In Apache Cassandra Lunch #61, we will discuss different ways of indexing and working with Elassandra as well as showcasing a project I built utilizing Kafka with Elassandra. The live recording of Cassandra Lunch, which includes a more in-depth discussion and a demo, is embedded below in case you were not able to attend live. If you would like to attend Apache Cassandra Lunch live, it is hosted every Wednesday at 12 PM EST. Register here now!
Elassandra

Cross Datacenter Replication
Apache Cassandra supports asynchronous multi-datacenters replication and various mechanisms to repair lost data. By closely integrating Elasticsearch with Cassandra, Elassandra provides search features on many datacenters.
Scale On-Demand
When you need to increase read/write throughput, Elassandra automatically re-shards your Elasticsearch indices as new machines are added, allowing you to smoothly scale out to fit your business needs without downtime or heavy maintenance operations requirements.
Real-Time Analytics
By indexing Cassandra’s data into Elasticsearch, Kibana will allow you to get continuous and real-time data visualization of your applications.
A Masterless Architecture
By using a distributed transaction, Elassandra removes the single point of failure of Elasticsearch to manage its configuration.
A Reliable Primary Datastore
Cassandra is designed for write-intensive workloads, hence, making Elassandra suitable for applications where a large amount of data is to be inserted (such as infrastructure logging, IoT, or events). So, Elasticsearch indices can be rebuilt whenever needed using the Cassandra tables without the creation of data duplication.
Continuous Operations in the Cloud
Failover-based approaches do not truly achieve high availability as far as write operations are concerned. Thanks to its multi-master design, Elassandra is always available either when a server/container fails or restarts because of some maintenance operations.
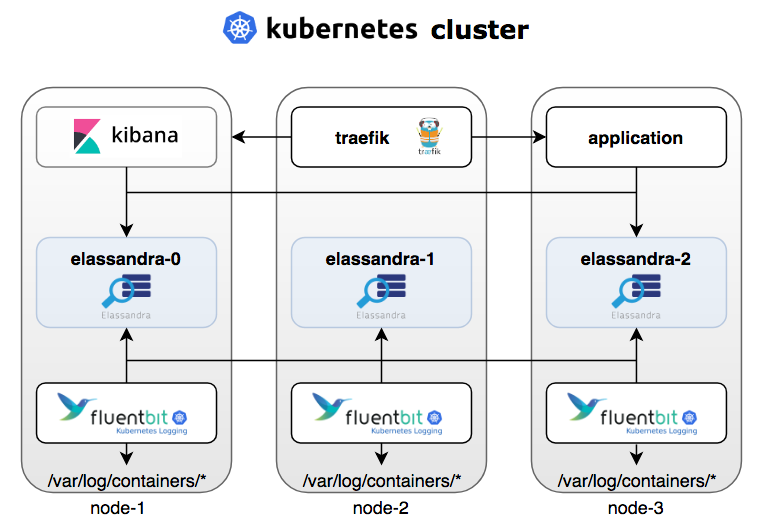
Elassandra Architecture
Elassandra closely integrates Elasticsearch within Apache Cassandra as a secondary index, allowing near-realtime search with all existing Elasticsearch APIs, plugins, and tools like Kibana. When you index a document, the JSON document is stored as a row in a Cassandra table and synchronously indexed in Elasticsearch.

Shards and Replicas
Unlike Elasticsearch, sharding depends on the number of nodes in the datacenter, and the number of replicas is defined by your keyspace Replication Factor. Elasticsearch number of shards is just information about the number of nodes.
- When adding a new Elassandra node, the Cassandra boostrap process gets some token ranges from the existing ring and pull the corresponding data. Pulled data is automatically indexed and each node update its routing table to distribute search requests according to the ring topology.
- When updating the Replication Factor, you will need to run a nodetool repair <keyspace> on the new node to effectively copy and index the data.
- If a node becomes unavailable, the routing table is updated on all nodes to route search requests on available nodes. The current default strategy routes search requests on primary token ranges’ owner first, then to replica nodes when available. If some token ranges become unreachable, the cluster status is in red, otherwise cluster status is in yellow.
Elassandra: Write path
Write operations (Elasticsearch index, update, delete and bulk operations) are converted into CQL write requests managed by the coordinator node. The Elasticsearch document _id is converted into an underlying primary key, and the corresponding row is stored on many nodes according to the Cassandra replication factor. Then, on each node hosting this row, an Elasticsearch document is indexed through a Cassandra custom secondary index. Every document includes a _token fields used when searching.

Elassandra: Search path
The search request is done in two phases. First, in the query phase, the coordinator node adds a token_ranges filter to the query and broadcasts a search request to all nodes. This token_ranges filter covers the entire Cassandra ring and avoids duplicating results. Secondly, in the fetch phases, the coordinator fetches the required fields by issuing a CQL request in the underlying Cassandra table and builds the final JSON response.

Cassandra.Link
Cassandra.Link is a knowledge base that we created for all things Apache Cassandra. Our goal with Cassandra.Link was to not only fill the gap of Planet Cassandra but to bring the Cassandra community together. Feel free to reach out if you wish to collaborate with us on this project in any capacity.
We are a technology company that specializes in building business platforms. If you have any questions about the tools discussed in this post or about any of our services, feel free to send us an email!