
Integrating Astra and Beam/Dataflow
Astra allows both bulk and real time operations through AstraDB and Astra Streaming. For each service there are multiple interfaces available and integration with Apache Beam/Google Dataflow is possible in different ways. Some of the design choices for this integration are below:

Data Bulk Operations
The Astra service which handles massive amount of data is Astra DB. It provides multiples ways to load data but some methods are preferred over others.
-
Cassandra and CQL: This is the way to go. It is the most mature and provides an efficient way to execute queries. With the native drivers you can run reactive queries and token range queries to distribute the load across the nodes. This is the approach that was taken with the originalCassandraIOconnector. The existingCassandraIOconnector does not support Astra but we leveraged it to create a newAstraIOconnector. -
CQL over REST: This interface can be use with any HTTP client. While the Astra SDKs provides a built-in client, this interface is not the best for bulk loading as it introduces an extra layer of serialization. -
CQL over GraphQL: This interface can be used with any HTTP Client. While the Astra SDKs provides a built-in client, this interface is not the best for bulk loading as it introduces an extra layer of serialization. -
CQL over GRPC: This interface is stateless, with an optimized serialization component (grpc), and reactive interfaces so it is a viable option. Currently, the operations exposed are CQL and the token metadata information is not available to perform range queries.
Data Streaming Operations
The Astra service to handle streaming data is Astra Streaming. It provides multiple interfaces like JMS, RabbitMQ, Kafka, and built-in Apache Beam support is available in standard connectors.
To leverage the split capabilities of Pulsar, a PulsarIO connector was released in 2022. To learn more about its development you can follow this video from the Beam Summit 2022.
Apache Beam
1. Overview
Introduction to Apache Beam
![]()
Objectives
Apache Beam is an open-source, unified programming model for batch and streaming data processing pipelines that simplifies large-scale data processing dynamics. Thousands of organizations around the world choose Apache Beam due to its unique data processing features, proven scale, and powerful yet extensible capabilities.
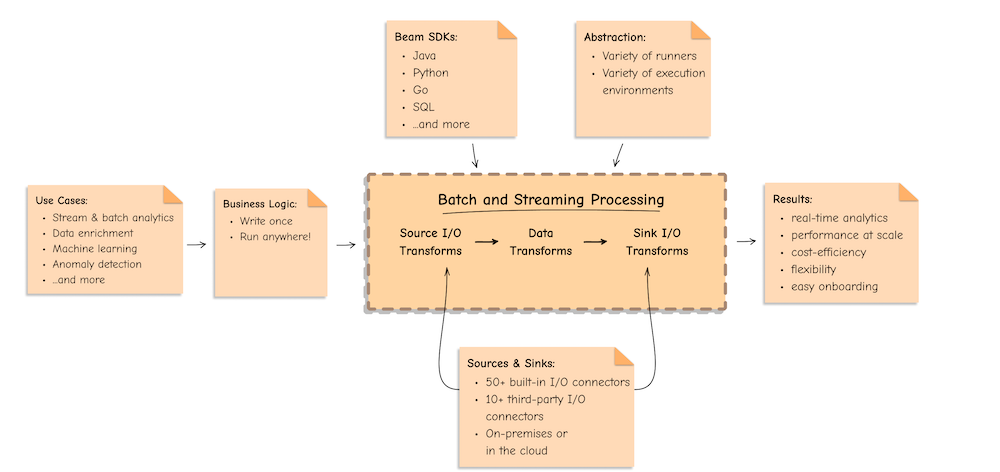
Main Concepts
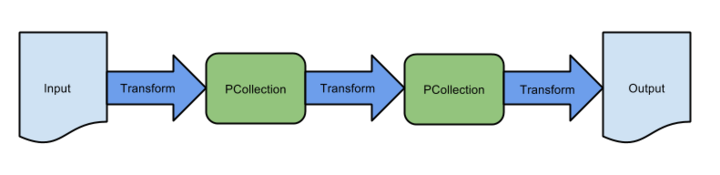
-
Pipeline: APipelineencapsulates your entire data processing task, from start to finish. This includes reading input data, transforming that data, and writing output data. All Beam driver programs must create a Pipeline. When you create the Pipeline, you must also specify the execution options that tell the Pipeline where and how to run. -
PCollection: APCollectionrepresents a distributed data set that your Beam pipeline operates on. The data set can be bounded, meaning it comes from a fixed source like a file, or unbounded, meaning it comes from a continuously updating source via a subscription or other mechanisms. Your pipeline typically creates an initial PCollection by reading data from an external data source, but you can also create a PCollection from in-memory data within your driver program. From there, PCollections are the inputs and outputs for each step in your pipeline. -
PTransform: APTransformrepresents a data processing operation, or a step, in your pipeline. Every PTransform takes one or more PCollection objects as input, performs a processing function that you provide on the elements of that PCollection, and produces zero or more output PCollection objects. -
Input and Output so called
I/O transforms: Beam comes with a number of “IOs” - library PTransforms that read or write data to various external storage systems.
I/O Connectors
Apache Beam I/O connectors provide read and write transforms for the most popular data storage systems so that Beam users can benefit from natively optimised connectivity. With the available I/Os, Apache Beam pipelines can read and write data to and from an external storage type in a unified and distributed way.
Integration with DataStax Astra is inspired by the built-in
CassandraIOandPulsarIOconnectors. This integration leverages a newAstraIOconnector.
Runners
A runner in Apache Beam is responsible for executing pipelines on a particular processing engine or framework, such as Apache Flink or Google Cloud Dataflow. The runner translates the Beam pipeline into the appropriate format for the underlying engine, manages job execution, and provides feedback on job progress and status.

2. Prerequisites
Setup your JAVA Development environment
Use java reference documentation targetting your operating system to install a Java Development Kit. You can then validate your installation with the following command.
java--version
Samples and tutorials have been designed with Apache Maven. Use the reference documentation top install maven validate your installation with
mvn-version
Setup Datastax Astra DB
An astra token acts as your credentials, it holds the different permissions. The scope of a token is the whole organization (tenant) but permissions can be edited to limit usage to a single database.
To create a token, please follow this guide
The Token is in fact three separate strings: a Client ID, a Client Secret and the token proper. You will need some of these strings to access the database, depending on the type of access you plan. Although the Client ID, strictly speaking, is not a secret, you should regard this whole object as a secret and make sure not to share it inadvertently (e.g. committing it to a Git repository) as it grants access to your databases.
{
"ClientId":"ROkiiDZdvPOvHRSgoZtyAapp",
"ClientSecret":"fakedfaked",
"Token":"AstraCS:fake"
}
It is handy to have your token declare as an environment variable (replace with proper value):
export ASTRA_TOKEN="AstraCS:replace_me"
With your account you can run multiple databases, a Databases is an Apache Cassandra cluster. It can live in one or multiple regions (dc). In each Database you can have multiple keyspaces. In the page we will use the database name db_demo and the keyspace keyspace_demo.
You can create the DB using the user interface and here is a tutorial. You can also use Astra command line interface. To install and setup the CLI run the following:
curl -Ls "https://dtsx.io/get-astra-cli" | bash
source ~/.astra/cli/astra-init.sh
astra setup --token ${ASTRA_TOKEN}
To create DB and keyspace with the CLI:
astra db create db_demo -k keyspace_demo --if-not-exists
A Secure Connect Bundle contains the certificates and endpoints informations to open a mTLS connection. Often mentionned as scb its scope is a database AND a region. If your database is deployed on multiple regions you will have to download the bundle for each one and initiate the connection accordingly. Instructions to download Secure Connect Bundle are here
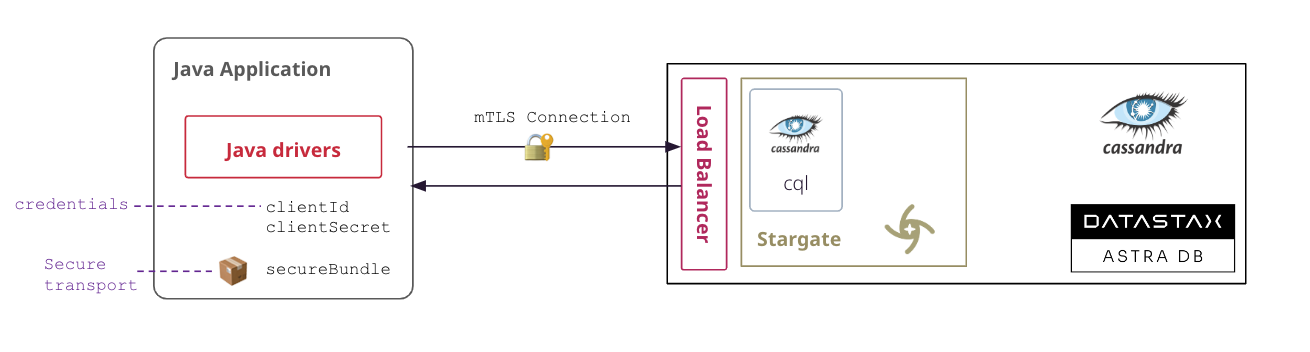
You can download the secure connect bundle from the user interface and here is a tutorial. You can also use Astra command line interface.
astra db download-scb db_demo -f /tmp/secure-connect-bundle-db-demo.zip
3. Installation and Setup
Setup the maven project locally
git clone https://github.com/DataStax-Examples/astra-dataflow-starter.git
cd astra-dataflow-starter
mvn clean install -Dmaven.test.skip=true
- In this page multiple flows will be described and this is how the project is defined:

4. Bulk Data Load
Description of Pipeline BulkDataLoadWithBeam.
In this pipeline, 100 records are generated randomly to populate a table simpledata in AstraDB. The simpledata table looks like the following:
CREATETABLEsimpledata(
idintPRIMARYKEY,
datatext
);
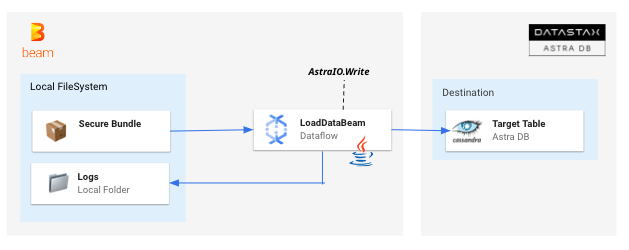
Implementation of Pipeline BulkDataLoadWithBeam
- The pipeline requires 3 arguments:
| Parameter Name | Description |
|---|---|
token |
Credentials to connect to the Astra platform, it should start with AstraCS:... |
secureConnectBundle |
Zip containing certificates to open a secured connection and endpoint definition to pick the proper database |
keyspace |
Target keyspace in Astra DB |
- Parameters are defined in a specialized interface
LoadDataPipelineOptionsinheriting fromPipelineOptions
/**
* Interface definition of parameters needed for this pipeline
*/
publicinterface LoadDataPipelineOptionsextendsPipelineOptions{
@Description("The Zip file to secure the transport (secure connect bundle)")
@Validation.Required
StringgetSecureConnectBundle();
voidsetSecureConnectBundle(Stringpath);
@Description("The token used as credentials (Astra Token)")
@Validation.Required
StringgetToken();
voidsetToken(Stringtoken);
@Description("Target Keyspace in the database")
@Validation.Required
StringgetKeyspace();
voidsetKeyspace(Stringkeyspace);
}
- Parameters are marshalled all the time with a
PipelineOptionsFactory.fromArgs(args).
LoadDataPipelineOptionsastraOptions=PipelineOptionsFactory
.fromArgs(args)
.withValidation()
.as(LoadDataPipelineOptions.class);
FileSystems.setDefaultPipelineOptions(astraOptions);
- Run the pipeline
// Create a pipeline with the options
PipelinepipelineWrite=Pipeline.create(astraOptions);
pipelineWrite
// Create 100 records randomly
.apply(Create.of(AstraIOTestUtils.generateTestData(100)))
// Create the target table
.apply(newCreateTableTransform<SimpleDataEntity>(astraOptions))
// Write data in tables
.apply(AstraIO.<SimpleDataEntity>write()
.withToken(astraOptions.getToken())
.withKeyspace(astraOptions.getKeyspace())
.withSecureConnectBundle(newFile(astraOptions.getSecureConnectBundle()))
.withEntity(SimpleDataEntity.class));
// Pipeline Execution
pipelineWrite.run().waitUntilFinish();
Executing the Pipeline BulkDataLoadWithBeam.
cd samples-astra-beam-pipelines
export ASTRA_KEYSPACE=demo
export ASTRA_SCB_PATH=/tmp/scb-demo.zip
export ASTRA_TOKEN=AstraCS:uZclXTY....
mvn -Pdirect-runner compile \
exec:java \
-Dexec.mainClass=com.dtx.astra.pipelines.beam.BulkDataLoadWithBeam \
-Dexec.args="\
--keyspace=${ASTRA_KEYSPACE} \
--secureConnectBundle=${ASTRA_SCB_PATH} \
--token=${ASTRA_TOKEN}"
5. Bulk Data Export
Description of Pipeline BulkDataExportWithBeam
In this pipeline, the contents of an Astra table are exported as set of CSV files. The read is split in token ranges for maximum performance (reads are distributed accross the nodes). Multiple files are produced in the output directory.
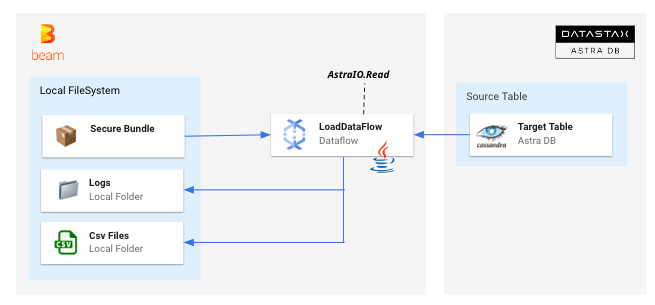
Implementation of Pipeline BulkDataExportWithBeam
- The pipeline requires 5 arguments:
| Parameter Name | Description |
|---|---|
token |
Credentials to connect to the Astra platform, it should sart with AstraCS:... |
secureConnectBundle |
Zip containing certificates to open a secured connection and endpoint definition to pick the proper database |
keyspace |
Target keyspace in Astra DB |
table |
The table name to be exported |
targetFolder |
Destination for the files on disk |
- Those parameters are parsed using a specialized
PipelineOptionsinterface:
publicinterface ExportTablePipelineOptionsextendsPipelineOptions{
@Description("AstraToken Value")
@Validation.Required
ValueProvider<String>getAstraToken();
voidsetAstraToken(ValueProvider<String>token);
@Description("Location of fie on disk")
@Validation.Required
ValueProvider<String>getSecureConnectBundle();
voidsetSecureConnectBundle(ValueProvider<String>path);
@Description("Source Keyspace")
@Validation.Required
StringgetKeyspace();
voidsetKeyspace(Stringkeyspace);
@Description("Source Table")
StringgetTable();
voidsetTable(Stringtable);
@Description("Destination folder")
@Validation.Required
StringgetTargetFolder();
voidsetTargetFolder(Stringfolder);
}
- Items are read with a
AstraIO.read()as an entity, then serialized as a String
@ProcessElement
publicvoidprocessElement(ProcessContextc){
StringcsvLine=c.element().getId()+";"+c.element().getData();
LOGGER.info("CSV Line: {}",csvLine);
c.output(csvLine);
}
- Run the pipeline
// Build Read
PipelineexportCsvPipeline=Pipeline.create(options);
exportCsvPipeline
.apply("Read Table",AstraIO
.<SimpleDataEntity>read()
.withToken(options.getAstraToken().get())
.withSecureConnectBundle(newFile(options.getSecureConnectBundle().get()))
.withKeyspace(options.getKeyspace())
.withTable(options.getTable())
.withCoder(SerializableCoder.of(SimpleDataEntity.class))
.withEntity(SimpleDataEntity.class))
.apply("MapCsv",ParDo.of(newMapRecordAsCsvLine()))
.apply("WriteCsvInLocally",TextIO.write().to(options.getTargetFolder()));
exportCsvPipeline
.run()
.waitUntilFinish(Duration.standardSeconds(30));
Executing of Pipeline BulkDataExportWithBeam
cd samples-astra-beam-pipelines
export ASTRA_KEYSPACE=demo
export ASTRA_SCB_PATH=/tmp/scb-demo.zip
export ASTRA_TABLE=simpledata
export DESTINATION=/tmp
export ASTRA_TOKEN=AstraCS:uZclXTY....
mvn -Pdirect-runner compile exec:java \
-Dexec.mainClass=com.dtx.astra.pipelines.beam.BulkDataExportWithBeam \
-Dexec.args="\
--astraToken=${ASTRA_TOKEN} \
--secureConnectBundle=${ASTRA_SCB_PATH} \
--keyspace=${ASTRA_KEYSPACE} \
--table=${ASTRA_TABLE} \
--targetFolder=${DESTINATION}"
Google DataFlow
1. Overview
Introduction to Google Dataflow
![]()
Google Dataflow is an hosted version of Apache Beam running in the Google Cloud Platform, it is also called an Apache Beam Runner It allows users to build and execute data pipelines. It enables the processing of large amounts of data in a parallel and distributed manner, making it scalable and efficient. Dataflow supports both batch and streaming processing, allowing for real-time data analysis. Users can write data processing pipelines using a variety of programming languages such as Java, Python, and SQL. Dataflow provides native integration with main Google Cloud services, such as BigQuery and Pub/Sub.
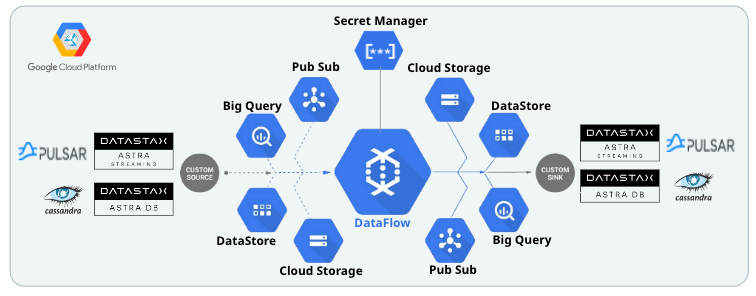
Dataflow provides built-in integrations with most in use Google Cloud Platform products suchh as Cloud Storage, Pub/Sub, Datastore or Big Query. The plaform can be extended and run any java code and I/O connectors deployed form the CLI.
Integration with DataStax comes with the integration of proper runners but also some best practice on how to handle the credentials.
2. Prerequisites
Setup your JAVA Development environment
Use java reference documentation targetting your operating system to install a Java Development Kit. You can then validate your installation with the following command.
java--version
Samples and tutorials have been designed with Apache Maven. Use the reference documentation top install maven validate your installation with
mvn-version
Setup Datastax Astra DB
An astra token acts as your credentials, it holds the different permissions. The scope of a token is the whole organization (tenant) but permissions can be edited to limit usage to a single database.
To create a token, please follow this guide
The Token is in fact three separate strings: a Client ID, a Client Secret and the token proper. You will need some of these strings to access the database, depending on the type of access you plan. Although the Client ID, strictly speaking, is not a secret, you should regard this whole object as a secret and make sure not to share it inadvertently (e.g. committing it to a Git repository) as it grants access to your databases.
{
"ClientId":"ROkiiDZdvPOvHRSgoZtyAapp",
"ClientSecret":"fakedfaked",
"Token":"AstraCS:fake"
}
It is handy to have your token declare as an environment variable (replace with proper value):
export ASTRA_TOKEN="AstraCS:replace_me"
With your account you can run multiple databases, a Databases is an Apache Cassandra cluster. It can live in one or multiple regions (dc). In each Database you can have multiple keyspaces. In the page we will use the database name db_demo and the keyspace keyspace_demo.
You can create the DB using the user interface and here is a tutorial. You can also use Astra command line interface. To install and setup the CLI run the following:
curl -Ls "https://dtsx.io/get-astra-cli" | bash
source ~/.astra/cli/astra-init.sh
astra setup --token ${ASTRA_TOKEN}
To create DB and keyspace with the CLI:
astra db create db_demo -k keyspace_demo --if-not-exists
A Secure Connect Bundle contains the certificates and endpoints informations to open a mTLS connection. Often mentionned as scb its scope is a database AND a region. If your database is deployed on multiple regions you will have to download the bundle for each one and initiate the connection accordingly. Instructions to download Secure Connect Bundle are here
You can download the secure connect bundle from the user interface and here is a tutorial. You can also use Astra command line interface.
astra db download-scb db_demo -f /tmp/secure-connect-bundle-db-demo.zip
Setup GCP Project
In the Google Cloud console, on the project selector page, select or create a Google Cloud project
Note: If you don't plan to keep the resources that you create in this guide, create a project instead of selecting an existing project. After you finish these steps, you can delete the project, removing all resources associated with the project. Create a new Project in Google Cloud Console or select an existing one.
export GCP_PROJECT_ID=integrations-379317
export GCP_PROJECT_CODE=747469159044
export GCP_USER=cedrick.lunven@datastax.com
export GCP_COMPUTE_ENGINE=747469159044-compute@developer.gserviceaccount.com
curl https://sdk.cloud.google.com | bash
gcloud init
gcloud projects describe ${GCP_PROJECT_ID}
gcloud services enable dataflow compute_component \
logging storage_component storage_api \
bigquery pubsub datastore.googleapis.com \
cloudresourcemanager.googleapis.com
gcloud projects add-iam-policy-binding ${GCP_PROJECT_ID} \
--member="user:${GCP_USER}" \
--role=roles/iam.serviceAccountUser
gcloud projects add-iam-policy-binding ${GCP_PROJECT_ID} \
--member="serviceAccount:${GCP_COMPUTE_ENGINE}" \
--role=roles/dataflow.admin
gcloud projects add-iam-policy-binding ${GCP_PROJECT_ID} \
--member="serviceAccount:${GCP_COMPUTE_ENGINE}" \
--role=roles/dataflow.worker
gcloud projects add-iam-policy-binding ${GCP_PROJECT_ID} \
--member="serviceAccount:${GCP_COMPUTE_ENGINE}" \
--role=roles/storage.objectAdmin
gsutil mb -c STANDARD -l US gs://astra_dataflow_inputs
gsutil mb -c STANDARD -l US gs://astra_dataflow_outputs
gsutil ls
gcloud secrets create astra-token \
--data-file <(echo -n "${ASTRA_TOKEN}") \
--replication-policy="automatic"
gcloud secrets create cedrick-demo-scb \
--data-file ${ASTRA_SCB_PATH} \
--replication-policy="automatic"
gcloud secrets add-iam-policy-binding cedrick-demo-scb \
--member="serviceAccount:${GCP_COMPUTE_ENGINE}" \
--role='roles/secretmanager.secretAccessor'
gcloud secrets add-iam-policy-binding astra-token \
--member="serviceAccount:${GCP_COMPUTE_ENGINE}" \
--role='roles/secretmanager.secretAccessor'
gcloud secrets list
mvn -Pdataflow-runner compile exec:java \
-Dexec.mainClass=com.dtx.astra.pipelines.test.ReadSecretAndConnectDataFlow \
-Dexec.args="\
--astraToken=projects/${GCP_PROJECT_CODE}/secrets/astra-token/versions/1 \
--secureConnectBundle=projects/${GCP_PROJECT_CODE}/secrets/cedrick-demo-scb/versions/1 \
--runner=DataflowRunner \
--project=${GCP_PROJECT_ID} \
--region=us-central1"
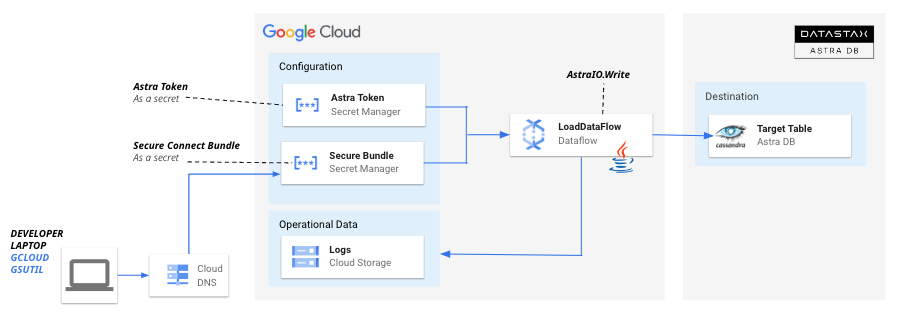
3. Bulk Data Load
Description of Pipeline BulkDataLoadWithDataFlow
In this pipeline, 100 records are generated randomly to populate a table simpledata in Cassandra in AstraDB.The simpledata table looks like:
CREATETABLEsimpledata(
idintPRIMARYKEY,
datatext
);
Implementation of Pipeline BulkDataLoadWithDataFlow
- We create a pipeline with 3 arguments:
| Parameter Name | Description |
|---|---|
astraToken |
Credentials to connect to Astra platform, it should sart with AstraCS:... |
secureConnectBundle |
Zip containing certificates to open a secured connection and endpoint definition to pick the proper database |
keyspace |
Target keyspace in Astra DB |
- Those parameters are parsed using a specialized
PipelineOptionsinterface:
/**
* Flow Interface
*/
publicinterface LoadDataPipelineOptionsextendsPipelineOptions{
@Description("Location of Astra Token secret")
@Validation.Required
StringgetAstraToken();
voidsetAstraToken(Stringtoken);
@Description("Location of secret for secure connect bundle")
@Validation.Required
StringgetSecureConnectBundle();
voidsetSecureConnectBundle(Stringpath);
@Description("Destination Keyspace")
@Validation.Required
StringgetKeyspace();
voidsetKeyspace(Stringkeyspace);
}
- Secrets are extracted from Secret Manager:
SecretManagerServiceClientclient=SecretManagerServiceClient.create();
StringastraToken=client
.accessSecretVersion(astraOptions.getAstraToken())
.getPayload().getData()
.toStringUtf8();
LOGGER.info("+ Token retrieved");
byte[]astraSecureBundle=client
.accessSecretVersion(astraOptions.getSecureConnectBundle())
.getPayload().getData()
.toByteArray();
LOGGER.info("+ Secure connect bundle retrieved");
- Pipeline uses the parameters:
PipelinepipelineWrite=Pipeline.create(astraOptions);
pipelineWrite.apply("Create 100 random items",Create.of(AstraIOTestUtils.generateTestData(100)))
.apply("Write into Astra",AstraIO.<SimpleDataEntity>write()
.withToken(astraToken)
.withKeyspace(astraOptions.getKeyspace())
.withSecureConnectBundleData(astraSecureBundle)
.withEntity(SimpleDataEntity.class));
pipelineWrite.run().waitUntilFinish();
Execution of Pipeline BulkDataLoadWithDataFlow
mvn -Pdataflow-runner compile exec:java \
-Dexec.mainClass=com.dtx.astra.pipelines.beam.dataflow.BulkDataLoadWithDataflow \
-Dexec.args="\
--astraToken=projects/${GCP_PROJECT_CODE}/secrets/astra-token/versions/1 \
--secureConnectBundle=projects/${GCP_PROJECT_CODE}/secrets/cedrick-demo-scb/versions/1 \
--keyspace=${ASTRA_KEYSPACE} \
--runner=DataflowRunner \
--project=${GCP_PROJECT_ID} \
--region=us-central1"
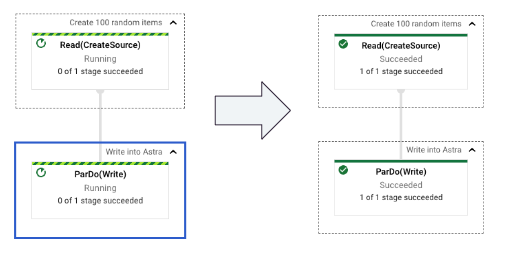
4. Bulk Data Export
Description of Pipeline BulkDataExportWithDataFlow
In this pipeline, the content of an Astra Table is exported as a set of CSV Files. The read is split in token ranges for maximum performance (read are distributed accross the nodes). Multiple files are produced in the output directory. The files are created in Google CLoud Storage.
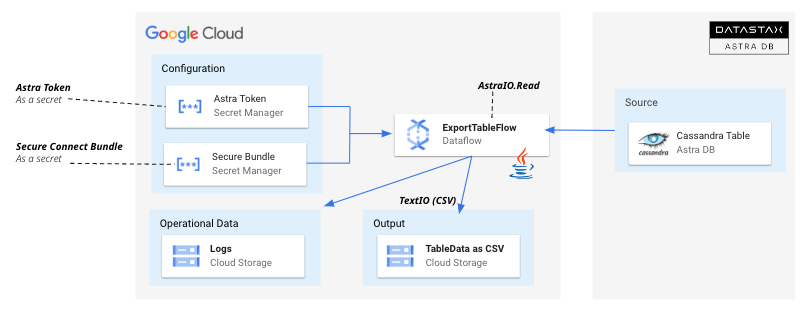
Implementation of Pipeline BulkDataExportWithDataFlow
- The pipeline requires 5 arguments:
| Parameter Name | Description |
|---|---|
token |
Credentials to connect to Astra platform, it should sart with AstraCS:... |
secureConnectBundle |
Zip containing certificates to open a secured connection and endpoint definition to pick the proper database |
keyspace |
Target keyspace in Astra DB |
table |
The table name to be exported |
targetFolder |
Destination for the files on disk |
- Those parameters are parsed using a specialized
PipelineOptionsinterface:
publicinterface ExportTablePipelineOptionsextendsPipelineOptions{
@Description("AstraToken Value")
@Validation.Required
ValueProvider<String>getAstraToken();
voidsetAstraToken(ValueProvider<String>token);
@Description("Location of fie on disk")
@Validation.Required
ValueProvider<String>getSecureConnectBundle();
voidsetSecureConnectBundle(ValueProvider<String>path);
@Description("Source Keyspace")
@Validation.Required
StringgetKeyspace();
voidsetKeyspace(Stringkeyspace);
@Description("Source Table")
StringgetTable();
voidsetTable(Stringtable);
@Description("Destination folder")
@Validation.Required
StringgetTargetFolder();
voidsetTargetFolder(Stringfolder);
}
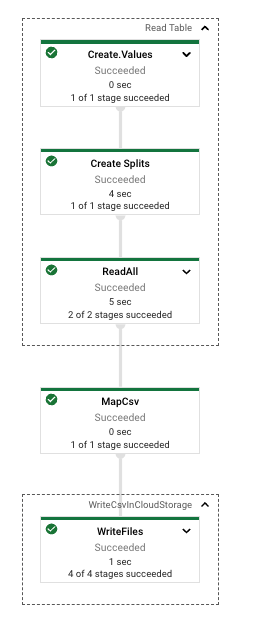
- Items are read with a
AstraIO.read()as entity, then serialized as a String
@ProcessElement
publicvoidprocessElement(ProcessContextc){
StringcsvLine=c.element().getId()+";"+c.element().getData();
LOGGER.info("CSV Line: {}",csvLine);
c.output(csvLine);
}
- Secrets are extracted from the Secret Manager and used for the READ
Execution of Pipeline BulkDataExportWithDataFlow
mvn -Pdataflow-runner compile exec:java \
-Dexec.mainClass=com.dtx.astra.pipelines.dataflow.BulkDataExportWithDataflow \
-Dexec.args="\
--astraToken=projects/${GCP_PROJECT_CODE}/secrets/astra-token/versions/1 \
--secureConnectBundle=projects/${GCP_PROJECT_CODE}/secrets/cedrick-demo-scb/versions/1 \
--keyspace=demo \
--table=simpledata \
--targetFolder=gs://astra_dataflow_ouput
--runner=DataflowRunner \
--project=integrations-379317 \
--region=us-central1"
Last update: 2023-05-04




