The past 10 years have seen the explosive growth of large-scale distributed systems. This trend has produced a whirlwind of creativity in the database world that is arguably without precedent in the history of the software industry. The result is a healthy and competitive database marketplace with an enormous variety of platforms for us to choose from. But how do we go about making those choices?
In this article, we’ll explore how you can go about choosing the right database models for your application. (Yes, there can be more than one!) We’ll also look at how your choice of data models can help determine which technologies to include in your data tier.
Cloud architecture, NoSQL, and microservices
As software developers began to create web-scale applications, the relational databases that have historically dominated our data architectures began to show a lot of strain. We developed hugely popular social applications, and began connecting more and more devices to the Internet of Things (IoT). The massive number of clients reading and writing data led to the need to scale out the data tier, and new kinds of databases emerged to address these high scalability needs.
In many cases these new databases were “NoSQL” or “non-relational”—solutions based on data models other than that dominant relational model, such as document, key-value, column oriented, and even graph databases. Frequently these databases sacrificed some of the familiar guarantees of relational databases like strong consistency, ACID transactions, and joins.
At the same time as this revolution in database technology, the SOA (service-oriented architecture) trend of the early 2000s was maturing into the microservices architectural style, as many organizations began to move away from heavyweight SOA infrastructures such as the enterprise service bus (ESB) toward a more decentralized approach. The appeal of microservices architecture lies in the ability to develop, manage and scale services independently. This gives us a ton of flexibility in terms of implementation choices, including infrastructure technology such as databases.
As an example, let’s assume we’re undertaking a significant development effort for a microservices architecture where we’re anticipating large scalability demands. Whether the project is a new application or the refactoring of an existing application, we have the opportunity to make new database choices.
Polyglot persistence
One key benefit of the microservices style is the encapsulation of persistence—we are free to select a different persistence technology according to the needs of each service. The approach of selecting data stores according to the characteristics of each data type is known as polyglot persistence, a term popularized by Martin Fowler and others. Polyglot persistence is a natural fit for microservices.
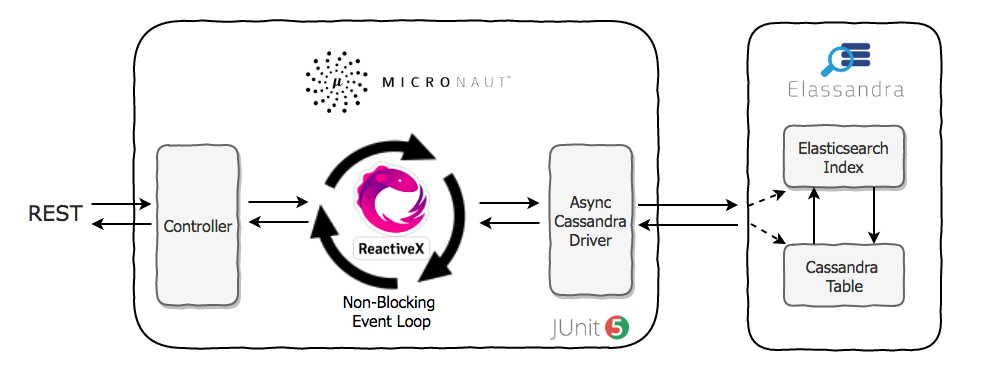
The figure below shows an example of a set of microservices and how we might use a different data model for each service. I’m not trying to enumerate every appropriate use case for each type of database here. My intent is to highlight the strengths of each of these types of database and why the polyglot approach can be attractive.
 DataStax
DataStax
The team developing Service A might choose to use a tabular database such as Apache Cassandra because it is managing core application data at large scale. For example, inventory data for a retail application might be a very good fit for Cassandra’s tabular format. Cassandra provides a toolbox of coordination mechanisms such as tune-able consistency, batches, and lightweight transactions as an alternative to full-scale ACID transactions.
Perhaps Service B supports very simple semantics of looking up reference values by well-known keys, for example descriptive data for a product catalog. This is a good case for a key-value store, where we look up a blob of data by a well-known key value such as a product ID. Many in-memory caches use a key-value data model to support extremely fast read access at scale.
Service C might be primarily concerned with serving up semi-structured content such as pages or forms for a website, and a document store could be a great fit for that data. A document store has many similarities to the key-value style, but one key difference is the ability to impose some structure on the data, for example the ability to index on specific attributes to support fast searches.
Service D might involve navigating complex relationships between data such as customer data and the history of customer contacts with various departments in the organization. This could potentially involve relationships between data types owned by other services. This is an interesting case, since it begins to push against that constraint referenced above of having services own individual data types. In this case, you may choose to have your service create a graph with read-only access to the underlying tables, and then funnel any desired mutations through the “front door” – i.e., via calls to the APIs of the other services which “own” those data types.
Finally, we might also have a legacy system or services that use relational technology, or perhaps we have a service that manages a lower volume of data, or data that doesn’t change often. A relational database may be perfectly adequate for those use cases.
Should an individual service be polyglot?
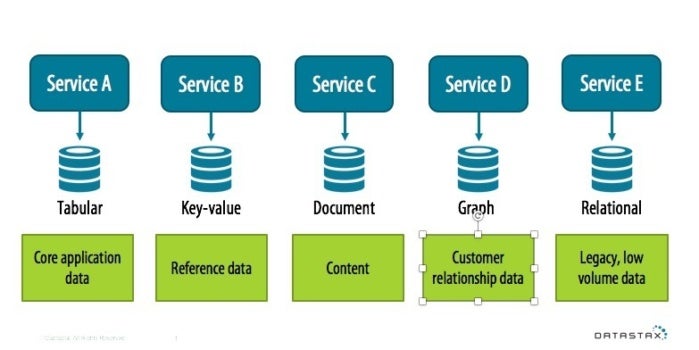
It’s also possible that we could design a service that sits on top of multiple databases. For example, we could create a Hotel Service that used a key-value store as an index, mapping between hotel names and IDs, while storing the descriptive data about a hotel in Cassandra’s tabular format.
 DataStax
DataStax
Note that the name-to-ID mapping could be accomplished equally well in Cassandra by using a denormalized design approach, in which a separate table is used to maintain the name-to-ID mapping. This uses a bit more storage but saves us the operational complexity of managing a separate key-value store.
This is my typical recommendation — that a given microservice stick to a single data model (and database) whenever feasible. If you find a situation in which you feel that a single service needs to sit on top of two different databases, consider whether the scope of that service might be getting too large. You might want to consider splitting that service into smaller services.
Limitations and tradeoffs of polyglot persistence
The main drawback of polyglot persistence is the cost of supporting multiple technologies, both in terms of initial development and operations.
The primary development cost is the cost of training up developers on each new database technology. This can be significant, especially if you are in a more fluid environment where developers change teams frequently.
The other driver is the operational cost of supporting multiple databases. This can be a problem when database management is centralized and that team must maintain a high level of competence in multiple technologies, but it may be less of a problem in a true devops shop where development teams have to support the databases they select in production.
Multi-model databases
Database vendors have begun to build and promote multi-model databases as an alternative or complement to the polyglot persistence approach. The term “model” references the primary abstraction provided by a data store, such as tabular (both relational and non-relational), column store, key-value, document, or graph. We can think of a multi-model application as one that uses more than one type of data store, while a multi-model database is one that supports more than one abstraction.
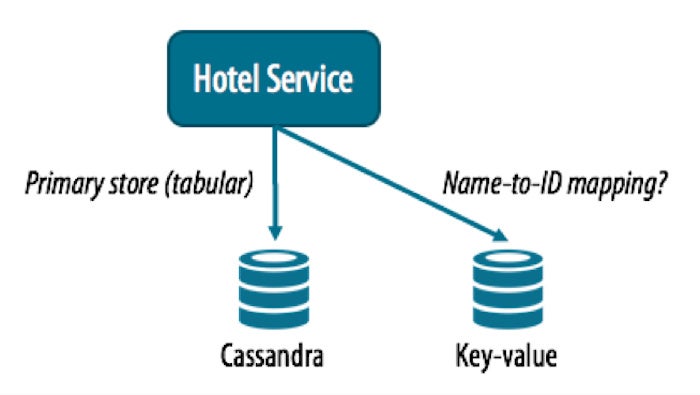
DataStax Enterprise (DSE) is an example of a multi-model database, since at its core it supports Cassandra’s partitioned row store (tabular) model, with a graph abstraction built on top of that (DSE Graph). It is also simple to build your own key-value and document style abstractions on top of the core model, as shown in the figure below. In this way, we could modify the polyglot approach shown above to leverage a single underlying database engine for all of our services, while using separate Cassandra keyspaces to maintain clear boundaries between data owned by different services.
 DataStax
DataStax
Here’s how it would work:
- Tabular: Our primary application services like Service A could interact with DSE database directly using the Cassandra Query Language (CQL).
- Key-value: Although neither the Apache nor DataStax distributions of Cassandra provide an explicit key-value API, services like Service B can interact with Cassandra as a key-value store by constraining the table design to support only key and value columns. For example:
CREATE TABLE hotel.hotels (
key uuid PRIMARY KEY,
value text); // or if you prefer, “blob”
- Document: Cassandra supports document-style interaction in terms of JSON documents, which could be used by services like Service C. Note that because Cassandra does require a schema for tables, you cannot insert arbitrary JSON that defines new columns on the fly, which is a characteristic that one might typically associate with document databases.
- Graph: For services that support highly interconnected data like Service D, DSE Graph is a highly scalable graph database that is built directly on top of DSE database. DSE Graph supports the powerful and expressive Gremlin API from the Apache TinkerPop project.
Advantages and limitations of a multi-model database
In considering whether to invest in a multi-model database (or use multi-model features of a database you already have in place), you’ll want to consider the same development and operational costs we discussed above regarding the polyglot persistence approach.
Using a multi-model database can help with operational simplicity. Even if different development teams are using different APIs and modes of interaction with the back-end database platform, we gain efficiency by only having a single platform to manage.
One thing to consider in selecting a multi-model database is how the various models are supported. A common approach consists of a database engine based on a single native underlying model, with other models layered on top of that. The layered data models are likely to exhibit characteristics of that underlying primary model.
For example, ThoughtWorks Technology Radar Vol. 16 discusses the characteristics that DSE Graph demonstrates as a graph model layered on top of Cassandra and the tradeoffs involved:
Built on top of Cassandra, DSE Graph targets the type of large data sets where our longtime favorite Neo4j begins to show some limitations. This scale has its trade-offs; for example, you lose the ACID transactions and run-time schema-free nature of Neo4j, but access to the underlying Cassandra tables, the integration of Spark for analytical workloads, and the powerful TinkerPop/Gremlin query language make this an option worth considering.
If you consider the various data types in your web-scale application, you’re likely to find that the different data types have different consistency needs, and that the number of data types that actually require immediate consistency are relatively few.
The quote highlights another important consideration in the multi-model space — the integration and interaction between the different models and engines, and the various operational and analytic use cases for accessing your data. DSE supports the ability to access graph data via Spark (DSE Analytics) for analytic purposes, and DSE Search provides the ability to create a variety of search indexes for data stored in DSE database.
Microservices data models in four steps
Now that we’ve considered the merits of polyglot and multi-model approaches, how should we go about deciding on which data models to use for a large-scale microservices application? Follow these steps:
- Identify the major data types in your application, creating a service for each and giving each service control over its own persistence. Where possible, leverage a multi-model database for all services, allowing services to vary in what model they choose to interact with data.
- Use a tabular representation (i.e. DSE database) as your primary model for web-level scalability and availability, layering key-value and document semantics on top of this as needed. Make sure to consider the various ways in which your data will be accessed for both operational and analytic use cases so that you can plan ahead of time on how you will use features like search indexes and replication to analytic data centers.
- Use a graph representation (i.e. DSE Graph) for highly relational data, especially in cases where the relationships between entities have as many or more attributes than the entities themselves, or you need to capture multiple relationships between the same entities.
- Preserve legacy investments in relational/SQL technology when you don’t have to make a change. For example, when your use case doesn’t require large scale, low latency, and high availability.
I hope this gives you a useful framework to think about how and where to support multiple models in your application, and when to consider using a multi-model database.
Jeff Carpenter is a technical evangelist at DataStax, where he leverages his background in system architecture, microservices, and Apache Cassandra to help empower developers and operations engineers build distributed systems that are scalable, reliable, and secure. Jeff is the author of Cassandra: The Definitive Guide, 2nd Edition.
—
New Tech Forum provides a venue to explore and discuss emerging enterprise technology in unprecedented depth and breadth. The selection is subjective, based on our pick of the technologies we believe to be important and of greatest interest to InfoWorld readers. InfoWorld does not accept marketing collateral for publication and reserves the right to edit all contributed content. Send all inquiries to newtechforum@infoworld.com.