#Introduction
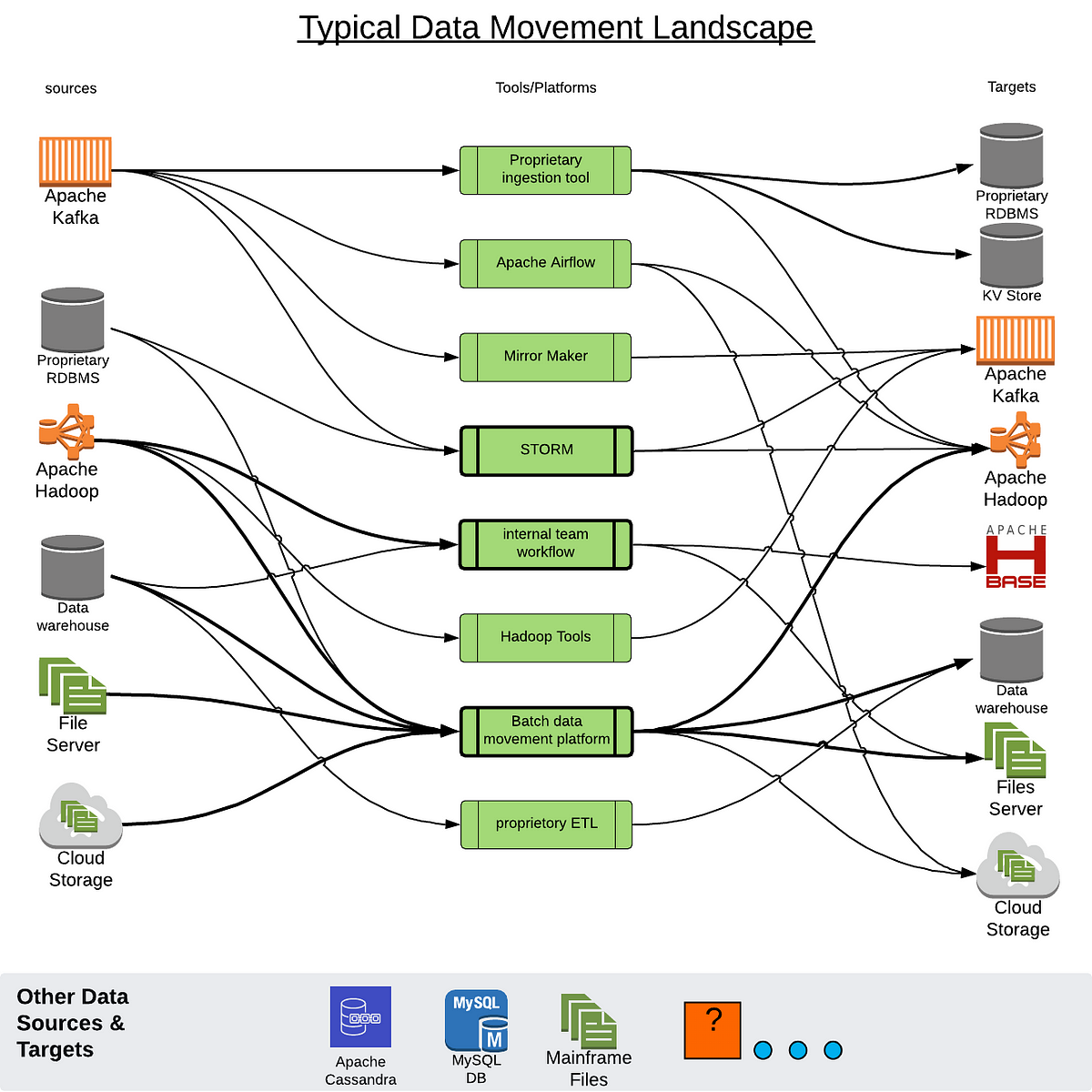
The goal of this Exercise is to learn how to access data in HDFS via Spark in DSE 4.6.
A simple scenario we want to address is loading data from files in HDFS in an
external Hadoop system into Cassandra. Spark is well-situated to help.
Moreover, Spark enables "blending" of data between HDFS and Cassandra.
For example, we can Join data between the two sources.
#Resources
This exercise will use DSE 4.6 and the integrated Spark that comes with it.
For HDFS, we will use the Hortonworks HDP 2.2 Sandbox, which can be downloaded from http://hortonworks.com/products/hortonworks-sandbox/
We will use Webhdfs to access HDFS in the Hadoop cluster. Webhdfs is a REST API for HDFS. I avoids some of the issues related to having the same HDFS libraries on both the client and the server.
You will need to clone this repo.