The Curious Case Of Tombstones
The dead are harmless, one would think but not quite so incase of noSQL database Cassandra !
One of the biggest puzzles so far in my two years of working with Cassandra, has been tombstones. Unlike relational databases like Oracle, MySQL, etc, delete operation in Cassandra does not really snuff the data away rather it creates dead records called “tombstones” which stay along with the data till they get evicted by compaction depending on a few settings defined at the column family level and the yaml file. If not cleared, they can impact the health of the cluster in many ways. Some of the most obvious ones being
- Increase in read latency as a read operation will have to read all the live and the dead rows and then filter out the dead ones.
- Occupy space, which can be an issue depending on the infra that C* is set up on.
- Danger of data resurrection
In this blog post, I intend to share how we dealt with tombstone issues and reclaimed space in our cluster.
We started our Cassandra journey three years ago, as part of a big project to move our Enterprise platform to cloud Native architecture. Cassandra was selected as the preferred no-SQL database and it completely replaced Oracle. It was a big change and the migration journey was quite challenging.Three years down the line, the platform is nearing full adoption and supports high revenue generating applications which are mission critical to the company.
Due to the evolving and iterative development of the system, there had been no purge done on the transactions data. Also the complex business rules made it difficult to make use of Cassandra’s TTL (Time –To-Live) functionality which allows to write transactions with an auto expiry time. Every type of transaction has different purge rules, so we ended up with a situation of dealing with a huge number of deletes in the first pass of the purge run. Almost 60% of data in column families met the purge rules.
Since Cassandra delete is actually an upsert statement in disguise, it essentially translates to a momentary increase in the db storage space until the gc_grace_seconds value is reached and compaction removes the tombstones. However, this was not the case. I carried out the purge in various phases, purging a certain number of records each day and monitoring the space before and after every purge run. The records were getting deleted and tombstones were also created, but there was neither an increase nor a decrease in the space.
We have analytics jobs which read all data from Cassandra and push it out to other systems like Kafka, Tableau and Elastic Search for analysis and reporting (more on that use case in a future blog) , so it was very essential for us to remove the unwanted tombstones.
For faster tombstone eviction, the gc_grace_seconds on the column families was altered to 4 days from the default value of 10 days. Repair jobs were also scheduled every 3 days but even after all the records were purged and the gc_grace_seconds had elapsed, there was no change in space.
An examination of the sstablesmetadata revealed that the droppable tombstone value was 0.02, and the tombstone_threshold was the default value of 0.2.
Estimated droppable tombstones: 0.02039067027235851
This meant that we were pretty far from the threshold value of the tombstones being removed by compaction.
All the Column families that were being purged had LCS (Leveled Compaction Strategy).We also played around with column family settings to see if space would be reclaimed. But lowering the tombstone threshold to a value of 0.01 (lower than Estimated droppable tombstones), or modifying the unchecked_tombstone property made no difference.
We then decided to try out a newer garbage collect command that was introduced by Datastax in version 5.1 and above. Steps followed for this were :
- Lower gc_grace_seconds on column families to half a day.
- Run garbage collect command
nodetool garbagecollect keyspace cf -j 0
- Monitor in ops center. The above command triggers the below compaction jobs
“Remove deleted data of keyspace.cf”
- Run a repair after garbage collect job is run. Repair can be run just on the specific column families which were purged.
“nodetool repair -pr -full keyspace cf1 cf2 cf3”
- Revert the gc_grace_seconds value to the original one.
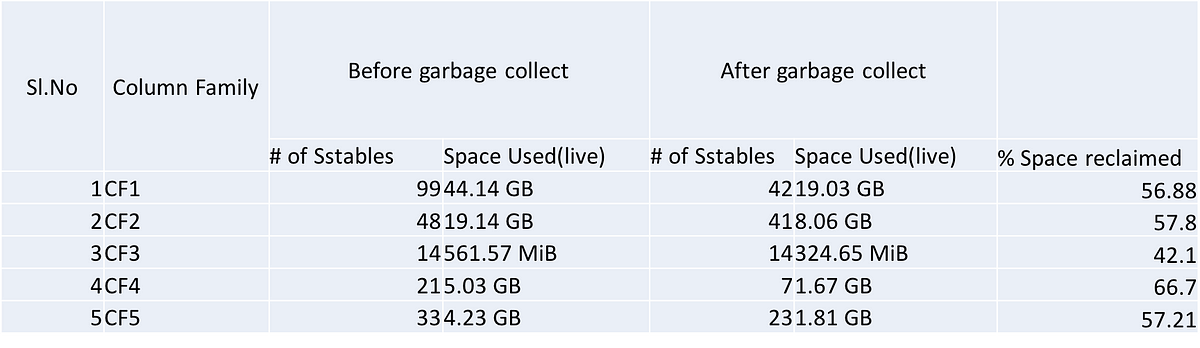
And ta-da, we were able to reclaim the space!! Like I mentioned above, 60% of our transactions’ data got purged so the amount of space reclaimed was significant. Given below is the actual stats (from one of our transactional nodes) of this whole exercise. The column family names have been altered.
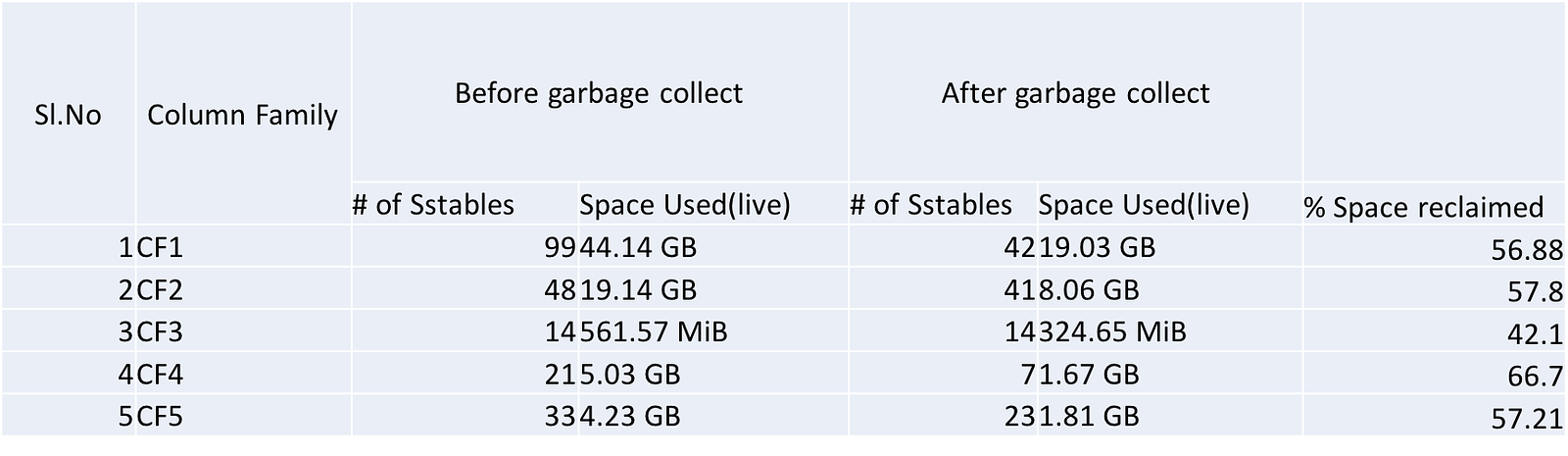
One important thing to note here is, the garbage collect command is per node so if there are multiple nodes of C* in a cluster, the above steps need to be performed on every node. We have a multi node and multi DC cluster, so the process was definitely time consuming but totally worth it.
For the long term, once this massive purge is completed on all key spaces of the cluster we plan to move some of our Column Families to STCS (Size tiered compaction Strategy) as STCS is more suited to our workload which is 50–50 read vs write and the fact that there is going to be a regular purge going forward.
I would love to hear about similar problems/experiences that users of Cassandra have had and how they dealt with it.