Introduction
Big data world is messy! The choice of frameworks, platforms, and data sources is simply mind-boggling. Several teams at Walmart use a mix of various stacks and tools to make sense of the data. While having choices is great, it does become a bit overwhelming when someone wants to access data in a coherent and uniform fashion. Each system exposes a different set of APIs, a different language to write queries in, and potentially a different way of analyzing the data at large scale.
It became clear to us early on that we need to invest on a tech stack, which can provide access to TBs of structured and semi-structured data for quick analysis and still be manageable with minimal overhead. It was also desirable that the query language be as close to SQL as possible so that it could be used with relative ease.
Some of the systems we looked at were Apache Impala, Apache Spark, and Presto. Each of these systems are battle tested and support a large number of production systems today. We started gravitating towards Presto for the following reasons:
- Support for a large number of data sources (Hive, Cassandra, Kafka, Elastic Search)
- Extremely rich SQL dialect
- Ability to cross join data from multiple disparate sources
- No external dependency on systems like ZooKeeper, etc
- Great performance
In this article, we will explore our Presto set up and examine its performance for some common use cases. We will also focus on Apache Zeppelin, which is an excellent open source data visualization tool for interactive queries and helps team collaborate in real time.
Presto: A distributed SQL engine
Presto is an excellent distributed SQL engine that is optimized for running queries over huge datasets across multiple data sources. It supports distributed joins across multiple data sources like Hive, Kafka, Elastic Search, Cassandra, etc, thereby allowing a uniform access model for analytics.
Setting up the Presto cluster is easy. We set up a 8 node (each having 8 cores and 16G RAM) presto cluster in literally under 20 mins. Presto provides live query plans, which is a big plus. It helps us understand how to tune the queries for more performance. Presto also provides a JDBC driver, so accessing it from Java applications is very convenient as well.
Configuring Presto
Presto requires minimal configuration. We need to provide node.properties file under etc/, which requires bare minimum properties, e.g.
node.environment=prod
node.id=node1
node.data-dir=/var/presto/data
Each node also requires a config.properties.
coordinator=false
http-server.http.port=8080
query.max-memory=50GB
query.max-memory-per-node=8GB
discovery-server.enabled=true
discovery.uri=http://${coordinator_ip}:8080
One of the nodes has to be made coordinator and needs some more properties
coordinator=true
node-scheduler.include-coordinator=false
http-server.http.port=8080
discovery-server.enabled=true
discovery.uri=http://localhost:8080
One issue we ran into while configuring Presto was regarding the discovery.url. Presto uses its own discovery mechanism to identify the cluster workers. We observed that in the coordinator’s config.properties the discovery.url should be pointing to localhost while in all other nodes it should be point to coordinator’s IP
Finally, we need to add catalogs (connectors for different data sources) under etc/catalog directory. Example below shows how to add a Cassandra connector with minimal configuration
connector.name=cassandra
cassandra.contact-points=<comma separated IPs>
cassandra.consistency-level=LOCAL_ONE
cassandra.username=readonly_u
cassandra.password=readonly_p
cassandra.consistency-level=LOCAL_ONE
cassandra.load-policy.use-dc-aware=true
cassandra.load-policy.dc-aware.local-dc=DC1
cassandra.load-policy.use-token-aware=true
As mentioned before, Presto can connect to a lot of data sources including Cassandra, Hive, and Kafka among many others. A full list of connectors can be found here
Once the cluster is set up, the console can be accessed at the discovery.url
Measuring Presto Performance
The first task that we set out to do was to measure query performance. We had a table handy with close to 260M rows. Each row had roughly 1 KB data. The schema of the table is as follows:
CREATE TABLE event_lookup (
id text,
bucket_id timestamp,
payload text,
PRIMARY KEY (( id ))
)
Use case 1: count(*)
A simple query was fired on Cassandra which returned the count of total partitions in Cassandra.
SELECT COUNT(*) FROM event_lookup;
This resulted in a full table scan, by Presto with an impressive rate of ~ 418K rows / second! The inflow rate was ~ 400KB/sec. The screen shot below shows the rates along with other metrics.
During the query execution, there were occasional blips where read rate reached almost 1 million rows / second
Worker nodes also had almost equal distribution of load. From the screen shot below, each worker was processing on an average 51K rows / second.
Use case 2: group by
We wanted to execute some thing more complicated than a count(*) query to examine performance better. We used a group by query as follows:
SELECT bucket_id, count(*) FROM event_lookup GROUP BY bucket_id ORDER BY count(*) LIMIT 10;
This time around, the results were even more impressive. The average query rate reached an impressive of 560K rows / sec!
The worker node distribution was a little skewed, possibly because of the way “bucket_id” field was partitioned among the Cassandra token ranges. What was stunning was that one of worker nodes reached a maximum of ~ 100K rows/sec TPS.
Having obtained satisfactory results, we moved on the other end of spectrum, the visualization!
The other end of the spectrum: Apache Zeppelin
Data analytics is not appealing if not complemented by a strong visualization. Visualization goes a long way in quickly deriving data patterns and correlations. While there are tools and libraries that provide excellent visualization support, they require a fairly good understanding of JavaScript and CSS, which is not something that data analysts are expected to know. Apache Zeppelin aims to fill that gap precisely. It provides analysts an extremely convenient way to create interactive web notebooks to write and execute the queries and visualize the results immediately. The web notebooks can be shared and collaborated in real time for valuable feedback. The queries can be scheduled so that they can be executed periodically. Like Presto, Zeppelin can connect to many data sources as well. In this article we will focus on JDBC connector for accessing Presto.
Configuring JDBC connector for Presto
Adding a JDBC connector in Zeppelin is very easy. We just need to provide url, user, password, and driver properties. Below screen shot shows how to configure a Presto connection
Once the connector is added, we can create a notebook and add a new note. Inside the new note, the query can be executed as follows and the results can be visualized immediately in a variety of charts.
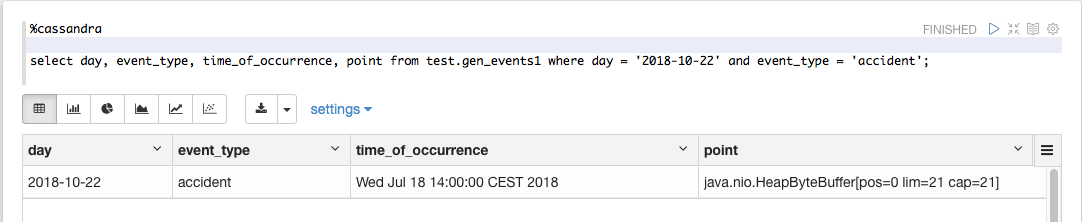
%jdbc SELECT bucket_id, COUNT(*) FROM event_buckets GROUP BY bucket_id
Note: if Presto is not configured as default interpreter, then you need to provide the name of the interpreter in the query
%jdbc(presto) SELECT bucket_id, COUNT(*) FROM event_buckets GROUP BY bucket_id
Building an interactive SQL executor
Zeppelin makes it very easy to build interactive form based UIs. Let’s try that by building a SQL input form. A general purpose SQL query executor requires following inputs:
- Name of the fields/columns to be retrieved
- Table name (FROM clause)
- Filter expression or aggregate expression (WHERE or GROUP BY clause)
- Sort field (ORDER BY clause)
- pagination (LIMIT and OFFSET)
We wrote a simple template zeppelin query
%jdbc
SELECT ${checkbox:Select Fields=Field1, Field1 | Field2 | Field3 | Field4} ${Free Form Fields = }
FROM
${Select Table=keyspace1.table1, keyspace1.table1 | keyspace2.table2 | keyspace3.table3}
${PREDICATE CLAUSE e.g. WHERE, GROUP BY = }
${ORDER BY CLAUSE = }
LIMIT ${limit = 10}
which resulted in the following UI
If we hide the query part, the UI becomes extremely simple
Now that’s the power of Zeppelin! In literally under 10 minutes, we are able to create a UI, where a user can
- Select fields (by selecting checkboxes, or entering in the ‘Free Form Fields’ like Count(*)
- Provide any ORDER BY clause
- Provide any WHERE or GROUP BY clause
- Choose any table to connect to
Using Zeppelin’s powerful display system (AngularJS) and variable binding mechanism, it’s very easy to create a chain of paragraphs which can execute in succession or in any arbitrary custom defined manner.
Summary
In this blog we explored how we can leverage Presto to run SQL queries over data sources. We also explored how we can wire Presto with Zeppelin to create compelling visualizations and analyze patterns quickly. This has resulted in quick analysis and collaboration between different teams. In the next article, we will be exploring how the Presto cluster is allowing us to join data across Cassandra, Kafka, Hive, etc for instant analysis on fast moving data. Stay tuned for more updates.