Editor’s Note: The following article is adapted from Cassandra: The Definitive Guide (3rd Ed., O'Reilly), by Jeff Carpenter and Eben Hewitt, with permission of O'Reilly Media: https://dtsx.io/oreilly
Over the past several years, the microservice architectural style has been foundational to the discipline of cloud-native applications. As a database designed for the cloud from the ground up, Apache Cassandra is a natural fit for cloud-native applications.
In this Refcard, we explore techniques for developing Cassandra data models and designing microservices based on those models for a sample application used to manage hotel reservations.
This is a preview of the Designing Microservices With Cassandra Refcard. To read the entire Refcard, please download the PDF from the link above.
We will start our discussion by referencing a subset of the basic principles of microservice architecture that are introduced in Sam Newman’s book, Building Microservices (O’Reilly), an excellent source on this topic.
Encapsulation
Encapsulation could also be phrased as “services that are focused on doing one thing well” or the “single responsibility principle.” In a microservice architecture, this means that each service should manage its own data storage and not access data stores managed by other services.
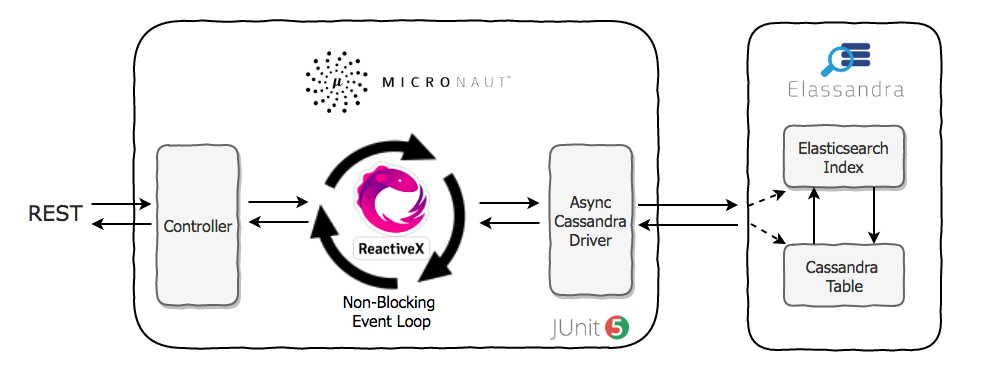
By contrast, in many enterprises, the database serves as a central integration point. An application might expose interfaces to other applications such as remote procedure call (RPC) or messaging interfaces. It’s also common for one application to access another application’s database directly, which violates encapsulation and produces dependencies between applications that can be difficult to isolate and debug (see Figure 1).
Figure 1: Integration by database contrasted with microservices
Autonomy
In a microservice architecture, autonomy refers to the ability to independently deploy each microservice without dependence on any other microservices. This flexibility has significant advantages in allowing you to independently evolve portions of a deployed application without downtime, gradually introducing new versions of a service and minimizing the risk of these deployments.
Another implication of autonomy is that each microservice can have its own data store using the most appropriate technology for that service. We’ll examine this flexibility in more detail below.
Scalability
Microservice architecture provides a lot of flexibility by enabling you to run more or fewer instances of a service dynamically according to demand. This allows you to scale different aspects of an application independently.
For example, in a hotel domain there is a large disparity between shopping (the amount of traffic looking for hotel rooms) and booking (the much lower level of traffic committing to a reservation). For this reason, you might expect to scale the services associated with hotel and inventory data to a higher degree than the services associated with storing reservations.
This is a preview of the Designing Microservices With Cassandra Refcard. To read the entire Refcard, please download the PDF from the link above.
To create a microservice architecture for an application, you’ll need to identify services, their interfaces, and how they interact. Although written well before microservices became popular, Eric Evans’ book, Domain-Driven Design (Addison-Wesley Professional), has proven to be a useful reference.
One of the key principles that Evans articulates is beginning with a domain model and identifying bounded contexts. This process has become a widely recommended approach for identifying microservices. For Cassandra, the recommended method for data modeling is to use a query-driven approach to identify tables.
For example, after identifying the key entities in a domain by creating a conceptual data model, you can analyze the anticipated workflows of the application to identify how the entities will be read by the application. The resulting queries are used to identify the tables that will be created, which can be documented in logical and physical data models.
The resulting queries are used to identify the tables that will be created, which can be documented in logical and physical data models. You can see an example of how this process works in Chapter 5 of Cassandra: The Definitive Guide, which is freely available as part of the Cassandra project documentation.
To define a microservice architecture, use a process that complements these data modeling processes. As you begin to identify entities as part of a conceptual data modeling phase, you can identify bounded contexts that represent groupings of related entities.
As you progress into logical data modeling, you refine the bounded contexts to identify specific services that will be responsible for each table (or group of related, denormalized tables). During the final stage of the design process, you confirm the design of each service, database selection, physical data models, and actual database schema.
This is a preview of the Designing Microservices With Cassandra Refcard. To read the entire Refcard, please download the PDF from the link above.
Below are supplementary resources and tools:
This is a preview of the Designing Microservices With Cassandra Refcard. To read the entire Refcard, please download the PDF from the link above.