In this blog, we recap Cassandra Lunch #18, where we had guest speaker, Ryan Quey, discuss and demo a personal project where he uses multiple technologies, including Cassandra and Kafka, to build an app that grabs podcast data related to topics he inputs, stores it, processes it and displays it on searchable a front-end. In case you missed it, the video of Cassandra Lunch is also embedded in the blog!
Our guest speaker for Cassandra Lunch #18 is Ryan Quey. Ryan is a full-stack data engineer, who specializes in managing and manipulating data at scale and integrating that into apps, from front to back.
In Cassandra Lunch #18, Ryan discusses and demos a personal project he has been working on called java-podcast-processor. This is a tool to find podcast metadata over an external API, store them, get their RSS feeds, and run ETL using Airflow, Kafka, Spark, and Cassandra
The particular Cassandra distribution Ryan uses is Elassandra, which allows seamless integration with Elasticsearch.
The tool uses workers that are divided into separate Main classes in a single Java jar and consume and produce to Kafka, in order to distribute the workload across the cluster. He explains during Cassandra Lunch #18 that everything is built on top of Docker containers and linked together using docker-compose.
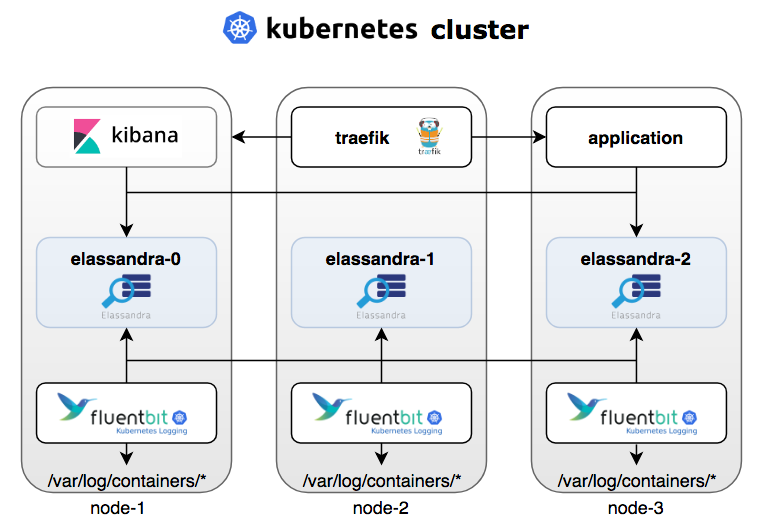
The flow of the tools is shown in the diagram below:

As shown above, there is a front-end and back-end component with React and Flask. Ryan demos the front-end aspect of the tool, which is the results displayed using a searchkit interface over React (built using Gatsby), served by a Python Flask app. The video is embedded at the end of the blog if you want to watch the demo live. A static example of the front-end can be seen below:

We would like to give thanks to Ryan for presenting today and discussing how he uses Cassandra for his java-podcast-processor project. The video of Cassandra Lunch #18 is embedded below; as well as, links to previous Cassandra Lunches if you missed any.
ICYMI
You can contact and/or follow Ryan Quey at the following places:
Cassandra.Link is a knowledge base that we created for all things Apache Cassandra. Our goal with Cassandra.Link was to not only fill the gap of Planet Cassandra, but to bring the Cassandra community together. Feel free to reach out if you wish to collaborate with us on this project in any capacity.
We are a technology company that specializes in building business platforms. If you have any questions about the tools discussed in this post or about any of our services, feel free to send us an email!