Successfully reported this slideshow.

Upcoming SlideShare
Loading in …5
×
No Downloads
No notes for slide
Volume : Terabytes, Records, Transactions, Tables, filesVelocity : Batch, Near real time, realtime
Variety : Structured, unstructured, semi structuredVertical scaling means that you scale by adding more power (CPU, RAM) to an existing machine.
In vertical-scaling the data resides on a single node and scaling is done through multi-core i.e. spreading the load between the CPU and RAM resources of that machine.
Horizontal scaling means that you scale by adding more machines into your pool of resources.In a database horizontal-scaling is often based on partitioning of the data
i.e. each node contains only part of the data.
With horizontal-scaling it is often easier to scale dynamically by adding more machines into the existing pool.
If a cluster requires more resources to improve performance and provide high availability (HA), an administrator can scale out by adding more machine to the cluster.Scalability : Hyper scale, load balancing, scale out.
Availability : Failure resilient, rolling updates, recovery from failures.
Manageability : Granular versioning, micro service Responsive: The system responds in a timely manner if at all possible.
Resilient: The system stays responsive in the face of failure. This applies not only to highly-available, mission critical systems — any system that is not resilient will be unresponsive after a failure.
Elastic: The system stays responsive under varying workload. Reactive Systems can react to changes in the input rate by increasing or decreasing the resources allocated to service these inputs.
Message Driven: Reactive Systems rely on asynchronous message-passing to establish a boundary between components that ensures loose coupling, isolation and location transparency.
33TB Monthly 1.1 TB daily
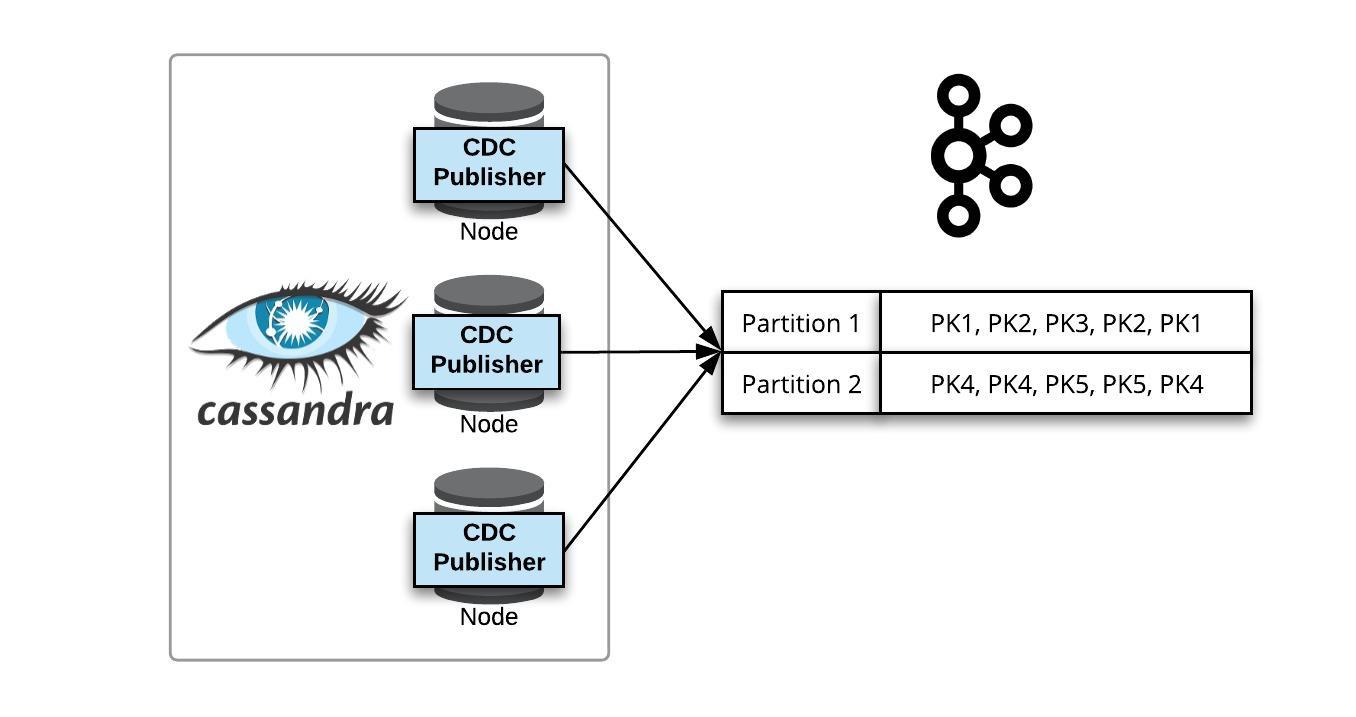
The distributed storage system Cassandra, for example, runs on top of hundreds of commodity nodes spread across different data centers. Because the commodity hardware is scaled out horizontally, Cassandra is fault tolerant and does not have a single point of failure (SPoF).Cassandra supports a per-operation tradeoff between consistency and availability through Consistency Levels.The following consistency levels are available:
ONE : Only a single replica must respond.
TWO :Two replicas must respond.
THREE : Three replicas must respond.
QUORUMA : majority (n/2 + 1) of the replicas must respond.
ALL :All of the replicas must respond.
LOCAL_QUORUMA :majority of the replicas in the local datacenter (whichever datacenter the coordinator is in) must respond.
EACH_QUORUMA : majority of the replicas in each datacenter must respond.
LOCAL_ONE : Only a single replica must respond. In a multi-datacenter cluster, this also gaurantees that read requests are not sent to replicas in a remote datacenter.
ANY : A single replica may respond, or the coordinator may store a hint. If a hint is stored, the coordinator will later attempt to replay the hint and deliver the mutation to the replicas. This consistency level is only accepted for write operations.
Stateful exactly-once semantics out of the box.
Spark Streaming recovers both lost work and operator state (e.g. sliding windows) out of the box, without any extra code on your part.
sc.cassandraTable("keyspace name", "table name")- 1. Rahul Kumar Technical Lead Sigmoid Real Time data pipeline with Spark Streaming and Cassandra with Mesos
- 2. About Sigmoid © DataStax, All Rights Reserved. 2 We build reactive real-time big data systems.
- 3. 1 Data Management 2 Cassandra Introduction 3 Apache Spark Streaming 4 Reactive Data Pipelines 5 Use cases 3© DataStax, All Rights Reserved.
- 4. Data Management © DataStax, All Rights Reserved. 4 Managing data and analyzing data have always greatest benefit and the greatest challenges for organization.
- 5. Three V’s of Big data © DataStax, All Rights Reserved. 5
- 6. Scale Vertically © DataStax, All Rights Reserved. 6
- 7. Scale Horizontally © DataStax, All Rights Reserved. 7
- 8. Understanding Distributed Application © DataStax, All Rights Reserved. 8 “ A distributed system is a software system in which components located on networked computers communicate and coordinate their actions by passing messages.”
- 9. Principles Of Distributed Application Design © DataStax, All Rights Reserved. 9 Availability Performance Reliability Scalability Manageability Cost
- 10. Reactive Application © DataStax, All Rights Reserved. 10
- 11. Reactive libraries, tools and frameworks © DataStax, All Rights Reserved. 11
- 12. Cassandra Introduction © DataStax, All Rights Reserved. 13 Cassandra - is an Open Source, distributed store for structured data that scale-out on cheap, commodity hardware. Born at Facebook, built on Amazon’s Dynamo and Google’s BigTable
- 13. Why Cassandra © DataStax, All Rights Reserved. 14
- 14. Highly scalable NoSQL database © DataStax, All Rights Reserved. 15 Cassandra supplies linear scalability Cassandra is a partitioned row store database Automatic data distribution Built-in and customizable replication
- 15. High Availability © DataStax, All Rights Reserved. 16 In a Cassandra cluster all nodes are equal. There are no masters or coordinators at the cluster level. Gossip protocol allows nodes to be aware of each other.
- 16. Read/Write any where © DataStax, All Rights Reserved. 17 Cassandra is a R/W anywhere architecture, so any user/app can connect to any node in any DC and read/write the data.
- 17. High Performance © DataStax, All Rights Reserved. 18 All disk writes are sequential, append-only operations. Ensure No reading before write.
- 18. Cassandra & CAP © DataStax, All Rights Reserved. 19 Cassandra is classified as an AP system System is still available under partition
- 19. CQL © DataStax, All Rights Reserved. 20 CREATE KEYSPACE MyAppSpace WITH REPLICATION = { 'class' : 'SimpleStrategy', 'replication_factor' : 3 }; USE MyAppSpace ; CREATE COLUMNFAMILY AccessLog(id text, ts timestamp ,ip text, port text, status text, PRIMARY KEY(id)); INSERT INTO AccessLog (id, ts, ip, port, status) VALUES (’id-001-1', 2016-01-01 00:00:00+0200', ’10.20.30.1’,’200’); SELECT * FROM AccessLog ;
- 20. Apache Spark © DataStax, All Rights Reserved. 21 Introduction Apache Spark is a fast and general execution engine for large-scale data processing. Organize computation as concurrent tasks Handle fault-tolerance, load balancing Developed on Actor Model
- 21. RDD Introduction © DataStax, All Rights Reserved. 22 Resilient Distributed Datasets (RDDs), a distributed memory abstraction that lets programmers perform in-memory computations on large clusters in a fault-tolerant manner. RDD shared the data over a cluster, like a virtualized, distributed collection. Users create RDDs in two ways: by loading an external dataset, or by distributing a collection of objects such as List, Map etc.
- 22. RDD Operations © DataStax, All Rights Reserved. 23 Two Kind of Operations • Transformation • Action
- 23. What is Spark Streaming? © DataStax, All Rights Reserved. 26 Framework for large scale stream processing ➔ Created at UC Berkeley ➔ Scales to 100s of nodes ➔ Can achieve second scale latencies ➔ Provides a simple batch-like API for implementing complex algorithm ➔ Can absorb live data streams from Kafka, Flume, ZeroMQ, Kinesis etc.
- 24. Spark Streaming © DataStax, All Rights Reserved. 27 Introduction • Spark Streaming is an extension of the core spark API that enables scalable, high-throughput, fault- tolerant stream processing of live data streams.
- 25. Spark Streaming over a HA Mesos Cluster © DataStax, All Rights Reserved. 31 To use Mesos from Spark, you need a Spark binary package available in a place accessible (http/s3/hdfs) by Mesos, and a Spark driver program configured to connect to Mesos. Configuring the driver program to connect to Mesos: val sconf = new SparkConf() .setMaster("mesos://zk://10.121.93.241:2181,10.181.2.12:2181,10.107.48.112:2181/mesos") .setAppName(”HAStreamingApp") .set("spark.executor.uri","hdfs://Sigmoid/executors/spark-1.6.0-bin-hadoop2.6.tgz") .set("spark.mesos.coarse", "true") .set("spark.cores.max", "30") .set("spark.executor.memory", "10g") val sc = new SparkContext(sconf) val ssc = new StreamingContext(sc, Seconds(1))
- 26. Spark Cassandra Connector © DataStax, All Rights Reserved. 32 It allows us to expose Cassandra tables as Spark RDDs Write Spark RDDs to Cassandra tables Execute arbitrary CQL queries in your Spark applications. Compatible with Apache Spark 1.0 through 2.0 It Maps table rows to CassandraRow objects or tuples Do Join with a subset of Cassandra data Partition RDDs according to Cassandra replication
- 27. © DataStax, All Rights Reserved. 33 resolvers += "Spark Packages Repo" at "https://dl.bintray.com/spark-packages/maven" libraryDependencies += "datastax" % "spark-cassandra-connector" % "1.6.0-s_2.10" build.sbt should include: import com.datastax.spark.connector._
- 28. © DataStax, All Rights Reserved. 34 val rdd = sc.cassandraTable(“applog”, “accessTable”) println(rdd.count) println(rdd.first) println(rdd.map(_.getInt("value")).sum) collection.saveToCassandra(“applog”, "accessTable", SomeColumns(”city", ”count")) Save Data Back to Cassandra Get a Spark RDD that represents a Cassandra table
- 29. Many more higher order functions: © DataStax, All Rights Reserved. 35 repartitionByCassandraReplica : It be used to relocate data in an RDD to match the replication strategy of a given table and keyspace joinWithCassandraTable : The connector supports using any RDD as a source of a direct join with a Cassandra Table
- 30. Hint to scalable pipeline © DataStax, All Rights Reserved. 36 Figure out the bottleneck : CPU, Memory, IO, Network If parsing is involved, use the one which gives high performance. Proper Data modeling Compression, Serialization
- 31. Thank You @rahul_kumar_aws
Public clipboards featuring this slide
No public clipboards found for this slide