Kafka Connect is an API and ecosystem of 3rd party connectors that enables Kafka to be easily integrated with other heterogeneous systems without having to write any extra code. This blog focuses on a use case extending the Kongo IoT application to stream events from Kafka to Apache Cassandra using a Kafka Connect Cassandra Sink.
For an introduction to Kafka Connect see Apache Kafka Connect Architecture Overview.
Here’s the Kongo code and sample connect property files for this blog.
1. The Problem: Streaming Kongo Events to Cassandra
In the previous blog (Apache Kafka “Kongo” Part 3: Kafkafying Kongo – Serialization, One or Many topics, Event Order Matters) we started the “Kafkification” process of the Kongo IoT application by adding some initial Kafka producers, topics and consumers for Sensor and RFID events. This enabled the rules to be checked for sensor events (for Goods in warehouses and trucks), and for RFID load events (to check that Goods are allowed to be transported on the same truck). However, we didn’t do anything as a result of these checks.
Imagine that we have a business requirement to keep track of every violation during the storage and transportation of Goods (for real-time notification), and then when Goods are eventually delivered (and potentially for arbitrary an arbitrary period after delivery) check for violations for each delivered Goods (for auditing, quality control, process improvement etc).

(Source: Shutterstock)
Because Kafka uses an immutable log store we could potentially do all this in Kafka “for free”, with appropriate retention policy settings. Nevertheless, let’s assume we need to persist the violation events in some other system. In practice, Kafka may have to be integrated with existing enterprise systems anyway (particularly if it’s being used as an integration platform!), so this use case gives us an excuse to investigate how events can be sent from Kafka to another application.
To visualise the high level event flow in the Kongo application we’ll use a Sankey Diagram. Sankey Diagrams visualise flows in systems (they have been used for everything from steam engines to Netflix). You read them from left to right and the vertical dimension is proportional to quantity. The following diagram shows relative event flows in Kongo assuming we add new Kafka producers for Sensor and RFIDLoad Checks that feed to a single new Kafka violations topic, and assumes that every check results in a violation event:
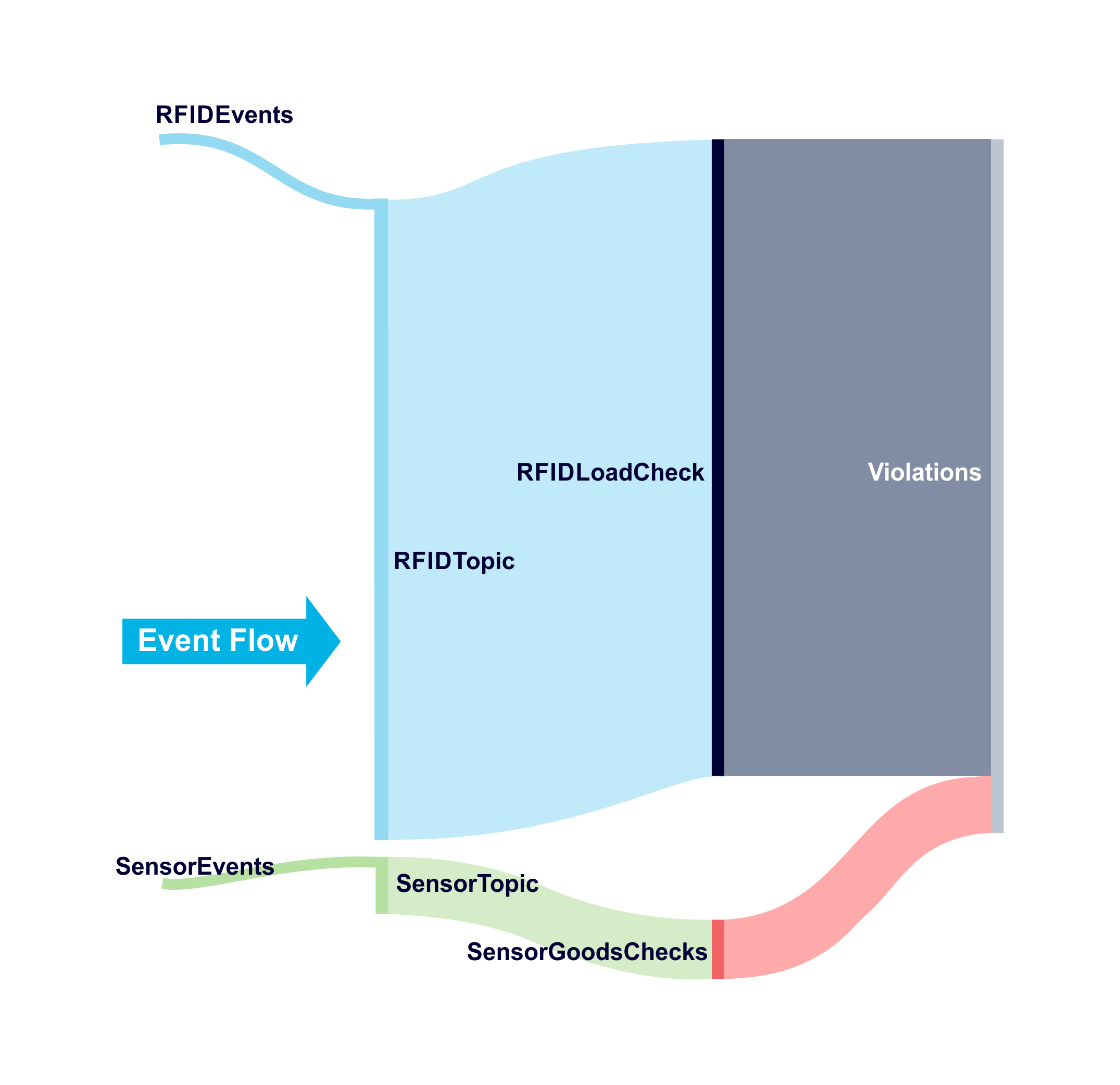
Sankey Diagram built online with SankeyMATIC.
Notice that the number of output events is much higher than the number of input events. On average, every input event can produce up to 100 output events and exhibits event “amplification” – for every input event there can potentially be an avalanche of new events produced. Both the event system (i.e. Apache Kafka) and any external Sink need to be highly scalable. Luckily as Kafka automatically provides buffering, the external system only has to keep up with the average flow rate rather than peaks. Apache Cassandra is designed for high write rates and is linearly scalable so it’s a good choice as a Sink.
2. The Solution: Kafka Connect
Having decided to write events from Kafka topics to Cassandra, how do we do it? Well, we could write a custom Kafka consumer that reads events from a topic and writes them to Cassandra. Or we could use the part of the Kafka architecture that is specifically designed for the scalable and reliable movement of data between Kafka and third party systems, Kafka Connect. Kafka connect featured (immediately below the Kafka logo) in the 1st Kafka blog:
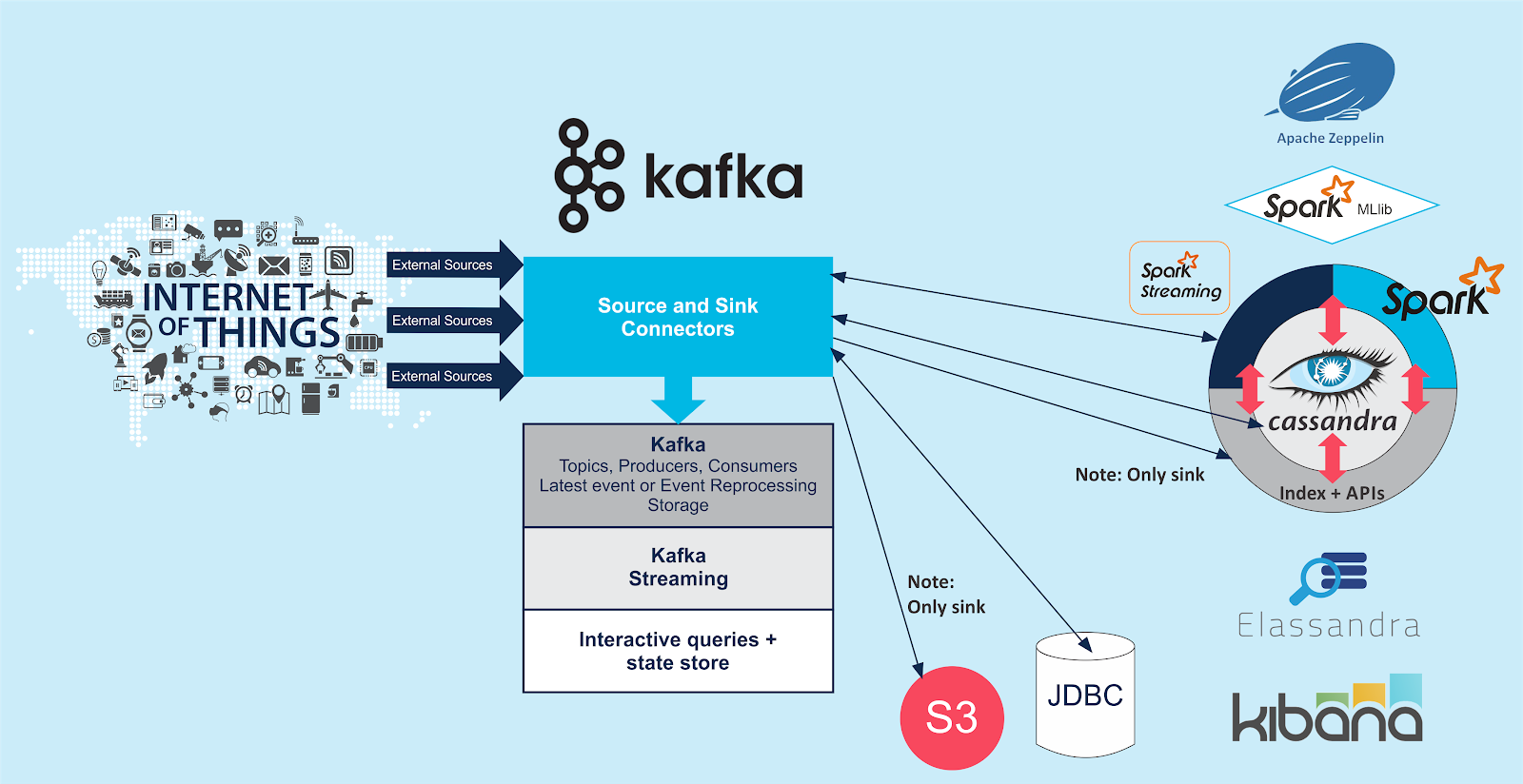
Pick‘n’Mix: Cassandra, Spark, Zeppelin, Elassandra, Kibana, & Kafka
What’s significant to realise is that Apache Kafka provides the Kafka Connect API, but it only comes with one basic example file system connector. Useful connectors are provided by 3rd parties to connect to specific systems, or you can write your own connector. So if you want to connect Kafka to system X (say Cassandra), you have to find or write connectors for that specific system, and in the direction you want to the data to go: “Source connectors” pull data from an external system (the Source) and write it to Kafka topics; “Sink connectors” read data from Kafka topics and push it to an external system (the Sink). Each connector flavour is unidirectional, you can’t go against the flow. Here’s an even simpler diagram showing the high-level Kafka Connect architecture with Source (green) and Sink (blue) data flows:
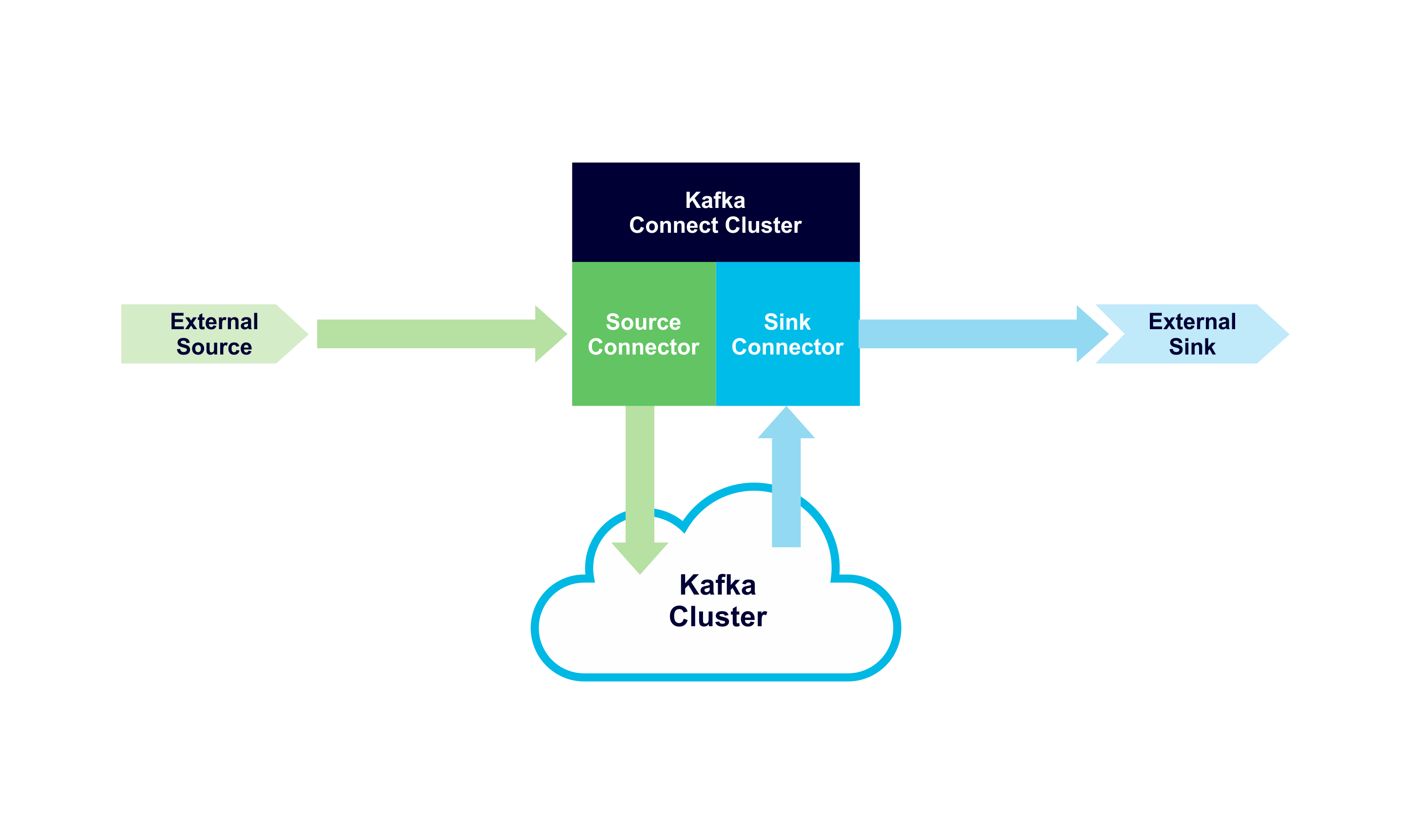
High Level Kafka Connect Architecture showing Source and Sink Flows
For an introduction to the Kafka Connect Architecture (covering Source and Sink Connectors; Connectors, Plugins, Tasks and Workers; Clusters; and Converters) please see the related blog “Apache Kafka Connect Architecture Overview”.
3. Connecting Kongo to Cassandra
How did we get Kongo working with Kafka connect? The steps taken included: Selecting a Kafka Cassandra Connector; getting the simple Kafka File Sink connector working (standalone); adding a Violations topic to Kongo; connecting Kongo to the file Sink connector; connecting Kongo to the Kafka Cassandra connector (standalone); production deployment with distributed workers.
3.1 We’re going on a Kafka Cassandra Connector Hunt!
One of the challenges with understanding and using Kafka Connect is that only the Connect API is provided by Apache Kafka, and the Apache documentation is therefore limited to the API. Doing a quick Google search it seems that there were at least a few candidates for a Kafka Cassandra Connector. This was good otherwise the rest of the blog would have been about writing one from scratch. What was I looking for in a connector? Not much really!? Here’s my wishlist (yours may be different):
- A Kafka Cassandra Sink Connector (as we want to write data to Cassandra)
- Open Source, with an Apache License
- Works with recent versions of Apache Kafka (1.1.0) and Cassandra (3.11)
- Shows some recent maintenance activity
- Works with the minimal amount of extra software
- Has reasonable documentation
- Has at least one external article describing or reviewing it
- Has some documented examples
- and is maybe certified for Kafka, Cassandra or both (is that a thing?)
To cut a longish story short, we settled on a connector from Landoop, now part of their Lenses platform (see all the connectors that were found in the resources section at the end).
This may seem like an odd choice, as even though it is open source, in theory, it requires you to run both their Lenses platform and a Schema Registry service. However, after a bit of research, I had a suspicion that it was possible to run the Landoop Kafka Cassandra connector with only the default Apache Kafka connect functionality. See How to use Kafka Connect for Cassandra without Confluent, Kafka Connect – Import Export for Apache Kafka, and “To install Kafka Connect outside of the Lenses Development Docker follow the instructions from Kafka.”
What do you need to install? Assuming we have Kafka and Cassandra installed, you also need to download the Kafka Cassandra Connector and download Stream Reactor (for the connector property files).
However, before jumping headfirst into the Kafka Cassandra Sink connector let’s dip our toes in the water with the Apache Kafka built-in example file connector to get some experience with configuring a connector, modifying Kongo, and getting them to work together.
3.2 Kafka File Connector
The Kafka file connector is simple, comes with Apache Kafka, and you can test it out just using the Kafka command line tools. I followed the instructions for the File Sink Connector here. The File Sink Connector will simply read records from a Kafka topic and append them to a file.
If you have Apache Kafka installed and running that’s all you’ll need to try it out. You need to find two property files, both are located in config. The property file for the single (standalone) worker is called, and the connector-specific property file is called connect-file-sink.properties. Copy them and make some changes. The connector property file is the simplest and has lines to: set the connector name, the connector class, the maximum number of tasks (1 in this case), the name of the file that will act as the sink (where records will be appended), and the name of the Kafka topic that records will be read from:
name=test-file-sink
connector.class=FileStreamSink
tasks.max=1
file=/tmp/test-sink.txt
topics=connect-test
The worker property file is longer. It has settings for the Kafka bootstrap servers (which you will need to set if you are running a real Kafka cluster) and Converters. The file only needs two changes from the defaults for this example. Change the default key and value converters from json.JsonConvert to storage.StringConverter:
key.converter=org.apache.kafka.connect.storage.StringConverter
value.converter=org.apache.kafka.connect.storage.StringConverter
To start Kafka connect with the worker and sink property files, run connect-standalone from the command line, with the two property files as the arguments. This starts a Kafka connect worker which in turn starts a connector and a task:
> bin/connect-standalone.sh connect-standalone.properties connect-file-sink.properties
This produces lots of useful info messages and eventually confirmation that a connector and a worker sink task have been started. From now on the worker will be continuously polling the connect-test topic for records, and passing them to the file sink task which will append them to the /tmp/test-sink.txt file. You can check that it’s working by writing some random data to the topic using the console producer like this:
> bin/kafka-console-producer.sh --broker-list localhost:9092 --topic connect-test
>one two three
>I live up a tree
And the file now contains the lines:
one two three
I live up a tree
What if you don’t change the key and value converters and instead leave them as the JSON defaults? Then the worker throws an exception and dies. Why is this? It is expecting JSON formatted data on the Kafka topic. To try JSON data, change the key and value schemas to false:
key.converter.schemas.enable=false
value.converter.schemas.enable=false
You can then send data to the topic which the file sink connector can interpret as JSON:
> bin/kafka-console-producer.sh --broker-list localhost:9092 --topic connect-test
>{"message":"one two three"}
>{"message":"I live up a tree"}
And the file contains the new lines:
{message=one two three}
{message=I live up a tree}
Note that for this example we have not used a Kafka topic key (just a value).
3.3 Adding a Violations Topic to Kongo
The Kongo code was modified to write violation messages to a violation topic in preparation for connecting the topic to Cassandra with a sink connector. As with previous topics we needed classes for the event type and serialization: ViolationEvent and ViolationEventSerializer. I initially modelled these on the RFIDEventSerializer which formatted multiple event fields as comma separated Strings. Unlike the other event types, we don’t need an ViolationEventConsumer as we are only writing data to the topics, not consuming it in the application itself.
The main changes were in Goods. I added a new KafkaProducer for ViolationEvent. Recall that there are two sorts of violations in Kongo. The first is if a Goods in a location (warehouse or truck) has any rules violated due to a sensor event value being out of range. If a violation is detected then a new ViolationEvent is created and sent to the topic, with a key being the Goods Id, and the value is a String with the violation category (“sensor”) and details of all the rules that were violated and why.
The second violation event may occur as a result of an RFID load event If a Goods is loaded onto a truck and there is a co-location violation with any of the Goods already loaded (a conflict of categories allowed to be transported together). Again a ViolationEvent is created and sent, with the key equal to the Goods loaded, a violation category of “location” and a String containing the details.
Due to the new use case requiring notifications to be produced and written to Cassandra, for every Goods violation during storage and transport, I noticed that the original version didn’t check or produce warnings for the Goods already loaded on trucks. As the Sankey diagrams in the introduction revealed, a side-effect of this is that there may be a large number of violation events produced for a single RFID load event.
3.4 Connecting Kongo to a File Sink
We can now ramp up our experiments and see if we can get the Kafka File Sink connector working with the new Kongo violations topic to write violations to a file. To do this, just change the topic name in the connect-file-sink.properties file to the new violations topic, and check that the converters are set to StringConverter in connect-standalone.properties:
key.converter=org.apache.kafka.connect.storage.StringConverter
value.converter=org.apache.kafka.connect.storage.StringConverter
Start the connect worker as above and then start the Kongo application (from KafkaRun). Check the contents of the sink file and you’ll see the violation messages.
3.5 Connecting Kongo to a Cassandra Sink
Now let’s try and write the violations events to Cassandra. What do you need to do? Get the connector and get the property files. Modify the property files. Run the connector.
The most important links are as follows (see resources below for more):
- Lenses Cassandra Sink, documentation for the Landoop Cassandra Sink Connector
- Landoop Kafka Connectors, including for Cassandra.
- Download Stream Reactor to get the connector properties files.
Copy/move the Kafka-connect-Cassandra jar file to libs, and the connector property file, cassandra-sink.properties, to config.
One of the major issues to consider is what data format to use, as there seem to be a number of options, and some of them require a Schema Registry service. The simplest approach seemed to be JSON. See the No Schema and a JSON payload instructions for setting the converters in the worker property file (just use a copy of the one used for the file connector worker).
To try this out without an existing Cassandra cluster running, you can set up a local database with these instructions. The Cassandra connector Sink expects a keyspace and table to exist to write the data into so you can create them first with the cqlsh command line:
CREATE KEYSPACE kongo WITH replication = {'class': 'SimpleStrategy', 'replication_factor': '1'} AND durable_writes = true;
CREATE TABLE kongo.violations (
goods text,
error text,
PRIMARY KEY (goods, error)
)
Table design is important in Cassandra, and you need to think about what queries you want to use. We assume that for this use case we will want to query if a particular Goods Id has any violations, and find all violations for a Goods Id. This means that the partition key will be the Goods Id. But given that there can be multiple violations for a Goods during its storage and transportation lifetime, we need another key as well, making a compound primary key. The additional column is the clustering key and we use the complete error String message. This allows a query like this:
select error from violations where goods=’GoodsId’;
Which will return all the errors for GoodsId.
Now configure the cassandra-sink.properties file with Connector class, topic, and Cassandra settings:
connect.progress.enabled=true
name=cassandra-sink-orders
connector.class=com.datamountaineer.streamreactor.connect.cassandra.sink.CassandraSinkConnector
tasks.max=1
topics=violations-topic
connect.cassandra.kcql=INSERT INTO violations SELECT goods, error from violations-topic
connect.cassandra.contact.points=localhost
connect.cassandra.port=9042
connect.cassandra.key.space=kongo
connect.cassandra.username=me
connect.cassandra.password=nottelling
Note the kcql line. KCQL stands for Kafka Connect Query Language (not to be confused with KSQL which was designed for Kafka stream processing). This tells the connector how to map the Kafka topic data to the Cassandra table data. The topic key is not used by the connector, just the topic value. The KCQL above tells the connector to read data from violations-topic, parse the value and find the goods and error fields, and then write the goods and error values to the goods and error columns of the Cassandra table, called violations in the Kongo keyspace. This requires that the Goods Id appears as data in the topic value, even though it may already be used as the topic key. However, reading the KCQL documentation, it appears to be possible to access and use the topic key value directly (with _key.*).
KCQL may seem like overkill for this simple example, but the claim is that it can enable more complex use cases, e.g for selecting and renaming fields, and even content based delivery – i.e. different events/columns to be sent to different Cassandra tables dynamically. E.g. sensor violations to one table and RFID load violations to another.
To test everything we have so far, before connecting it to Kongo, start the Cassandra sink connector using the standalone worker (as above for the file sink) with the new connector property file:
> bin/connect-standalone.sh connect-standalone.properties cassandra-sink.properties
And then test it out with some “fake” JSON data:
> bin/kafka-console-producer.sh –broker-list localhost:9092 –topic violations-topic
>{“goods”:”goods1″,”error”:”temperature > 50″}
>{“goods”:”goods1″,”error”:”humidity > 90″}
>{“goods”:”goods2″,”error”:”Bulky and Fragile Goods co-located”}
> etc
Surprisingly (to me) this worked and the data appeared in Cassandra!
The final change required to Kongo for the actual violation events to appear in Cassandra was to modify the ViolationEventSerializer serializer method to turn ViolationEvents into a JSON formatted String, with the two required fields (goods and error with String values), before serializing as a byte array. Given the incremental development and testing approach taken, this also worked and real violation events were written to Cassandra.
Part 4.2 is next and covers distributed workers, and useful Kafka Connect resources.