Here’s the Kongo code and sample connect property files for this blog.
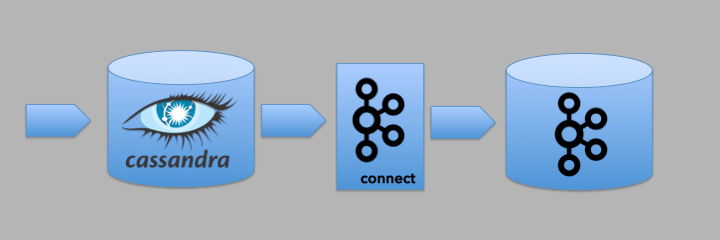
Kafka Connect is an API and ecosystem of 3rd party connectors that enables Kafka to be easily integrated with other heterogeneous systems without having to write any extra code. This blog focuses on a use case extending the Kongo IoT application to stream events from Kafka to Apache Cassandra using a Kafka Connect Cassandra Sink.
Part 4.2 covers Distributed Workers for Production and useful Kafka connect resources.
1. Distributed Workers for Production

A standalone worker is useful for testing, but for production you will probably need to run distributed workers on a Kafka connect cluster.
Distributed mode (multiple workers) handles automatic balancing of work, allows you to scale up (or down) dynamically, and offers fault tolerance both in the active tasks and for configuration and offset commit data. Distributed workers that are configured with matching group.id values (set in the distributed properties file) automatically discover each other and form a cluster. You have to run the connect-distributed.sh script (with the connect-distributed.properties file) on every node you want to be part of the Kafka Connect cluster.
Note that in distributed mode the connector configurations are not passed on the command line. Instead, you can use the REST API to create, modify, and destroy connectors. A connector created on one worker will automatically be load balanced across the other workers. You normally run a worker on each server in the connect cluster, but for testing you can run multiple workers on the same server by copying the distributed properties file and changing the rest.port number.
2. Managing Connectors via the REST API or connect-cli
Since Kafka Connect is intended to be run as a clustered service, it also provides a REST API for managing connectors. By default the REST server runs on port 8083 using the HTTP protocol. You can talk to any worker port to get a cluster wide view. Here’s some documentation with examples.
Let’s try and run two workers and two task threads for the Kafka Cassandra Connector. In the sink properties set tasks.max=2, and copy the connect distributed properties file and set rest.port=8084 in one of them. Initially just start one worker by running the distributed connect command with one of the distributed property files (with the default port):
> bin/connect-distributed.sh config/connect-distributed.properties
This is telling us that no connectors are running. Why? We haven’t actually started the connector and tasks yet, just the worker.
Landoop Lenses has a Connect Command Line Interface which wraps the Connect REST API and is easier to use for managing connectors, and this is the equivalent command to see what’s running:
> bin/connect-cli ps
No running connectors
Before trying to run two connector tasks the number of partitions for the violation topic must to be increased to two or more, otherwise only one task will be able to do anything (the other will be idle). You can do this by either creating a new topic with two (or more) partitions, or altering the number of partitions on the existing violations topic:
> bin/kafka-topics.sh --zookeeper localhost --alter --topic violations-topic --partitions 2
Now you can start the connector and tasks with the command:
> bin/connect-cli create cassandra-sink < conf/cassandra-sink.properties
…
See what’s running with:
> bin/connect-cli ps
cassandra-sink
And check the task details with:
> bin/connect-cli status cassandra-sink
connectorState: RUNNING
workerId: XXX:8083
numberOfTasks: 2
tasks:
- taskId: 0
taskState: RUNNING
workerId: XXX:8083
- taskId: 1
taskState: RUNNING
workerId: XXX:8083
This shows that there are two tasks running in the one worker (8083).
You can now start another worker by using the copy of the property file (with the changed port number):
> bin/connect-distributed.sh config/connect-distributed2.properties
Check to see what’s happening:
> bin/connect-cli status cassandra-sink
connectorState: RUNNING
workerId: XXX:8083
numberOfTasks: 2
tasks:
- taskId: 0
taskState: RUNNING
workerId: XXX:8083
- taskId: 1
taskState: RUNNING
workerId: XXX:8084
There will still be two tasks running, but each task will be running on a different workerId (server:port).
Let’s see what happens if we kill a worker (simulating a real life failure). Kill the newest worker and you’ll notice that the original has two tasks running again. Of course if you kill the remaining worker you will have no connector or tasks running. Kafka connect is intended to be used with a cluster manager (e.g. Kubernetes, Mesos etc) to manage (e.g. restart, autoscale, migrate, etc) the workers. However, note that if you start the worker again then the connector and tasks will also start again. If you actually want to stop them you have to use the command:
> bin/connect-cli rm cassandra-sink
Or you can pause/resume connectors (another option, restart, actually stops and starts them in the same state they were in):
> bin/connect-cli pause cassandra-sink
...
> bin/connect-cli resume cassandra-sink
...
Also note that the actual REST API has finer grained controls and can, for example, pause and restart individual tasks for a connector.
Is that the full story on Kafka Connect? No, there’s more. For example Transformations!
A question I asked myself at the start of this exercise was “Do you need to run a schema registry in order to use Kafka Connect?” It turns out that the answer is “No”, as we’ve demonstrated here for several simple examples. However, for more complex schemas, to reduce the risk of run time parsing errors due to data format exceptions (I saw a few and they can kill the task thread), and to support schema evolution using Avro (which uses JSON for schemas and compact binary serialization) it may be a good idea.
3. Further Kafka Connect Resources
- Official Apache Kafka Connect documentation
- The Mine of Information: Kafka Connect, good explanation of Kafka Connect from an Open Source perspective.
- Kafka connect Concepts, good overview of the main concepts (Connectors, Tasks, Workers, Converters)
- Connect Concepts, Connectors, Tasks, Workers, Converters, Transforms.
- Connect Architecture, Connector, Worker, Data model.
- Connect Plugins (a set of jar files to provide classloading isolation)
- “Kafka: The Definitive Guide”, Shapira, Narkhede, Palino, O’Reilly, September 2017, pages 141-153.
Lenses Cassandra Connector:
- Getting started with the Kafka Connect Cassandra Source, useful Walmart blog on using Cassandra as a Source for Kafka (the opposite data direction to our Kongo use case).
- Lenses Cassandra Sink, documentation for the Landoop Cassandra Sink Connector (the one we used)
- Landoop Kafka Connectors, including Cassandra.
- Also need to download Stream Reactor to get the connector properties files.
- Lenses SQL including KCQL (Kafka Connect Query Language, needed for the Lenses Cassandra Connector). Not to be confused with KSQL, Streaming SQL for Kafka.
Running Kafka Connect in distributed mode:
Note that in distributed mode the connector configurations are not passed on the command line. Instead, use the REST API (or the connect-cli program) to create, modify, and destroy connectors.
- Apache connect documentation
- Distributed Mode
- Connect REST API
- REST API (with examples)
- Lenses Kafka Connect Tools and Connect CLI documentation
Some Cassandra Connectors on github:
- https://github.com/Landoop/stream-reactor/tree/master/kafka-connect-cassandra
- https://github.com/tuplejump/kafka-connect-cassandra, 2 years old
- https://github.com/smartcat-labs/kafka-cassandra-connector, from SmartCat Labs, Cassandra Sink
Here’s the Kongo code and sample connect property files for this blog.
4. The Biggest Sink
Australia is famous for “Big” tourist attractions. E.g. The Big Rock (Uluru), The Big Banana etc. Turns out Australia also have the Biggest Sink (a bell-mouth or Morning Glory hole spillway), the Geehi Dam spillway in the Snowy mountains hydro electric scheme, it’s 32M in diameter with a massive 1557 cubic metres a second capacity. It can drain an Olympic sized swimming pool every 1.6s. Note the abseiler in this photo for scale:

I couldn’t find a photo of the Geehi Sink in spilling, but here’s a similar one from California (drone video):