

What is the SMACK Stack!?

The SMACK stack is a group of tools that I have seen popping up more and more recently. I am very excited about this technology stack because it brings together a few of my favorite tools. The SMACK stack makes it easy to build powerful and scalable applications. Over the next few weeks I’m going to be writing various articles discussing each part of the SMACK stack.
To kick off this new series, I want to get started by talking about the purpose of the SMACK stack. Then I will do a skin deep introduction to the five tools that make up the stack.
Let’s say you wanted to build a new dating app. Something identical to other apps on the market. You need to be able to see who is in your area, swipe right and left, and chat. Your decide to take advantage of some tech within your comfort zone.

Apache Tomcat as the app server, a java application to write your code, and postgres as your database. All this running on top of a linux server.
Your first priority when building this new application is getting it work. You need to store the profile information for all your customers and as well as what people swipe. You will also need to be able to quickly deliver new recommendations to people using the app. You work for a few weeks to build out all this logic in Java and store the data in postgres. For months everything is running great but then it happens. You go viral!
Everyone loves you app and traffic has explodes! Your java application is bursting at the seams. Postgres can’t handle the transactions comes screeching to a halt. You’re left with two options. You can migrate everything to massive cloud machine which will cost cost a pretty penny. But even that it’s a temporary solution. Your left having to redesign your application from the ground up.
I bet you wish you had thought about scalability day one. Todays technology consumers have high expectations for your the functionality and performance of the tools they use.
So what is a systems architect to do?

In walks the SMACK stack! The SMACK stack is made up of 5 different tools covering different areas. Spark, Mesos, Akka, Cassandra, and Kafka. The stack as a whole handles big data batch processing, stream processing, distributed queuing, serverless development, and distributed storage all running on top of a scalable infrastructure. The cherry on top, all these tools are all Open Source, have amazing documentation, and great support communities!
For the rest of this article I will touch on each tool in the SMACK stack. By the end I hope you will be as excited about these tools as I am.

The first tool in the SMACK stack is Apache Spark. I will be completely honest and say I am biased when it comes to this tool. I love it!! Apache Spark is a distributed batch and stream processing tool built as a successor to Hadoop.
The Berkeley AmpLab developed Apache Spark as a next generation alternative to Hadoop. Apache Spark takes advantage of modern hardware improvements to deliver lightning speeds. Apache Spark is also easy to use with APIs written in Java, Scala, R, and Python.
Spark relies on one simple concept, divide and conquer. When a task seems overwhelming, one approach is to split that large task into the smallest possible pieces. Apache Spark leverages a cluster of machines to execute a massive number of simple operations on a data set. These simple operations add up to sophisticated jobs on huge amounts of data.

Apache Mesos is the platform on which everything runs. Think of Apache Mesos as an operating system for distributed systems. Mesos runs on a cluster of machines and delegates work where resources are free.
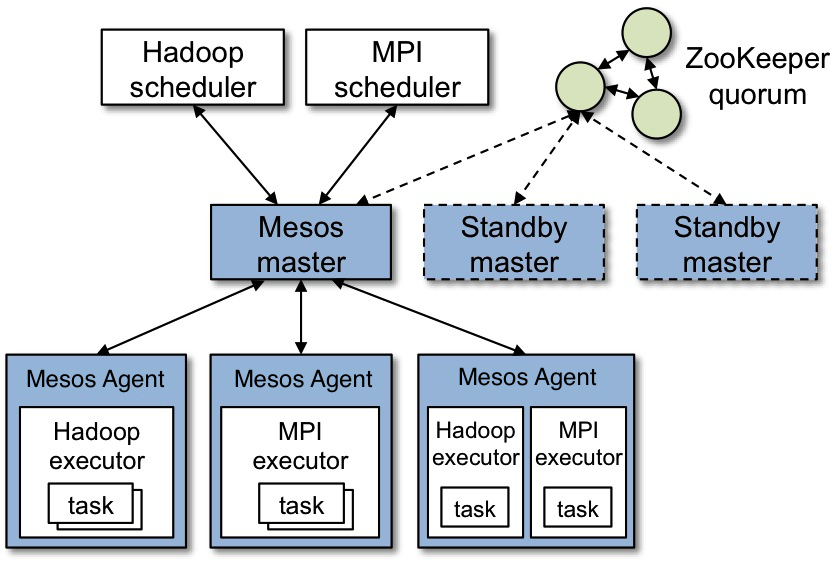
“Apache Mesos abstracts CPU, memory, storage, and other compute resources away from machines (physical or virtual), enabling fault-tolerant and elastic distributed systems to easily be built and run effectively.” — Apache Mesos homepage
Many people compare Apache Mesos to Docker Swarm or Kubernetes. This is a fair comparison because Mesos is able to run and orchestrate containers. Apache Mesos has a core difference from other container managements systems. Most container management systems focus on starting up long running containers. Apache Mesos shines by creating a short lived container to execute one specific unit of work. This allows Mesos to operate more fine grained and maximize the usage of all the resources in your cluster.
When you run all pieces of the SMACK stack on top of Apache Mesos you can add more resources at any time. Add another machine to your Mesos cluster and Mesos will take care of the rest.

Akka is a set of Scala libraries used for writing serverless applications. Akka allows you to write concurrent applications without worrying about low level concurrency constructs like atomics and locks. Akka also makes it easy to spin up an elastic and highly available cluster of workers to run you Akka code.

Think of Akka as the cooler younger nephew of messaging busses triggering COBAL jobs. Is funny how time seems to repeat itself. The actor pattern used by Akka has been around for a long time in mainframes. With Akka this old pattern has been given a makeover with new distributed computing tools making it easy to build our your own serverless application platform.
In Akka all jobs are places on queues. When an actor(worker) becomes available it pulls a message off the queue and completes the job. These jobs can be data processing, responding to a HTTP calls, or pulling data from a database. In each case rather that having a thread wait for another thread to finish just move on to the next job.
This pattern makes Akka the right development framework to code your new scalable application along side the rest of the SMACK stack.

“The Apache Cassandra database is the right choice when you need scalability and high availability without compromising performance. ” — Cassandra Website
If you are looking for a fault tolerant, scalable, decentralized, distributed database, with battle tested experience to store your important data, look no further. Apache Cassandra is the the NoSQL database you have been looking for.
Wow that is a mouthful!
Apache Cassandra is a row oriented NoSql database built for the Big Data era. Facebook built Apache Cassandra using tech from Google Big Table and Amazon Dynamo.
What does this all mean?
Apache Cassandra is a big database that can run across of a lot of servers without slowing down. More servers means more disk, more memory, and more cpu. But more servers also means more coordination and potential problems. Apache Cassandra takes care of all that coordination, including data replication and node orchestration. That way you can focus on inserting and retrieving lots of data.
Apache Cassandra allows you to add more nodes when you need it as well as remove them when you don’t. This makes Cassandra a great addition along with the other members of the stack. Each of these tools allow you to start small and scale up or down depending on your needs.

Last but not least, Apache Kafka. Apache Kafka is a distributed Pub/Sub messaging system. This means it is basically a supercharged messaging queue. Apache Kafka is able to manage a queue running across many servers with many publishers and subscribers.
To make this possible Kafka splits a specific topic into many partitions. Then it distributes these partitions across different brokers running on different physical machines. This allows Kafka to scale without loosing data.
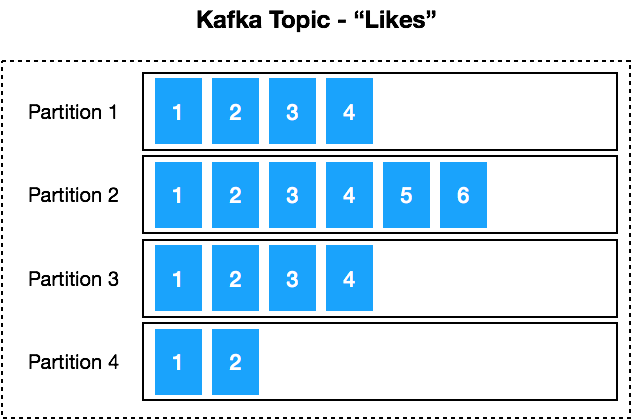
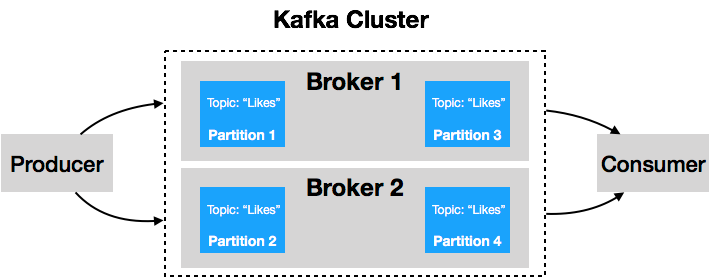
“Kafka® is used for building real-time data pipelines and streaming apps. It is horizontally scalable, fault-tolerant, wicked fast, and runs in production in thousands of companies.” — Apache Kafka homepage
LinkedIn developed Apache Kakfa to handle huge numbers of producers and consumers reading and writing simultaneously. This ability allows Kafka to act as a massive distributed buffer within your SMACK stack. Kafka will keep track of any information as it comes into your application until there are available machine resources. Both Apache Spark streaming and Akka play well with queues specifically Kafka.
All this makes Kafka another welcome member of the SMACK stack.
So now I will apologies to those of you who have been completely overwhelmed. I covered a lot of information very quickly but i have barely scratched the tip of the iceberg.
Over the next few weeks I will write more thorough articles for each piece of the SMACK stack. I will also building out some demos so we can better see where the SMACK stack thrives and where it falls over.







