The CQL — Cassandra Query language gives an almost SQL type interface to Apache Cassandra. I have found many times,that many who use this,do not know about some important points of Cassandra that makes it different from SQL databases like Postgres. Same is the case for operations team, there are some aspects related to storage, GC settings , that many are not aware of. I am not an expert in Cassandra internals and don’t aspire to be if I can avoid it.This is mostly a note to myself, and something which I can ask others to refer to instead of repeating over email a gazillion times. There are lot of other parts like repair etc which I have left out. The intention here is to make this as short as possible, but if you feel somethings are to be added, please comment.
Cassandra has Tune-able Consistency — not just eventual consistency
Many considering Cassandra as a replacement for SQL database like Postgres, MySQL or Oracle, shy away thinking that eventual consistency of NoSQL does not meet their requirement. In Cassandra ,however consistency is configurable. This means that with some write and read speed sacrifice, you can have strong consistency as well as high availability. Cassandra can be used for small data as well as big data; depending on your use case you can tune the consistency per key-space or even per-operation.
Cassandra values Availability and Partitioning tolerance (AP). Tradeoffs between consistency and latency are tunable in Cassandra. You can get strong consistency with Cassandra (with an increased latency).
https://wiki.apache.org/cassandra/ArchitectureOverview
At this point it may be a good idea to have a short recap of CAP theorem as there is a lot of confusion translating the theoretical surmise to the practical world.
In 2000, Dr. Eric Brewer gave a keynote at the Proceedings of the Annual ACM Symposium on Principles of Distributed Computing in which he laid out his famous CAP Theorem: a shared-data system can have at most two of the three following properties: Consistency, Availability, and tolerance to network Partitions.
This applies to any distributed data base, not just Cassandra.So Cassandra can provide C and A not P ? Is it a big problem ?
Short answer — It is not. Skip the rest of the section if you are in a hurry.
Long answer read on.Here is the excerpt from Cassandra docs. (DataStax’s docs)
… You can tune Cassandra’s consistency level per-operation, or set it globally for a cluster or datacenter. You can vary the consistency for individual read or write operations so that the data returned is more or less consistent, as required by the client application. This allows you to make Cassandra act more like a CP (consistent and partition tolerant) or AP (highly available and partition tolerant) system according to the CAP theorem, depending on the application requirements.
Note: It is not possible to “tune” Cassandra into a completely CA system. See You Can’t Sacrifice Partition Tolerance for a more detailed discussion. -https://docs.datastax.com/en/cassandra/3.0/cassandra/dml/dmlAboutDataConsistency.html
Here is an excerpt from the article linked in the DataStax’ s Cassandra documentation page.
Of the CAP theorem’s Consistency, Availability, and Partition Tolerance, Partition Tolerance is mandatory in distributed systems. You cannot not choose it. Instead of CAP, you should think about your availability in terms of yield (percent of requests answered successfully) and harvest (percent of required data actually included in the responses) and which of these two your system will sacrifice when failures happen. -https://codahale.com/you-cant-sacrifice-partition-tolerance/
What the above article explains in depth is that Availability is tied to Network Partitioning or Partition Tolerance.Worst case scenario network partitions are quite rare inside a Data Center network. Also network partitions cannot be prevented from happening. It is ever present, though mostly transient and intermittent. The risk of network partitioning across many nodes in a cluster so as to disrupt Availability for a multi-node cluster is very less.
So with Cassandra you can have as good a C and A system as practically possible.
Give Importance to modelling the Partition key
If there is only one thing that you should read,maybe it is the link below
What is the Partition Key ? It is the first part of the Primary Key or the Primary key itself if Primary key is not composite
Why is this most important part ?
To have balanced write of data to multiple Cassandra nodes in the cluster and subsequent balanced reads of the data.
When data is inserted into the cluster, the first step is to apply a hash function to the partition key. The output is used to determine what node (and replicas) will get the data.-https://docs.datastax.com/en/archived/cassandra/3.x/cassandra/architecture/archPartitionerM3P.html
Here are two main goals to consider for modelling the data
1. Spread data evenly around the cluster — Model Partition Key
2. Minimize the number of partitions read -Model Partition Key and Clustering keys
Let us take an example. Below is a initial modelling of table where the data is some events (say political rallies, speeches etc) that has occurred in a particular location, centered over latitude,longitude and say having a radius of 250 meters. Each location has an influential candidate of that area. Sometimes the same area can have multiple influential candidates. I have illustrated a slightly complex example so as to show the flexibility in data types present in Cassandra,and all the aspects to consider when modelling the key. The actual cell can be a telecom cell with multiple coverage by different operators or different technologies. The example I give here is a bit contrived and for illustration only.
Note that partition key is chosen assuming that events are distributed evenly across a city, the key will distribute the data from multiple locations evenly across available Cassandra nodes.
The partition query should be modeled for efficient retrieval of the data application needs
The modelling of Tables and thereby the partition key is primarily with consideration of efficient data retrieval.
Assume that we need to query all events happening in a location by a Candidate for a time interval.The queries will be a set of statements like
select * from demo_table where bin_cell_key = (1234, 222, ‘Candidate1’) and time_key >= (‘06:00:00.000000000’, ‘06:00:00.000000000’) and time_key < (‘07:30:00.000000000’, ‘07:30:00.000000000’)
select * from demo_table where bin_cell_key = (1234, 223, ‘Candidate1’) ..
But to compose this bin_cell_key we need to know first which Candidates are there in which locations. For this we need to model helper tables. Note — Data duplication is okay in NoSQL data modelling and to have the same effect of JOINs this is needed. Some helper tables to get the bin_cell_key
create table cell_bin (cell text, bin tuple<int,int>, PRIMARY KEY (cell,bin));
Example CQL:
select * from cell_bin where cell=’Candidate1’;
cell | bin
— — — — -+ — — — — —-
Candidate1| (1234, 222)
Candidate1| (1234, 223)
And similarly for the other way round
create table bin_cell (bin tuple<int,int>, cell text, PRIMARY KEY (bin,cell));
Example CQL:
cqlsh:demo_keyspace> select * from bin_cell where bin = (1234, 222);
bin | cell
— — — — -+ — — — —— -
(1234, 222) | Candidate1
(1234, 222) | Candidate2
We can stop here. But if you are curious read on. What if we want to aggregate all events that has taken place in a region irrespective of the Candidate. For this we need to split the cell out. Why ? because in case of a composite partition key all the elements need to be specified in the query.
select * from demo_table where bin = (1234,222) and year=2017 and month=12 and day=1;
The table for below which also adds time to the partition key so that data from different days are distributed across available nodes are given below.
create table demo_table( year int,month int,day int, bin tuple<double,double>, cell text, time_key tuple<timestamp,timestamp>,event text, PRIMARY KEY((bin,year,month,day),cell,time_key));
Test and measure your reads & write via nodetool cfstats
How do we know if our data model is distributing writes across nodes. How do we know if the write latency and read latency is distributed across nodes and if it is linearly scale able in proportional to the nodes added. The answer to all of this via node tool cfstats command
nodetool cfstats
Provides statistics about tables.docs.datastax.com
You need to run long runs with write and then read operations using multiple nodes and everyday update a table like one below based on the output from cfstats. Soon you will know if your write and read are balanced. Actually adding more nodes should also decrease your read time linearly. This is really beautiful.
Do not use ALLOW FILTERING and IN Clause in CQL indiscriminately
If you feel that there is no way out; then please read the section above. Most probably your table modelling has to be refactored.
When your query is rejected by Cassandra because it needs filtering, you should resist the urge to just add ALLOW FILTERING to it. You should think about your data, your model and what you are trying to do. -https://www.datastax.com/dev/blog/allow-filtering-explained-2
Or for that matter IF clause
The new versions of Cassandra supports light-weight transactions. In CQL this is done via the IF clause. Insert into table IF NOT EXISTS.
Lightweight transactionsshould not be used casually, as the latency of operations increases fourfold due to the due to the round-trips necessary between the CAS coordinators. -https://docs.datastax.com/en/cql/3.3/cql/cql_using/useInsertLWT.html
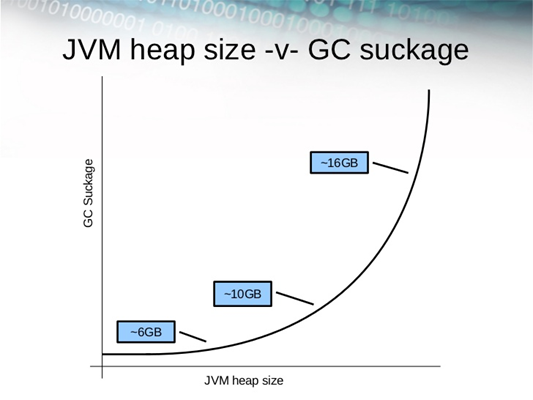
Be aware of the JVM GC Suck-age as JVM Heap Increases
Cassandra runs on the JVM and relies on the OS page cache for improving performance. There is no need to throw huge amounts of RAM at Cassandra. Cassandra performance should increase by adding more low powered nodes.We have run our long runs for about 2 weeks with load on 2 GB JVM heap, and Cassandra had never once gone down.
JVM GC suckage is directly proportional to the JVM heap. This is true for any Java process and also for Cassandra
Some illuminating quotes
Many users new to Cassandra are tempted to turn up Java heap size too high, which consumes the majority of the underlying system’s RAM. In most cases, increasing the Java heap size is actually detrimental for these reasons:
1. In most cases, the capability of Java to gracefully handle garbage collection above 8GB quickly diminishes.
2.Modern operating systems maintain the OS page cache for frequently accessed data and are very good at keeping this data in memory, but can be prevented from doing its job by an elevated Java heap size.
If you have more than 2GB of system memory, which is typical, keep the size of the Java heap relatively small to allow more memory for the page cache .
Database like Scylla DB have ported the Cassandra design on to C++ so as to avoid the GC pauses and other such problems related to JVM. But as long as you keep the JVM heap around 8 GB things should be fine.
An update here- While I was working with Cassandra G1GC was not deemed stable enough to be used. Now DataStax version of Cassandra used G1GC. G1GC can handle larger heaps; however Cassandra can use RAM heavily for page caches, filters etc, so all the above still makes sense. Limit JVM heap to the minimum you need and leave the rest of the memory for Cassandra process.
Cassandra does not like SAN/Shared Storage
Cassandra is designed for the low fetch times of spinning disks by only appending data to the end for writes and minimize disk seek time during read via application selected partition keys and thereby spreading reads across multiple nodes — Regarding storage a good slide to go through https://www.slideshare.net/johnny15676/why-does-my-choiceofstorage-matterwithcassandra

Customer/User — “We have an awesome SAN and would like to use it for Cassandra.”
DataStax — “We don’t recommend shared storage for Cassandra.”
Customer/User — “Why not.”
DataStax — “Two reasons really. One — performance suffers. Two — shared storage introduces a single point of failure into the architecture.”
Customer/User — “Our SAN is awesome and has never had any down time and can preform a kagillion IOPS. So why exactly shouldn’t we use shared storage.”
https://www.datastax.com/dev/blog/impact-of-shared-storage-on-apache-cassandra
Horizontal Scale-ability -Transparent Sharding vs Application Level Sharding
Database sharding is a way of horizontally scaling database. Application level sharding means that the logic of partitioning data across multiple node is done at the application level. That is based on some key- classic example — East Coast vs West Coast or similar; your DB write code will select a Database to connect , write and read. The problem is that the complexity of application level sharding quickly gets complex and it is not a good way to scale . Cassandra and most NoSQL databases does sharding transparently (as you have seen via the partition key). This is a pretty big advantage as without this horizontal scaling is a hard problem.
Open-Source and Commercial
As of the time of writing this, relations between Apache Foundation and Datastax- which was one of the largest contributor to Cassandra ? have soured. There is an commercial version of Cassandra — Datastax Enterprise Edition and open source version is the Apache Cassandra. The Java driver of Cassandra has two version, the open source and DSE provided, and you cannot use commercial driver with open source Cassandra. For other languages like Go the driver is open source.