Modeling principles
- Know your data
- Know your query
- Nest Data
- Duplicate data
Modeling Good to know
- Query-driven data modeling. Application queries should be build before creating a data model.
- Every query should have its own table.
- Name tables after queries ex (videos_by_tag_added_year).
- It’s okay to have duplicated data across multiple tables. We don’t care about space, we care about speed.
- Cassandra will do an upsert if the primary key and clustering key in a cell are not unique.
- Primary keys, clustering keys and clustering order can’t be change after a table is create. You will need need to create a new table and move old data to new table.
- You can only do range queries on clustering keys.
- Make sure data is duplicate at a constant duplication. If data is duplicated 25 x N, limit N to make the duplication factor constant.
- A partition can only have 2 billion cells. You are likely to hit performance issues before hitting this limit.
- A partition should only be hundreds of megabytes on disk
- A cell or column is a key-value pair.
- Trade-off between efficiency and space. Use client side joins and don’t duplicate data.
- There are no JOINs in cassandra.
- Use BATCH statement to update or insert all duplicated data.
- Cassandra has SQL like sytanx call CQL for creating and manipulating.
Calculate partition size
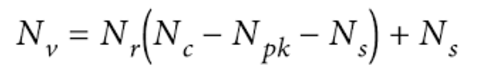
The formula below can be use to calculate how big a partition will get to overtime. If a partition gets bigger than 2 billion cells, performance will be affected.
- Nr -> Number of rows
- Nc -> Number of regular colums
- Npk -> Number of primary keys
- Ns -> Number of static columns
- Nv -> Number of values

- Nv = 40000 x (7 - 3 - 0) + 0
- Nv = 40000 x 4 + 0
- Nv = 160,000
Estimate table disk space
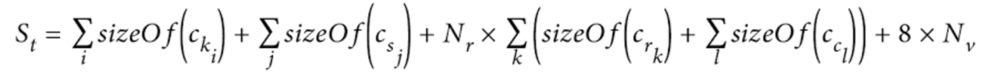
- Ck -> Partition key
- Cs -> Static columns
- Cr -> Regular column
- Cc -> Clustering column
- Nr -> Number of rows
- Nv -> See formula above
- St -> Size of a table
- sizeOf -> Estimate size of column
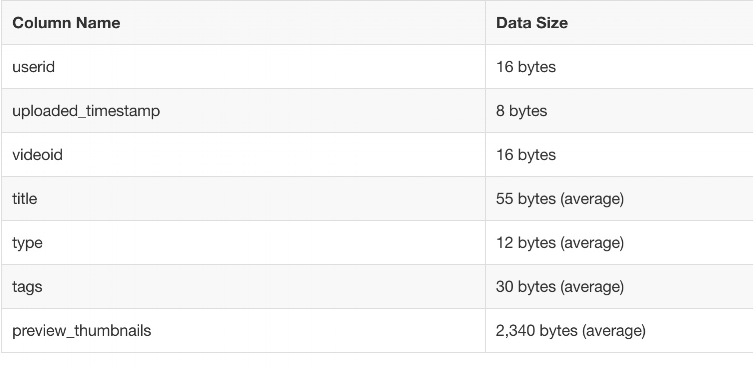
- St = 16 + 0 + 40000 x ((55 + (8 + 16)) + (12 + (8 + 16)) + (30 + (8 + 16)) + (2340 + (8 + 16))) + 8 x 160000
- St = 16 + 0 + 40000 x 2533 + 8 x 160000
- St = 16 + 0 + 101320000 + 1280000
- St = 102,600,016 bytes