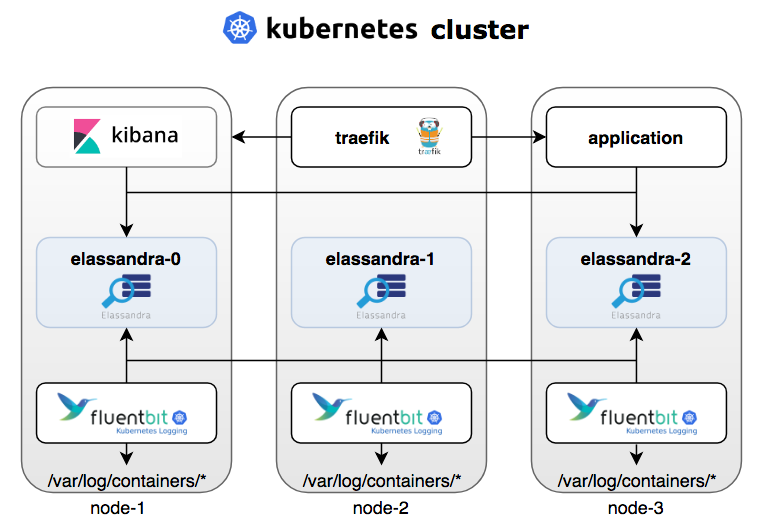
Elassandra is a modified distribution of Apache Cassandra with an embedded Elasticsearch search engine. Like MySQL, Postgres, MongoDB or CouchBase, Elasticsearch is a master-slave system with a Single Point of Write when a primary shard is down. Based on Cassandra, Elassandra provides Elasticsearch features with no Single Point of Write, allowing to build modern applications running active/active on two datacenters or more. We’re going to see how Elassandra process Elasticsearch search queries across Cassandra nodes.
On write path, Elassandra adds an internal _token field computed from the Cassandra partition key to each index Elasticsearch document. It’s a long number indexed by Lucene.
On the search path, Elassandra split a full-search query to a sub-queries for a set of nodes in the Cassandra datacenter. When the Cassandra replication factor is greater than one, Elassandra automatically adds a token_range filter to your Elasticsearch query to avoid duplicate results.
This token range filter cover 100% of the Cassandra ring, and each token range is served by exactly one node in the datacenter. If a node becomes unavailable, Elassandra automatically compute another set of Cassandra token ranges and distribute sub-queries to available nodes.
The Elassandra Search Strategy controls the subset of nodes involved to process a full-search query. The default Elassandra search strategy is the PrimaryFirstSearchStrategy, it broadcasts a sub-query to all nodes in the datacenter, with a token_range filter matching the node’s primary token ranges. For example, for node 1 having the primary token range 0–99, Elassandra adds the Lucene token_range filter [0:99[ to sub-query node 1.
Be careful, with the default Cassandra configuration with 256 vnodes, the token_range filter contains 256 token ranges. In order to reduce the complexity of this filter, it is recommended to use 8 or 16 vnodes per nodes.
When the Cassandra replication factor is greater than one, Elassandra can logically reduce the number of nodes involved in a full-search request. For exemple, in a 6 nodes datacenter with RF=3, Elassandra could sub-query only 2 nodes.
The RandomSearchStreategy randomly choose nodes until all token ranges of the datacenter are scanned, starting with the coordinator node if the Elasticsearch index shard is available.
Since version 6.2.3.27 and 6.8.4.4, the RackAwareSearchStrategy works as the RandomSearchStrategy but try first to use nodes in the same Cassandra rack. As the Cassandra NetworkTopologyStrategy is rack-aware, it tries to avoid two replicas to be placed on the same rack, and the RackAwareSearchStrategy use this property to get the lowest possible number of nodes to distribute a full-search request.
For example, in a 6 nodes datacenter, 3 racks and RF=3, a full-search query can be achieved on 2 node in a rack. If a node or shard is unavailable for some reasons, the search strategy use nodes from other nodes, but due to token range distribution, 3 nodes or more will be involved.
You can set or update the search strategy as an Elasticsearch dynamic setting:
You can also setup an Elasticsearch template to automatically set the Elassandra search strategy and Cassandra replication.
You can check computed token ranges used for each sub-query by setting the log level to TRACE for class org.elassandra.cluster.routing in your conf/logback.xml, or dynamically:
nodetool setlogginglevel org.elassandra.cluster.routing TRACE