…using Apache Airflow scheduler and Apache Gobblin — a data integration framework open-sourced by LinkedIn.
As PayPal grows beyond 300 million users, we generate lots of data, both on our online (site) and offline (analytics) storage platforms. Data movement among those systems plays a critical role in enabling many of PayPal’s business use cases.
PayPal hosts a large installation of Hadoop and other analytics systems, holding hundreds of petabytes of data.
PayPal is one of the few companies in the software industry where almost every major type of storage system is used, from traditional RDBMS systems like MySQL to analytics platforms like Hadoop and other specialized data stores like Aerospike, Elasticsearch, and Kafka.
Data that moves is alive and valuable. At rest, data is dead.
Data constantly needs to move around and get processed, analyzed, and organized to realize its value. Moreover, the data producers and data consumers are not always in the same org. while producers optimize to write, consumers look to optimize to read. This inherently creates a challenge to enable data-driven decisions at a rapid pace. The data when created is tiny yet very critical, but when it's the time to read/analyze it, it usually becomes a big data problem. This dichotomy in the data world is bridged by data movement platforms and teams.
A decade ago, data movement at PayPal was seen as an operations problem where system admins or platform service providers built tools and utilities to facilitate data movement in and out of the systems. This blog on the Evolution of data movement platforms provides a good glimpse of how data movement system evolved and where it’s headed.
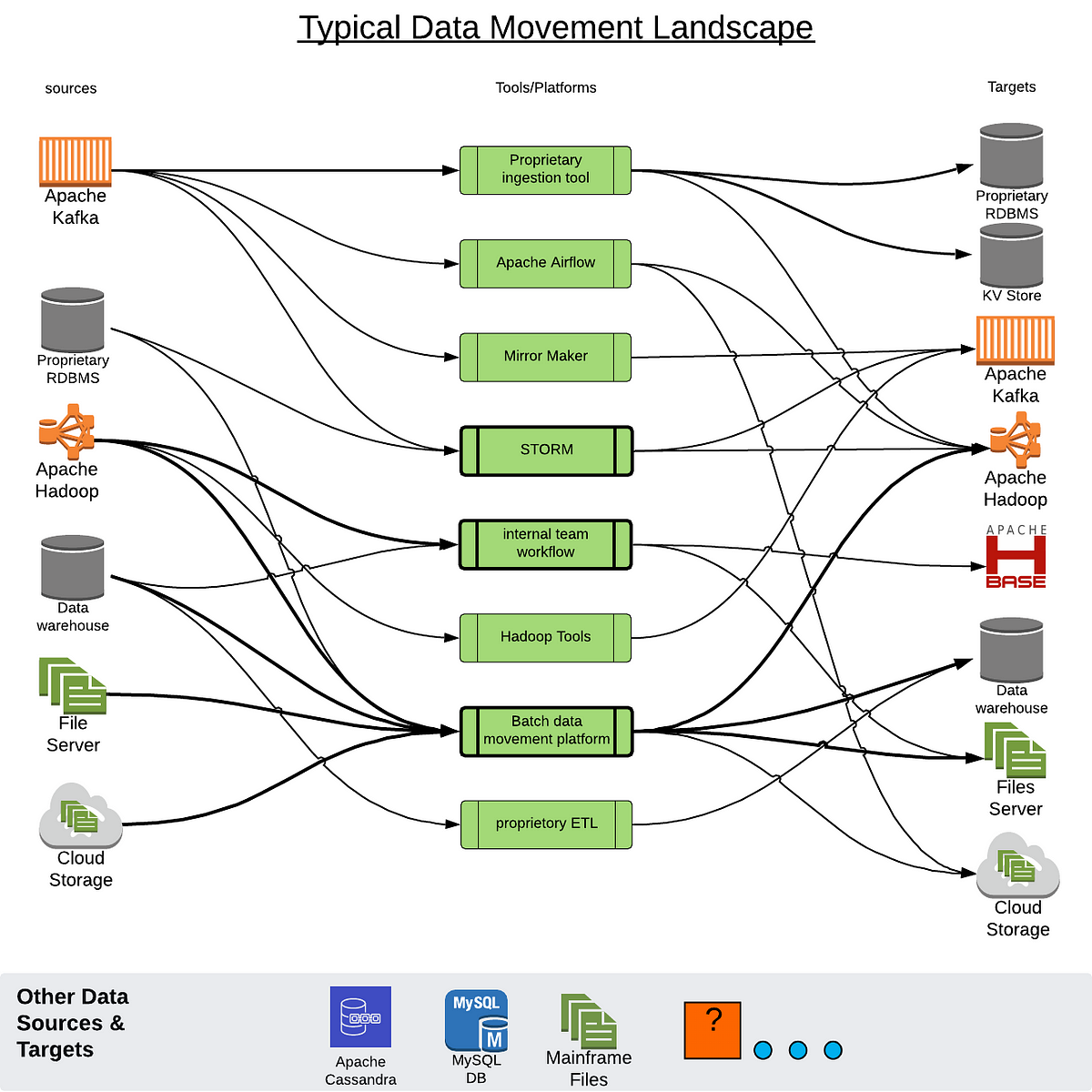
At Paypal, due to many legacies and one-off pointed data movement solutions, we ended up having a complex and unmanageable eco-system which added to the run-the-business (RTB) cost. Moreover, supporting new sources and targets costs more and hinders quick solutions for new business initiatives. We needed a data movement platform that can scale and cover a wide variety of storage ecosystems. The following diagram roughly depicts what we ended up with:
No product roadmap plans for this :) and yet it inevitably happened as part of our growth journey.
Also, as the amount of data being produced increased and consumers demanded more and more real-time experiences, we needed a much faster (i.e. throughput-wise), efficient, and reliable data movement platform to serve the downstream business use cases. So we embarked on the journey to build our Next-Generation of Data Movement Platform for PayPal.
“If a solution is built for the most complex scenario, consider it built for the easier ones” — Enterprise data platform leadership.
RADD — The Risk Analytical Dynamic Datasets pipeline is one of the most challenging and business-critical use-cases that enable the PayPal risk platform to make decisions on payment transactions. This was a perfect candidate to be proven on a new platform.
RADD data flow requirements:
For us, building on top of open-source technology fits with our belief of “don't reinvent the wheel”, and “contribute back to the community”. So when we evaluated many OSS frameworks, based on our requirements and proof-of-concept results, we felt that Apache Gobblin offers the most features, and provides flexibility and space for us to build our next-gen data movement platform.
An enterprise data movement platform requires many more components than just a reader and writer. The following diagram shows what we built and how it interacts to provide an end-to-end solution at a high level.
- Onboarding Service is a set of REST APIs built using PayPal’s internal Java spring framework (we call it Raptor). The onboarding service orchestrates the data pipeline. It interacts with various other services like schema reg., Gobblin, and Airflow APIs to create an end-to-end data pipeline. An onboarding API call results in a DAG and deploying configs on Airflow for executions. The DAG can be triggered based on the chosen mechanism at onboarding time, like an upstream handshake, cron-based interval, or ad-hoc. During every run, DAG also fetches metadata to operate based on the latest changes. A set of APIs to manage data pipeline lifecycles is also provided. Here is what the swagger spec looks like.
- DAG Service: The DAG service can create Airflow DAGs as per the requested configurations and template. Since Airflow does not provide a stable API interface to manage the Airflow DAGs, we built our own as part of this service. The DAG it builds is primarily responsible for incorporating all the application-specific logic: allowed deviation per dataset, type of movement (ad-hoc or rollback), etc. Once the DAG is deployed, Airflow does the execution.
- Apache Airflow: Airflow is a well-known workflow management and executor platform. We use Airflow to define and execute the data pipeline DAG. Airflow provides a runtime orchestration layer for end-to-end movement. This also provides the ability to embed data processing and handshaking capabilities, and easier operational management for the data pipeline. Here is how the DAG looks like for one of the datasets.
- Apache Gobblin is a highly scalable and distributed data integration framework that simplifies common aspects of data movement and integration and can support both streaming and batch movements. We use it as a core data mover component, controlled and managed by Airflow. To achieve this architecture, we developed new components within Gobblin for better service integration — job server to start/stop jobs from Airflow and CRUD APIs to manage jobs by the onboarding service, job metadata persistence over MySQL for better job management, SignalFX integration, etc. These new additions make Apache Gobblin more generic for enterprise use-cases that we also plan to contribute back (ref: Gobblin Improvement Proposal 4).
With security being a top priority at PayPal, all platform components communicate via HTTPs (over TLS 1.x) and keep data encrypted at rest. This blog on Secure & encrypted data movement across security zones talks about how we achieved it.
Overall, there are many components engaged here to form an end-to-end solution and things can quickly get complex if we don't define clear roles, responsibility, and design principles. There are many architectural principles we followed but one that really works for us is the following set of guidelines. These made implementation very clear for developers to expedite delivery while minimizing complexity:
- Each component acts as a micro-service that interacts over REST APIs, operating as a service provider.
- Each component operates on the latest configuration at runtime.
- Each component’s responsibilities are clearly defined with boundaries. Airflow does not make any data-movement-specific decisions. Gobblin does not have any visibility into why it moved the data; it simply does it when asked by Airflow.
- Metadata is centralized and changes are directly visible to all components.
- All components provide visibility via metric store integration (InfluxDB).
- All components should support rolling deployments to incur zero downtime while deploying changes.
The journey for #OnePlatform4PYPL has been started and we are going to keep solidifying and contributing to the open-source platform. Next in a bucket is to support PayPal’s cloud journey… Exciting!.