
Instaclustr recently announced coming availability of our Managed Service for Elassandra, which delivers Elasticsearch integrated with Apache Cassandra. This blog post drills down to explain the features and advantages of Elassandra – the best of Cassandra and ElasticSearch.
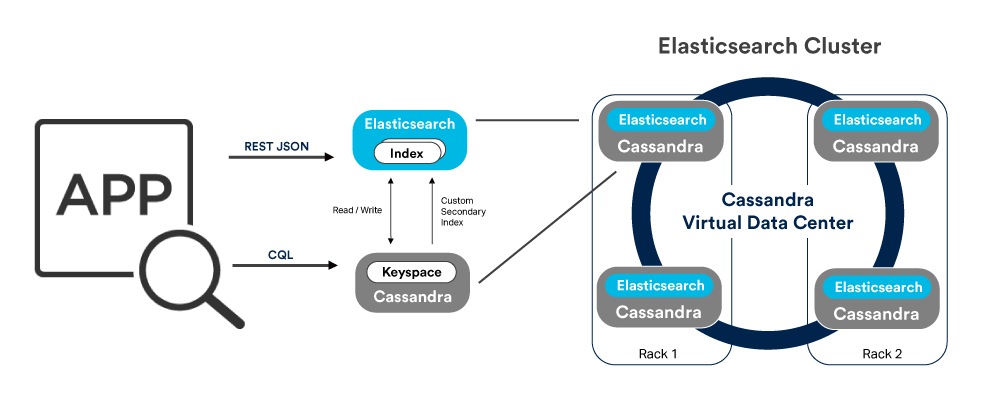
Elassandra adds the power of ElasticSearch’s fast, powerful indexing and querying to Cassandra. By embedding Elasticsearch into Cassandra’s resilient, distributed architecture, Elassandra delivers a solution which combines the functionality of both Cassandra and Elasticsearch in a single integrated solution with improved availability features and simpler management.
Here are some of the key features:
- Elassandra provides all the indexing and query capabilities of ElasticSearch. This includes incredibly fast indexing, querying and analysis of structured and semistructured data. It allows complex querying of large data sets. Real-time indexing allows data to become searchable as soon as it is inserted into the database.
- Powerful, flexible querying of Cassandra tables. By design, Cassandra supports a relatively simple range of query operations, generally limited to simple primary key or range lookups. Elassandra allows the full power of the Elasticsearch Query Language (Query DSL) to be used to search data in Cassandra tables, including the ability to produce compound statements comprising filter and query blocks and relevance score calculations.
- Elassandra is Cassandra. At its core, Elassandra is the same engine as Cassandra and therefore is automatically part of the Cassandra ecosystem. Tools and applications which work with Cassandra can be used with little or no change with Elassandra. This means that the same familiar tools (e.g. nodetool, cqlsh) are used to manage Elassandra, and operations such as repair and compaction are done in the usual way. Tools like Spark, Storm, Kafka and Zeppelin all work with Elassandra’s Cassandra API.
- Elassandra is Elasticsearch. Elassandra supports Elasticsearch’s RESTful API, and fits right into the Elassandra ecosystem. Tools like Kibana, Logstash, Beats, JDBC driver, Spark and Kafka all work with Elassandra’s Elasticsearch API.
- Flexible APIs. Data can be loaded in Elassandra through Cassandra’s CQL, or via ElasticSearch’s RESTful API. Regardless of which approach is used, Elassandra ensures that data is stored in a Cassandra table, and indexed in Elasticsearch. A wide variety of language bindings can be used to access these APIs. For CQL these include: Java, Python, Ruby, C#/.Net, Nodejs, PHP, C++, Closure, Scala, Clojure, Erlang, Go, Haskell & Rust, and for Elasticsearch: Java, JavaScript, Groovy, .NET, PHP, Perl, Python, Ruby and others many other via JSON/RESTful interface.
- Simplified data pipeline. A single Elassandra cluster can do the work of several components: a Cassandra cluster, an ElasticSearch cluster, and ETL processes to replicate and synchronise between clusters. Once transactional data is loaded into an Elassandra cluster, it can be searched directly without extra pipeline steps to load from Cassandra to Elassandra.
- Masterless Distributed Architecture. While standalone Elasticsearch has a master node, which introduces a single point of failure which must be carefully managed. By running Elasticsearch on Cassandra’s fully distributed, masterless distributed architecture, the single point of failure is eliminated.
- In Elassandra, Elasticsearch indexes are managed Cassandra as secondary indexes. Elassandra fully supports other Cassandra features including: Cluster Replication between data centres; integration with Cassandra backups; and Integration with Cassandra node add/remove functions.
- Provisioned in minutes, fully integrated, fully managed. With Instaclustr, you can have an Elassandra cluster provisioned in minutes, and managed and supported by Instaclustr. Optionally, your cluster can also be automatically fully configured and integrated with Zeppelin, Spark and Kibana, allowing you to quickly build and deploy your application.









