

Easy Cassandra scaling
With Terraform, Chef and Rundeck

When dealing with many Cassandra clusters, day-to-day operations can get complicated. At Teads, we like to eliminate toil as much as possible. In this article, we describe how we automate scaling operations on our AWS infrastructure using Terraform coupled with Chef and Rundeck.
Starting point
We are heavy Cassandra users, given our current infrastructure which includes 145 production nodes and performs up to one million queries per second.

C* is a central and critical piece of this infrastructure. We use it for a lot of things from storing tracking events to targeting data used to display the right ad to the right user. We use both C* 3.0 and C* 2.1.
One of the challenges we had operating our C* clusters was streamlining and simplifying day-to-day operations. In fact, even the most basic tasks required in-depth knowledge of the technology.
In early 2016, our processes relied a lot on manual operations with little automation (Capistrano, pssh, sed) so we had several needs in order to:
- Launch and operate a new region
- Reverse engineer existing regions
- Build a staging environment
- Improve staff turnover support
- Track infrastructure changes and revert them easily
Step 1: Cassandra configuration automation
The first step we took at that time was moving from Capistrano to Chef with adapted cookbooks and a custom wrapper.
It was a big win because we gained confidence in our infrastructure state. That said, when we needed to bootstrap or replace a node we still had to manually spawn an instance and then run a Rundeck job to install Chef client, etc. There was an obvious need for more automation.
Step 2: AMI creation
At this point we were still using a DataStax AMI based on Ubuntu 12.04 and wanted better control over the whole process. As we are extensive Debian users we decided to build our own AMIs with this distribution.
To do that, we chose Packer, a great tool from Hashicorp. Packer spawns a VM and then calls Chef to: install common software, create an AMI out of the instance and finally kill the VM.
A Jenkins job is used to build production or staging AMIs in different AWS regions.

Packer works well and even let us debug provisioning (we already had to): in this case each step has to be confirmed manually and then a SSH key is generated to log onto the spawned instance.
Step 3: Cluster creation automation (first attempt)
As we were already using Chef, we tried Chef provisioning to spawn one or several VMs based on our custom AMI.
At first, it was being used on a local workstation which was really handy. However, it strongly relied upon the laptop configuration launching it. Eventually, it became difficult to maintain and rather fragile. Another drawback to Chef provisioning is that it cannot spawn Spot instances that we wanted to use for testing purposes.
In the end, we realised we were still relying on a lot of manual operations and the process wasn’t ideal for teamwork.
Step 4: Cluster creation automation (rinse and repeat)
At that time we were evaluating Infrastructure-as-Code. We had mainly identified two solutions: Cloud Formation (via Troposphere) and Terraform.
Choosing the latter wasn’t totally rational at the time but Terraform looked sexier and seemed to have greater potential (open source and a fairly active community). Despite the fact that most of our infrastructure is on AWS, it was a plus to be able to describe cross vendor infrastructure into one unique repository.
Also, Terraform is about to become the standard for managing infrastructure. It enables high level of abstraction for describing resources and uses a highly declarative and easily readable language (HCL, Hashicorp Language).
Moving forward, we started by using it to launch a new AWS Region and quickly Terraformed most of our clusters.
Terraform lets us go much further than before and manage everything from VMs, identity and access management (IAM), network, DNS, managed RDBMS (RDS), alerting (Cloudwatch) to object storage (S3) and more. One of the great things about it is its ability to simulate the impacts of a modification (dry run using a plan command) before executing it for real.
Essentially, what we did with Terraform was industrializing around it. We defined pull requests processes, team reviews and ensured that Jenkins and only Jenkins can apply.
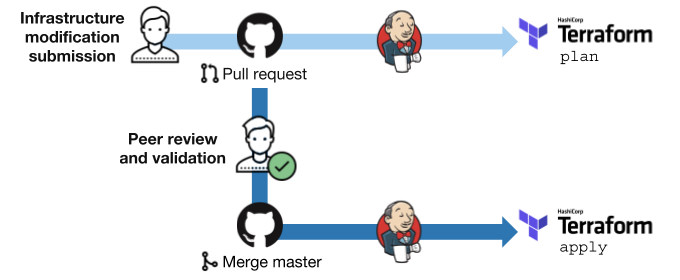
Step 5: Cluster operations automation
Scale Out
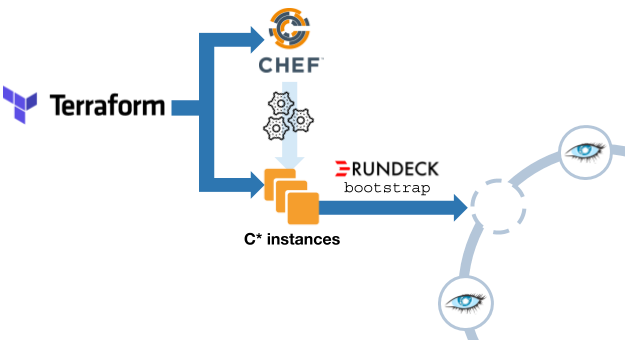
To bootstrap a new C* node we use Terraform and Chef provisioner (not to be mistaken for Chef provisioning mentioned in step 3).
Here is a Terraform rack definition example:
If we want to scale out, all we have to do is a pull request that modifies the number of nodes in a rack (+1 on node count):

Then we run a Terraform plan with Jenkins and paste the link of the console output in a pull request comment.
From an organisational standpoint, a mandatory review has to be done by a team member before merging. Then, we Terraform apply via Jenkins, it will still ask us if we want to proceed:

Once the VM is up, Terraform calls Chef using the dedicated plugin to provision the VM. It will install Cassandra, Datadog’s agent, some C* tools, etc.
We do not start Cassandra automatically since we want each node to be added sequentially.
However, we automatically verify that everything went fine using a bootstrap Rundeck job, checking that:
- RAID0 is correctly mounted
- the new node is located in the right datacenter
- the new node will be able to contact seed nodes
- ensure there are no existing Cassandra data
If all checks are OK, actual C* bootstrap is triggered. When bootstrapping starts we receive an alert on Slack, same goes once it’s finished so we know we can safely carry on with the next node.
Provisioning is now possible without mastering Cassandra. Tuning and troubleshooting still require our expertise, but in normal situations, these operations can be done by everybody in the team.
Scale In
In case of downscale, usually because of a bad node (noisy neighbor, hardware failure), basic alerting helps us identifying a suspicious instance. If proven faulty, we face two situations: A VM can be faulty but still accessible or otherwise totally inaccessible, usually when it’s due for retirement.
In the first scenario we use a decommissioning Rundeck job that will:
- make sure the node is located in the right datacenter
- pause after displaying its information so that we can kill it if we spot a mistake
The job also triggers an alert on Slack when starting and then when it’s done (whether it’s a success or not).
Once decommissioned, we manually kill the VM on AWS and then launch a Terraform apply. Terraform will identify the missing node and respawn a new one.
Replace
When totally inaccessible, we manually terminate the AWS instance from the console. We do not want to automate termination, the main reason being we have seen VMs pop back on after a few minutes.
Once terminated:
- we launch a Terraform apply that will provision a new node
- then we use a replace Rundeck job that will modify the cassandra-env.sh file accordingly and bootstrap the new node
Other Ops
We also leverage Rundeck features for other day-to-day operations like:
- Monitoring rolling restarts,
- Running nodetool commands,
- Applying schema migrations,
- Scheduling jobs for backups, major compactions on some specific tables, etc.
Main progress and feedback
Using Terraform, Chef provisioner, Packer and Rundeck we have greatly simplified and automated scaling operations. It also helped us build a complex yet trusted infrastructure. Having to precisely know which files to change before starting a new node is now a thing of the past and potential mistakes are checked.
But using Terraform to handle Kafka and Cassandra datastores in production wasn’t an easy decision. We carefully tested it in staging environment to make sure that it respawned the right instances (i.e. hostname and Terraform index) and we encourage everybody to do so.
We have always used the most recent Terraform version and have had surprises after some updates. For example, due to a regression of Chef provisioner we once couldn’t spawn Cassandra nodes anymore. To prevent this from happening again, we implemented a testing process for several use cases on staging environment with a Jenkins slave.
To wrap up, here are the key improvements we wouldn’t give up now:
- A unified Infrastructure as code in one repository, describing both our AWS and GCP resources.
- Explicit documentation and history that we couldn’t have using cloud consoles. Each commit contains actionable information, newcomers aren’t lost anymore when discovering our infrastructure (e.g. until recently security group IPs couldn’t be annotated).
- The ability to spawn entire clusters promptly and safely.
- An history of previous actions’ execution time, really useful to give ETAs.
Of course, we are continually looking for new enhancements to automate our way out of repeatable tasks.
As Cloud instances are not all equal, we would like to automatically select a good one when we spawn a new node. By benchmarking several of them we should be able to identify instances that are soon to be retired or prone to performance issues and only pick the best one.
If you find these kind of challenges exiting, please reach out, we would be happy to talk about it.
In the meantime here is a couple of other articles from Teads’ Infrastructure team:






