Preparing queries
Initializing metrics
Connecting
Preparing
1 threads prepared.
Running
Writes Reads Errors
Count Latency (p99) 5min (req/s) | Count Latency (p99) 5min (req/s) | Count 5min (errors/s)
1450 43.75 0 | 13648 40.7 0 | 0 0
3100 35.29 512.8 | 28807 42.81 4733.8 | 0 0
4655 49.32 512.8 | 42809 44.25 4733.8 | 0 0
Note in the above example, --field.keyvalue.value corresponds to the keyvalue table and the value field, and we’re using random values between 100k-150k characters. We could have specified --field.keyvalue.value='cities()' to pick randomly from a cities of the world list, or --field.keyvalue.value='firstname()' to pick from a list of randomly supplied names. This feature is mostly undocumented and will be receiving some attention soon to make it a lot more useful than the current options, but you should be able to see where we’re going with this.
In addition to our stress tool we’ve also begun work on another tool, cleverly named tlp-cluster, to launch test clusters to aid in development and diagnostics. To be clear, this tool is in it’s early infancy and we don’t expect it to be used by the general Cassandra population. It isn’t a substitute for provisioning tools like Salt and Ansible. With that warning out of the way, if you’re interested in checking it out, we’ve put the project on GitHub and we’re working on some Documentation.
We’ll be building out these tools over the next few months to further help us understand existing Cassandra clusters as well as profile the latest and greatest features that get merged into trunk. By focusing our effort on what we know, tooling and profiling, our goal is to expose and share as much knowledge as possible. Check out the tlp-stress documentation, it’ll be the best source of information over time. Please let us know if you’re finding tlp-stress useful by giving us a shout on Twitter!