
DSE Search (Apache Cassandra + Solr) Deployment Guide
Let me guess, you deployed DSE with just Cassandra enabled, realized you needed additional search capabilities, and restarted your nodes as DSE Search nodes with Apache Solr enabled. Should work fine, right?
Enabling Solr does offer a whole new set of features, including partial text search, facet queries, geospatial, etc, but DSE Search also means different hardware requirement, specific tuning, and TLC, also known as repairs.
Follow these 6 steps and save yourself some pain (based on DSE 4.8: Apache Cassandra 2.1 / Apache Solr 4.10).
Remember, all nodes need to have Solr-enabled within the DC. Also, make sure your connection object in your application is set to “DCAwareRoundRobinPolicy” to the DSE Search DC. You can only run solr_query on a Solr-enabled DC.
Environment
1. Hardware: more memory, more cores
If you are running DSE with only Cassandra enabled, 16-core CPU, 32GB RAM and SSDs is enough to get started.
If you plan to use DSE Search, 16-core CPU is the bare minimum. 24-core+ is ideal. Indexing is CPU intensive!
Memory is also key since you want your search index to fit in memory if you want to meet your SLAs (think performance). 128GB+ if you can. How can you know your index size?
Plan to leverage appropriately sized hardware, especially with memory, if you want to be successful with DSE Search.
2. DSE Search Configuration
2.1 vnodes
IMPORTANT: If you have vnodes enabled, make sure you set “num_tokens” to “32” (cassandra.yaml) before starting DSE; otherwise, you could pay a performance hit of up to 30%. You cannot change this easily after starting DSE so hopefully you read this before deploying your nodes.
2.2 dse.yaml
1. Increase concurrency, ie how many physical cores are allocated for indexing, by setting max_solr_concurrency_per_core to the number of available CPU cores divided by the number of Solr cores. By increasing indexing throughput, you increase the number of indexing cores per Solr core
max_solr_concurrency_per_core = CPU core / # Solr core
2. Adjust back-pressure: this keeps nodes responsive without falling over. Increase back_pressure_threshold_per_core to 1,000 x number of Solr cores. This represents the number of indexing requests in queue per Solr core.
back_pressure_threshold_per_core = 2000–10000
General guide, if your index queue backs up:
1. increase AutoSoftCommit > 10 minutes
2. increase backpressure
2.3 HEAP
Increase your HEAP to at least 20GB (especially if you have lots of RAM) in cassandra-env.sh if you are using G1GC:
MAX_HEAP_SIZE=”20G”
If you are using CMS, set MAX_HEAP=14G
3. Repairs
RUN REPAIRS! Solr queries have Consistency Level (CL) = Local_One + kick off read repair when run from CQL. If run from Solr HTTP API, CL=ONE + no read repair. You want the same result regardless on which node you run your query, don’t you? Simplest way to do this: OpsCenter.

Data Model
4. Partition Key
Who cares about your partition key, you now have the freedom of running any queries you ever wanted now that you have DSE Search. Well, ok but don’t throw away good data partitioning just because you might not have to think about denormalizing, duplication, and access pattern data modeling.
Remember: keep it below 100MB partition size and 100,000 items.
How can you tell you’re in the clear:
1. Opscenter Best Practice Services has a “wide partition” validation
3. system.log — they come up as “WARN .. Compacting large partition…” so look for them
4.1 Collections: Map
All those “map” collection columns in your table will now be converted to dynamic fields in Solr. Why does it matter? Well: “Lucene allocates memory for each unique field (column) name, so if you have a row with columns A, B, C, and another row with B, D, E, Lucene allocates 5 chunks of memory. For millions of rows, the heap is unwieldy. Instead of using dynamic fields, use Copy fields instead and then perform queries against the combined field.” (DataStax docs)
4.2 Decimals
CQL decimal type will be automatically mapped to Solr DecimalStrField, which is not very helpful since it will do a string comparison rather than numeric. Instead, store the field in CQL as decimal (as you did) and use Solr Copy field to map it to a TrieDouble. I know double != decimal but it’s the best work-around I’ve seen.
Solr Tuning
This was already well covered in this post but high level:
5.1 Schema.xml
Save space, keep your Solr index smaller by using StrField (vs TextField) for fields you will not do partial text searches on. Also, you don’t HAVE to index all your columns (really). Set indexed=false in your schema.xml

5.2 docValue
If you are executing facet queries, ie you want to “group by” a column such as event by status, or sorting, set docValues=true
There are other parameters you can tune such as query warming, but these 2 are simple, common and apply to most DSE Search projects.
Monitoring
6.1 Opscenter
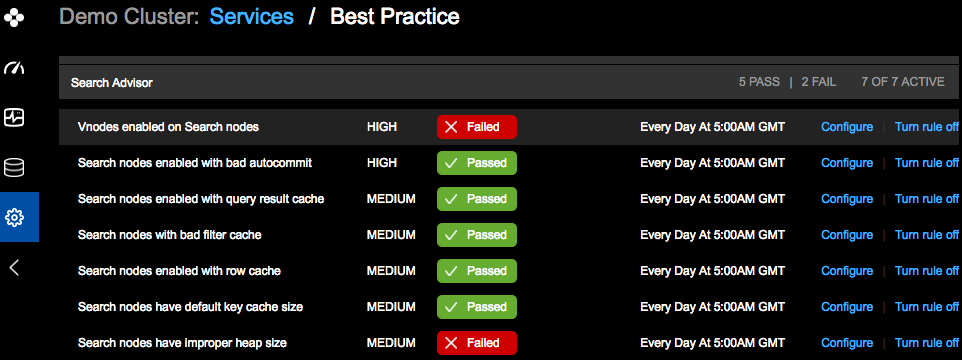
You can monitor DSE Search Request, Latency, Timeouts, Errors, Core Size from your Opscenter dashboard. You can also enable Best Practice Services for DSE Search.
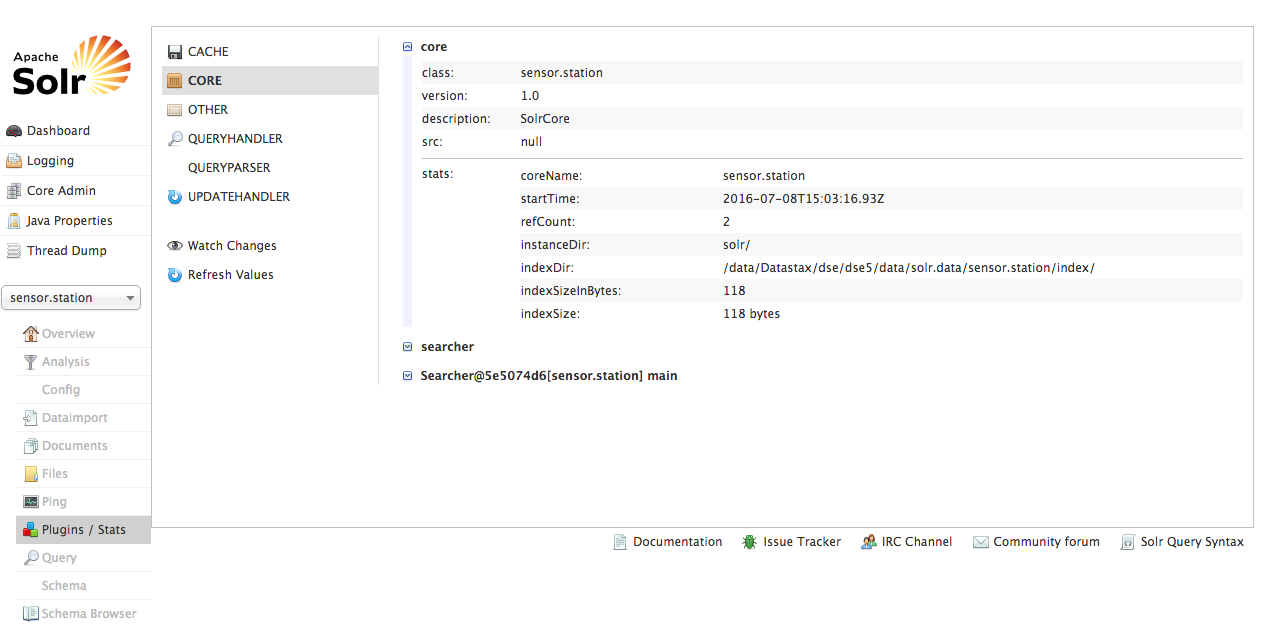
6.2 SolrAdmin UI
You want your index to fit in memory so how can you easily find out its size? Select your core from SolrAdmin UI:
> plugins/stats -> CORE -> index size (or via Opscenter)
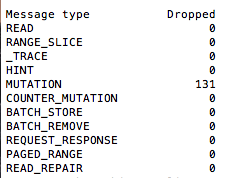
6.3 Dropped Mutations
Last recommendation: check dropped mutations, ie via Opscenter by adding the graph to the dashboard or by selecting a node so node details come up -> scroll down to bottom.
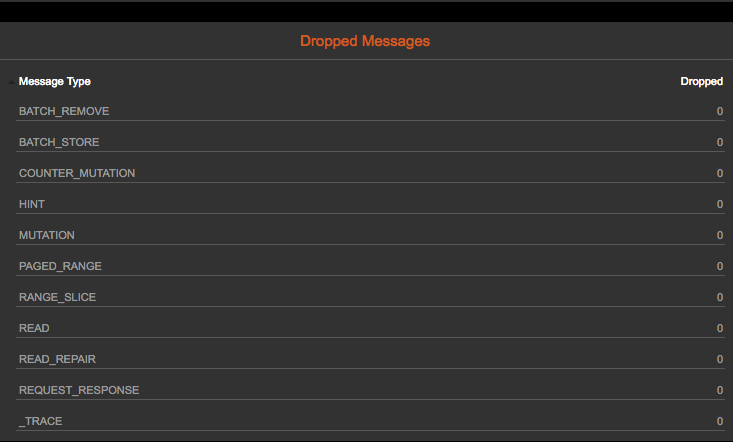
This is also available via nodetool tpstats. This indicates that you are overloading your cluster and the nodes cannot write fast enough. Not a good thing if you want consistent Solr results.
Conclusion
This is not meant to be a comprehensive guide to everything you should configure/monitor with DSE Search. This is just to get you started. There are other configuration and tuning you can do but these are the most common I have come across that will get you the most impact for simple changes.







