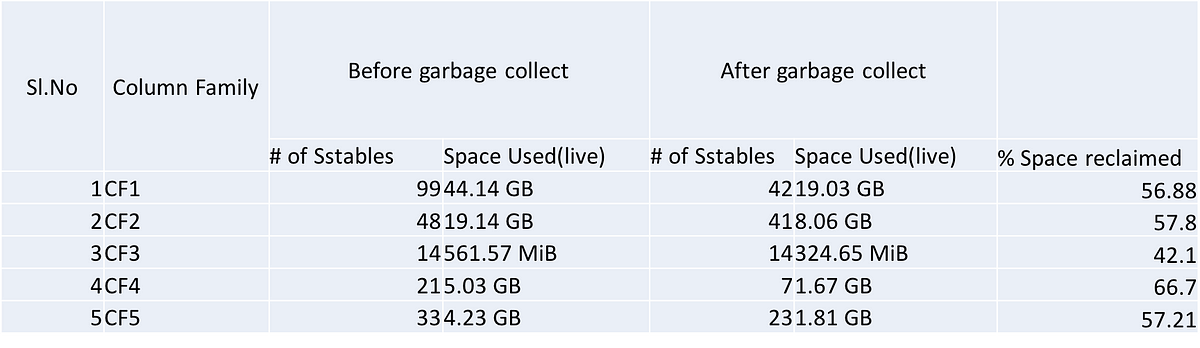
Data structures are a way of storing and organizing data so it can be easily retrieved and accessed when needed. They often build on each other to create new structures, and programmers can adopt those that best fit a given data access pattern.
Generally, programmers and analytics teams can use prebuilt standard libraries for data structures rather than programming their own. However, understanding data structures helps database administrators (DBAs) and analytics teams optimize databases and choose the best tool sets for their big data environment.
Table of Contents
Types Of Data Structures
Just as there are multiple types of big data technologies, there are different structures, each offering unique benefits and challenges. Choosing the most efficient data structure for the job significantly improves algorithm performance, which accelerates application processing speeds—in turn enabling computing systems to manage vast amounts of information within massive databases, large-scale indexing, and structured data in big data platforms.
Primitive, Simple, and Compound Data Structures
These categories build on one another, going from primitive to simple to compound:
- Primitive data structures/types—The basic building blocks of data structures, these include integers, floats, and doubles, which represent numbers with or without decimal points; characters, which are self-explanatory, strings, which represent a group of characters; and Boolean, which represents logical (true or false) values.
- Simple data structures—These build on primitive data types to create higher-level structures. The most common simple data structures are arrays and linked lists.
- Compound data structures—These build on primitive and simple data structures and may be linear or nonlinear. Linear data structure forms a sequence with unique predecessors and successors, while nonlinear data structure does not create linear sequences. The nonlinear tree structure builds on hierarchical relationships.
Set-Like Access, Key-Based Access, and Restricted Access Data Structures
Another common method of categorizing data structure is by access function types:
- Set-like access—These enter and retrieve data items from structures that may contain non-unique elements, including sets, link lists, and some trees.
- Key-based access—These store and retrieve data items using unique keys, including arrays, hash tables, and some trees.
- Restricted access—These are data structures that control the time and order of data item access, including stacks and queues.

Simple Data Structures
Simple data structures expand on primitive data types to create higher-level structures.
Arrays
The array data structure is one of the oldest and most common types. An array consists of elements that may be values or variables—the structure identifies them using an index or key, enabling the data structure to compute the location of each component. The initial element’s memory address is called the foundation or first address. Data elements are indexed and sequentially stored in contiguous memory.
There are many types of array data structures. Many databases use one-dimensional linear arrays whose elements are the database records. Arrays may also be multidimensional if they access elements from more than one index. In either form, arrays are the foundation for many other data structures, including hash tables, queues, stacks, and linked lists.
Linked List
A linked list is the second most common type of data structure. It links elements instead of computing addresses from pointers. While an array mathematically computes data item addresses, linked lists store them within their own structure. It treats each element as a unique object that contains the data and the reference or address of the next one.
There are three types of linked lists: singly linked, doubly linked, and circular-linked. In singly linked lists, each node stores the next node’s address and the end address is null. In doubly linked lists, each node stores the previous and next node’s addresses and the end address is null. In circular linked lists, each node links to the other in a circle and there is no ending null.
Compound Data Structures
Computing systems combine simple data structures to form compound ones. They may be linear or nonlinear. Linear data structures form sequences, while nonlinear structures are multileveled and non-sequential.
Stack
A stack is a basic linear data structure—a logical entity pictured as a physical stack or pile of objects. The data structure inserts and deletes elements at one end of the stack, called the top. Programmers develop a stack using an array and linked list.
A stack follows the order in which the computing system performs operations. The order is usually Last In First Out (LIFO). The primary functions for stack include Push, which adds an item to the stack, and Pop, which removes things in reverse order to a Push. Stack also returns an empty value: “true” on an empty stack and “false” if there is data.
Queue
Instead of the stack LIFO order, the queue data structure places elements in First In First Out (FIFO) order. The insertion procedure is called Enqueue, which inserts an element in the rear or tail of the queue.
The deletion procedure is called Dequeue, which removes elements from the front or head of the line. To move the inserted element to the front of the line to be Dequeued, the stack data structure must remove all elements between the new entry and the front of the queue.
Think of this structure in terms of a printer queue, where jobs occur in order until they’re printed or canceled. A queue can be built using an array, linked list, or stack.
Graph
The nonlinear graph data structure is a type of tree that presents a mathematical image of an object set with linked pairs. The interconnected object points are vertices and the links are edges.
Hash Table
Hashing converts key value ranges into index ranges within an array. The nonlinear hash table data structure associates each value with a unique index that records its insertion point and location, accelerating data ingress and searches.
Hash collisions are a common occurrence, especially when hashing large data stores. Most hash tables include collision resolution, often separately storing keys/key pointers along with their associated values.
Tree
Nonlinear trees are hierarchical data structures. They are typically built from the top down, where each node contains a unique value and references to child nodes. In any type of tree, no node points back to the root or duplicates a reference.
The top node is called the root. The elements directly underneath are its children, and same-level elements are siblings. If there is a level below these children, the upper nodes are also parents. Elements occurring at the bottom of the tree are called leaves.
The purpose of a tree is to store naturally hierarchical information, such as a file system. There are multiple types of trees. A Binary tree is a data structure where each node has no more than two children, respectively called the right and left child.
Additional structures are the Binary tree, often used to efficiently store router tables for high-bandwidth routers, or the Merkel tree, which hashes the value of each child tree within its parent node. Merkel enables databases like NoSQL Apache Cassandra to verify large data contents efficiently.

Linear vs. Nonlinear Data Structures
Across all their specific forms, linear and nonlinear data structures have some key differences to note. Linear structures form sequences, meaning each element links to those behind and ahead of it. The biggest effect of this linearity is that users can work through every element in a single pass.
That streamlining and simplicity make these structures relatively easy to implement. The main downside is that the structure’s complexity directly reflects its size. A larger input will be more complex, so users can quickly encounter memory problems with additional data.
Nonlinear data structures, by contrast, place elements in a hierarchy or at random. They use multiple levels and branching areas, making it impossible to traverse all elements in one run. As a result, implementing them is more challenging, but if done correctly, they’re more memory-efficient and can minimize complexity at larger inputs.
Given these differences, the best type depends on the project. Linear structures are best for simpler app development and teams with minimal data science experience. Nonlinear alternatives are better for more complex AI applications.
Bottom Line: Organizing Information with Data Structures
Data is a critical resource for any business, and ongoing successes often hinge on an organization’s ability to understand and apply it. Knowing the strengths and weaknesses of various data structures provides a crucial edge in those efforts.
Companies that understand different structures and how to use them can optimize their data workflows more accurately. That optimization will become increasingly important as database volumes grow and artificial intelligence (AI) plays a more central role in business.
Read 10 Best Practices for Effective Data Management to learn tips and techniques for a successful enterprise data program.