
Leaderboard @Dream11
Scale to serve 100+ million reads/writes using Spark and Cassandra
By Bharat Vishwakarma, Amit Mirchandani, Amit Sharma
Dream11 — Leading the Pack in Fantasy Sports
Dream11 is India’s #1 Fantasy Sports platform with a growing user base of over 15 million Indians playing Fantasy Cricket, Football & Kabaddi. To play on Dream11, users create a virtual team of real players, who score points based on their real-life performance in the upcoming match. Our ‘Leaderboard’ feature enables all our users to see how their team ranks amongst all other competing teams, as their points are updated every minute during every match. The excitement our users feel while watching their chosen players score points for their team with every four, six, wicket, goal, etc. is the core of our entire user experience.
Leaderboard generation starts by calculating total points earned by every one of up to 6 teams created by each of our 15 million users. These points are calculated as per the composition of up to 11 players selected from the squad and points scored by the players for every action. These teams are then grouped by the participating contest, sorted by total points and ranked as per competitive ranking to create the Leaderboard for a contest. Leaderboards are updated every minute across thousands of contests for multiple matches being played at the same time.
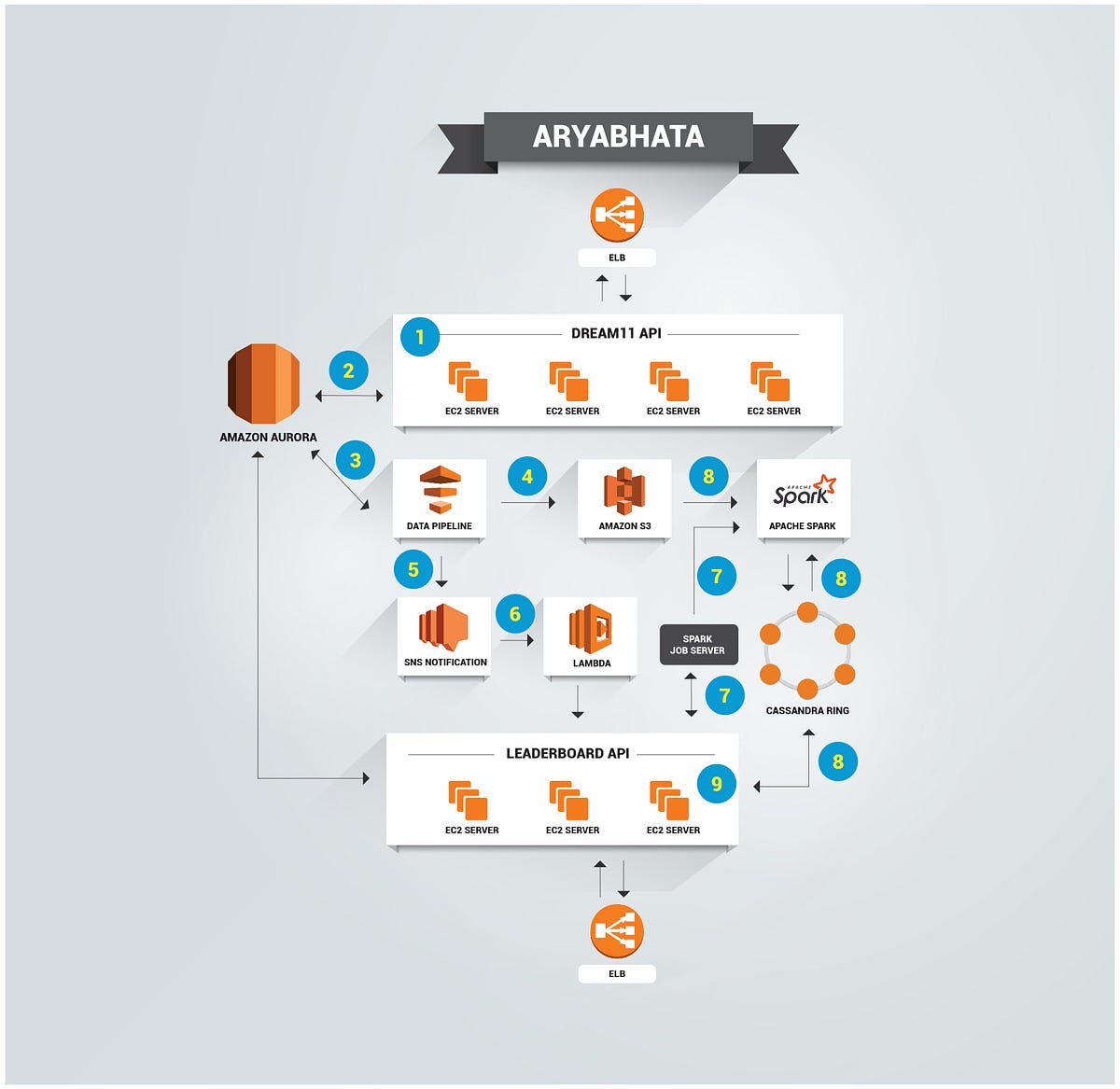
The Leaderboard at Dream11 is internally powered by the point calculation engine, code named “Aryabhata” and here’s what it looks like:
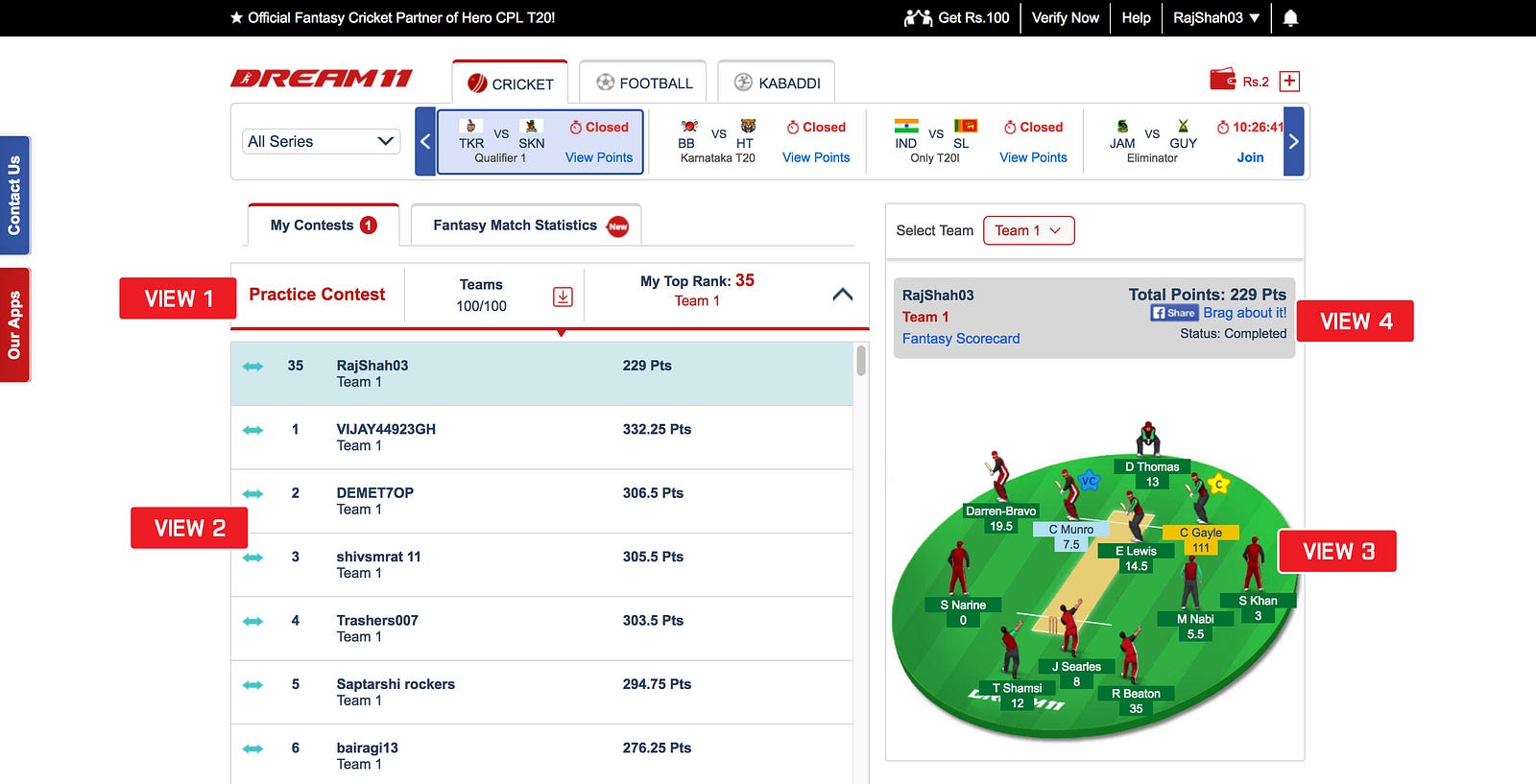
The Dream11 Leaderboard — scale, technology and reliability considerations that influenced our engineering decisions
Our Leaderboard has already served 1 million requests per minute, serving 250k concurrent users at its peak. As our user base grows, we expected the request pattern to grow by a much larger magnitude. So, we needed to design a system that would linearly scale as our traffic increases. It should be able to crunch gigabytes of data using distributed sorting within a SLA (Service Level Agreement) of under a minute, while maintaining strong consistency of different user views across multiple platforms. The persistent systems used should support millions of input/output operations per second, while maintaining throughput and latency under the strict SLA desired. This is done to ensure that our users have a seamless experience across platforms and devices at all times.
Let’s dive deeper into our system to understand the technical nuances and how we approached them to provide a solution.
- Calculating, Sorting, Ranking and Storing data within 1 min SLA using Apache Spark
Apache Spark is a fast, distributed, in-memory highly scalable cluster computing framework. It provides support for low level java APIs as well as sql, for processing large amount of data within sub second latency. We leverage Spark for calculating, sorting and ranking of our data. So far, we’ve been able to use Spark to process Leaderboards of around a million contests, ranging from 2 teams to 400,000 teams in different contests for a single match, totalling up to 40 million records within our 60-second SLA.
The point calculation engine loads data for all contests in Apache Spark’s memory which is distributed across the cluster machines, allowing us to scale up simply by adding more nodes to the Spark cluster. The distributed contest data is then processed concurrently to calculate new points for every participating user team. Once the new user team points are prepared, they are grouped by contest, sorted and ranked as per competitive ranking, thereby completing the generation of the new Leaderboard state. By deploying Spark at a large scale for all our calculations, we make sure our users don’t miss a thing with the fastest of real-time updates at lightening speed.
2. Providing consistent views to users using Data Isolation and Snapshots
The contests that a user has joined and the Leaderboard for each of those contests is displayed in different view parts on the product (refer to the image above). The user can browse this data and also access the points/ranks/teams of other users participating in the same contest as him, once the deadline (1 hour prior to the start of match) hits. Every view needs to be consistent when points and Leaderboard are updated in the background. For eg: If our Leaderboard for a contest shows results for calculations done at an event (eg. 1st ball of over), our team view should also show our users their team points of the same calculation event, so that the displayed points are the same.
The point calculation engine concludes by updating every contest record in worst case scenario. If we fetch data from the same source that is being simultaneously updated, the breadth of the update operation will result in inevitable view inconsistency. Moreover, since all the updates are live to the user, rollbacks damage user trust and provides a bad user experience. Therefore, we need to isolate read and write operations at the data level. Snapshot Isolation in transactional system provides a way to manage concurrency by isolating data at which they operate, generally implemented by MVCC [multi version concurrency control]. Operating with multiple version of data helps to isolate concurrent operation and maintain consistency of database.
The point calculation engine extends the above idea and snapshots every write action resulting in immutable data set. This insert-only behavior and immutability allows concurrent processing of multiple game events which we can tag linearly to allow easy rollbacks. The user view can now be tagged to a snapshot version thereby achieving consistency across all user view, even when new snapshot is in process.
3. Guaranteeing atomicity of Bulk Write/Calculation using Apache Spark
Apache Spark provides fault tolerance out of the box. In case of failures in cluster machines, jobs are rescheduled on other available cluster machines. If rescheduling fails for certain attempts, Spark fails the whole job and shuts down the entire process. As long as your process is idempotent, such a feature allows building atomic bulk operation by retrying failed events to completion.
The point calculation engine leverages this fault tolerant property of Spark and solves atomic bulk write problem by moving away from UPDATE to INSERT IF NOT EXISTS operation. Since we only perform insert operations, multiple inserts would only result in the same output thereby achieving idempotency in the system.
4. Implementing bulk Write/Read With Horizontal Scaling and HA using Apache Cassandra
Based on the requirements of the point calculation engine we needed to choose a persistent system with the following properties:
- Highly available and capable of handling loss of a few nodes
- Tunable consistency
- Easy to scale up and down based on need
- Multi-Master to serve the traffic at the rate desired, which would be difficult in a master-slave setup due to replication lag
- Optimized for very high write throughput
- Strong community support
Apache Cassandra is a distributed, fault tolerant and highly available system that is specifically designed to handle huge amount of data. Primary features of Apache Cassandra includes decentralized architecture with no single point of failure, high availability with replication within cluster while performing write operation. This is in contrast to a master-slave system, where data is written to master and propagated to slave via binary logs which adds to replica lag. Apache Cassandra supports tunable consistency and has a strong community support.
Dream11 Leaderboard is supported by a 10 node (c4.8x large Amazon ec2 instances) Cassandra cluster which has supported 5 Million read/write CPM (calls per minute) at peak.
5. Supporting Flash Read and other Read optimizations using Redis as a local cache
Our Leaderboard use case demands bulk atomic writes as well as reads with very high throughput. It is also a well-known fact that Cassandra performs optimally best for pointed queries, i.e. queries with filter clause that identify partition and data residence efficiently. Hence, we needed to design the Data Model in such a way where both Bulk Writes and High Reads demands can be fulfilled to scale. We designed several views which were written by Spark jobs directly into Cassandra. The read queries to Cassandra directly fetched data from respective views with pointed queries and thus, became highly scaled.
Also, since the Leaderboard data mutates every 60 seconds, we analyzed that a caching layer in the middle would further optimize reads. One possible option was to add a centralized Redis cluster. We had run into some issues at scale with this approach in the past because of hot/cold zones. Due to this, we ended up having to deploy a lot more nodes than needed. We also realized that since our point calculation data is immutable, it can be cached in a distributed fashion (Local redis at Web Server end) removing the need of a central redis cluster service thereby eliminating one more point of failure/bottleneck in the system. It can flush data every time a new event arrives and can achieve a low cache size. Running local redis servers proved to improve both latency and system availability since it reduces read load on Cassandra.
The Final Aryabhata Architecture
The image below shows our full Leaderboard architecture:
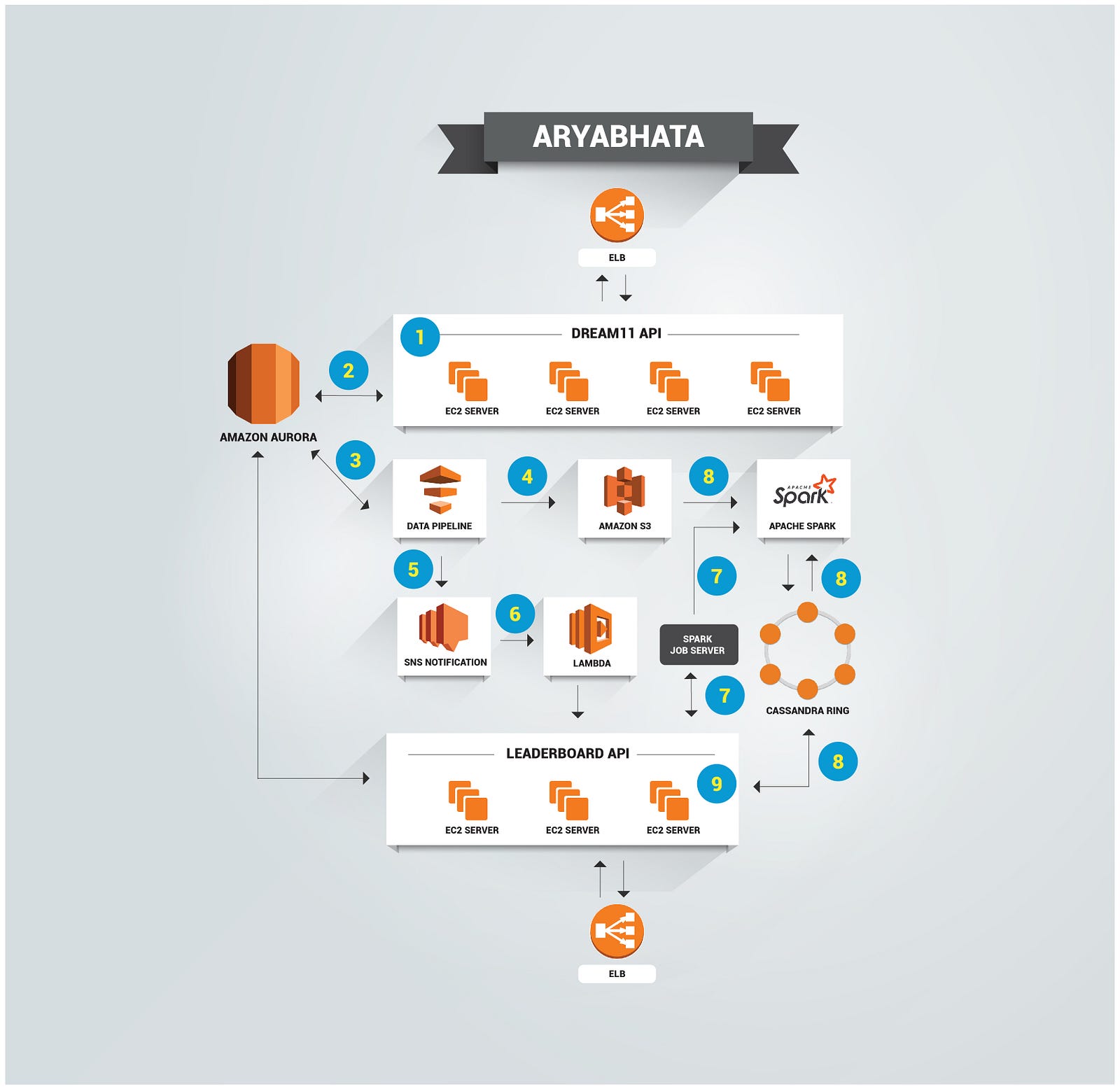
- Dream11 API is an edge service that serves all requests
- Resources consumed and created are saved to mysql database
- After match deadline, data is fetched from mysql to s3 via Amazon Data pipeline
- Data Pipeline saves all contest related information to s3
- Data pipeline sends an SNS notification on completion of data transfer
- SNS triggers a lambda function which makes an api call to Leaderboard api
- Leaderboard service schedules data loading spark job on spark cluster using Spark Job Server.
- Spark reads contest data from S3 and saves it to cassandra after processing. Data is ready to serve
- Leaderboard service connects to cassandra for showing contest detail views as explained earlier.
Increasing the lead — how we’re moving forward
- Distributing Cassandra Load
Cassandra stands at the heart of our Leaderboard system. It stores every mutation result and also supports real time queries. Although Cassandra is designed for no single point of failure; huge read/write loads sometimes limit throughput from a single partition. A simple solution to the problem could be separation of read and write. Cassandra supports multiple strategies for maintaining replication across two ring clusters. In the above strategy, one ring could only accept write, while reads could be served from the other ring. We would like to explore this strategy after conducting some experiments with consistency and latency.
2. Personalising Journey Graphs
Leaderboard service persists every version of the Leaderboard state, each being a representation of a corresponding real world event. We can use this data to create a feature displaying a journey graph for a user for a particular match. Journey Graphs would be just personification of how user ranks travelled during game events. This will enable users to see a trend of their ranks during/after the match, adding transparency and help build trust.
3. Enhancing our Event Generation Model
Currently, the Leaderboard api works in pull mode where the clients constantly keep polling for new events to fetch latest data. To reduce latency and enhance user experience in the future, we would like to implement a push model. In this model, the Leaderboard service pushes events to client notifying new score update, greatly reducing the time between an actual event and corresponding update of points in the frontend. This will enable the view on the frontend to be auto-refreshed as soon as the new data is ready.
4. Optimising Data Mining Processes
Data is the new gold and with Leaderboard architecture, we generate huge dataset that provides great insight about the match as well as user behaviour. The data science team hopes to analyze this data and run experiments to come up with informed product behaviour adding to richer user experience.












