This is the second of a series of articles explain the operations of cassandra-stress. See here for Part 1.
This series of blogs has been created as part of my prep for my Cassandra summit talk ‘Load Testing Cassandra Applications’.
In this post we’ll examine the operation of the mixed command in Cassandra stress and along with that some option for changing the schema used by stress (without using the yaml configuration for a complete custom run).
Firstly, let’s look at the most simple invocation of the mixed command:
cassandra-stress mixed n=100 -node x.x.x.x
First thing to note about this command is that for it to work you need to have run a write command to create the schema and populate data before the run. The write command should be run with at least the same number of operations as the mixed command to ensure that read commands will all retrieve data. For example, to prepare for the above command you should run:
cassandra-stress write n=100 -node x.x.x.x
If you haven’t written the right data before you run the mixed test then you will receive errors like the following:
java.io.IOException: Operation x0 on key(s) [38374d394b504d353430]: Data returned was not validated
This is because cassandra-stress validates the data returned from the select operations against the generated data set expected for the row (and in this case no data was returned).
So, once you’re set up correctly, what will the command actually do? The key default settings that come into play are:
- Consistency level: LOCAL_ONE – particularly significant for reads as it means only a single node will need to perform each read (vs multiple nodes for the more common QUORUM consistency levels)
- Command Ratios: {READ=1.0, WRITE=1.0} – the operations will be split evenly between reads and writes
- Command Clustering Distribution: clustering=GAUSSIAN(1..10) – determines the number of consecutive read or write operations to conduct consecutively. So, in this case will perform between 1 to 10 reads before performing between 1 to 10 writes and then switching back to reads. Due to this clustering, the actual ratio of reads to writes may differ from the target specified in command ratios for small runs such as this. However, it should even out over the course of a longer run.
- Population Distribution: Gaussian: min=1,max=100,mean=50.500000,stdev=16.500000 – unlike the write command, which uses a sequence from 1 to number of ops, mixed uses randomly generated numbers from 1 to the number of ops as part of the seed for the actual values. As the range is the same as write operations, the values are guaranteed to overlap between write and mixed but the the mixed run will potentially not visit all possible values and will visit them in a random order (of seed values).
- Rate: Auto, min threads = 4, max threads = 1000 – cassandra-stress will perform multiple runs, start at 4 threads and increasing threads with each run until the total operation rate fails to increase for three consecutive runs. The number of threads used will double with each run up to 16 threads and then increase by 1.5 times with each run after that.
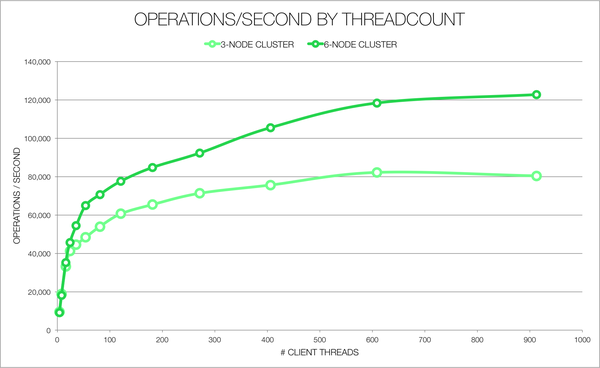
The rate setting illustrates an interesting point in using cassandra-stress: generally, increasing the number of client threads will increase the load (throughput) you are placing on the cluster. This is because all operations are executed synchronously (in order to time them) and so more threads allow more operations to be simultaneously thrown at the cluster. Of course, like any multi-threaded system, there is an overhead incurred managing threads on the stress client and a limit to how much work the client can do before it becomes a bottleneck to the test. So, increase threads to increase the load on your cluster but check when you hit the limit that it’s actually your cluster reaching its limit not your stress client.
That’s it for the mixed command and associated info. Future installments will look at some of the other key options and the yaml configuration file.
Click here for Part One: Deep Diving into Cassandra Stress
Click here for Part Three: Using YAML Profiles