
The upcoming Zeppelin 0.9 is a very big release for Apache Zeppelin (the 0.9.0-preview2 was just released). A lot has happened since release of the 0.8.x series - better support for Spark & Flink, new interpreters (Influxdb, KSQL, MongoDB, SPARQL, …), a lot of bug fixes and improvements in the existing interpreters. In this blog post I want to specifically discuss improvements in the Cassandra interpreter that exists since Zeppelin 0.5.5, released almost 5 years ago.
The two most notable changes in the new release (already available in the 0.9.0-preview2) are:
- Upgrade of the driver to DataStax Java driver 4.x (ZEPPELIN-4378)
- Control of formatting for results of SELECT queries (ZEPPELIN-4796)
Upgrade to the DataStax Java driver 4.x
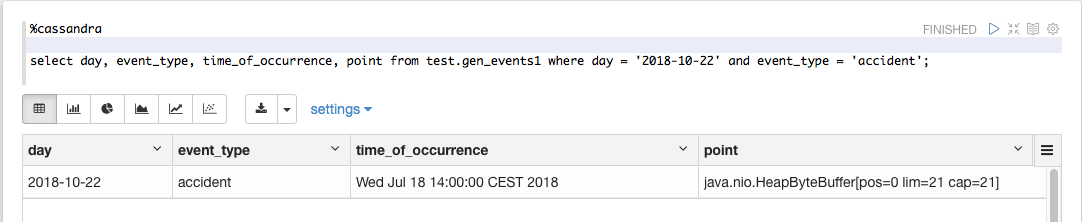
Prior releases of the Cassandra interpreter were based on the open source DataStax Java Driver for Apache Cassandra 3.x. It worked fine with Apache Cassandra, but not always was usable with DataStax Enterprise (DSE), for example, you couldn't use it with DSE-specific data types, like, Point, when you get data back as ByteBuffer instead of Point:

DataStax Java driver 4.0, released in March 2019th, was a complete rewrite of the Cassandra driver to make it more scalable and fault-tolerant. To achieve these goals, the architecture of the driver has changed significantly, making it binary incompatible with previous versions. Also since Java driver 4.4.0, released in January 2020th, all DSE-specific functionality is available in the single (unified) driver, instead of traditional separation on OSS & DSE drivers. With release of the unified driver 4, the 3.x series of the driver was put into the maintenance mode, receiving only critical bug-fixes, but no new features.
To get access to the new features of the driver, internals of Cassandra interpreter were rewritten. Because of the architectural changes of the new driver, the changes in the interpreter were quite significant. But in result we're getting more functionality:
- Access to all improvements and new functions provided by the driver itself - better load balancing policy, fault tolerance, performance, etc.
- Allow to configure all parameters of the Java driver. In previous versions of interpreter, every configuration option of the driver should be explicitly exposed in the interpreter's configuration, and addition of the new option required change in the interpreter's code, and release of the new version together with Zeppelin release. In the new version of interpreter, we can set any driver configuration option, even if it's not explicitly exposed by interpreter. This is possible because of the way the new Java driver is configured - configuration could be specified in the config file, set programmatically, or even via Java system properties. This flexibility was already demonstrated in the blog post on connecting Zeppelin to the DataStax's Astra (Cassandra as a Service)
- Support for DSE-specific features, for example, now it's possible to execute commands of DSE Search, or work with geospatial data types:

Because of the changes in driver itself, there are some breaking changes in interpreter:
- the new driver supports only Cassandra versions that implement native protocol V3 and higher (Cassandra 2.1+, and DSE 4.7+). As result, support for Cassandra 1.2 and 2.0 is dropped (but you shouldn't use them in 2020th anyway)
- there is only one retry policy provided by the new driver, and support for other retry policies (
LoggingRetryPolicy,FallthroughRetryPolicy, etc.) are removed. As result of this, support for query parameter@retryPolicywas dropped, so existing notebooks that are using this parameter need to be modified
Control of the results' formatting
The previous version of the interpreter always used the predefined formatting for numbers, and date/time related data types. Also, the content of the collections (maps, sets & lists), tuples, and user-defined types was always formatted using the CQL syntax, with This wasn't always flexible, especially for building graphs, or exporting data into a file for importing into external system that may expect data in some specific format.

In a new interpreter users can control formatting of results - you can configure this on interpreter and even on the cell level. This includes:
- selection between output in the human-readable or strict CQL format. In the human-readable format, users can have more control on the formatting, like, specification of precision, formatting of date/time results, etc.
- control of precision for
float,double, anddecimaltypes - specification of locale that will be used for formatting - this affects date/time & numeric types
- specification of format for date/time types for each of
date,time, andtimestamptypes. You can use any option of DateTimeFormatter class - specification of timezone for
timestamptype
All of this is applied to all data, including the content of collections, tuples, and user-defined types.
Formatting options could be set on the interpreter level by changing new configuration options (see documentation for details) - if you change them, this will affect all notebooks:

With default options, user will get data in human-readable format, like this:

But sometimes it's useful to change formatting only in specific cells. This is now possible by specifying options in the list after the interpreter name, like %cassandra(option=value, ...) (please note, that if option includes = or , characters, it should be put into double quotes, or escaped with \). There are multiple options available, that are described in the documentation(TODO: link) and built-in help. For example, we can change formatting to CQL:

Or we can multiple options at the same time - locale (see that it affects formatting of numbers and date/time), timezone, format of timestamp, date, etc.:

Other changes
There are also smaller changes available in the new release - they are making the interpreter more stable, or add a new functionality. This includes:
- (ZEPPELIN-4444) explicitly check for schema disagreement when executing the DDL statements (
CREATE/ALTER/DROP). This is very important for stability of the Cassandra cluster, especially when executing many of them from the same cell. Because Cassandra is a distributed system, they could be executed on the different nodes in almost the same time, and such uncoordinated execution may lead to a state of the cluster called "schema disagreement" when different nodes have different versions of the database schema. Fixing this state usually requires manual intervention of database administrators, and restarting of the affected nodes - (ZEPPELIN-4393) added support for
--comment style, in addition to already supported//and/* .. */styles - (ZEPPELIN-4756) make "No results" messages foldable & folded by default. In previous versions, when we didn't get any results from Cassandra, for example, by executing
INSERT/DELETE/UPDATE, or DDL queries, interpreter output a table with statement itself, and information about execution (what hosts were used for execution, etc.). This table occupied quite significant space on the screen, but usually didn't bring much useful information for a user. In the new version, this information is still produced, but it's folded, so it doesn't occupy screen space, and still available if necessary.
Conclusion
I hope that all described changes will make use of the Cassandra from Zeppelin easier. If you have ideas for a new functionality in Cassandra interpreter, or found a bug, feel free to create an issue at Apache Zeppelin's Jira, or drop an email to Zeppelin user mailing list.








