Sep 5, 2019 · 8 min read
Apache Cassandra is one of the most popular NoSQL databases. It offers great performance and scalability without sacrificing availability. It has no Single Point of Failure (SPOF). The biggest, publicly announced cluster contains over 115k nodes and over 10PB of data. However, Cassandra data format differs from what you got used to in the SQL world. There are tables with special keys but without relations. What is the most important, it is not possible to query data using any arbitrary column. Cassandra is not perfect for every project, there are many mistakes which can be made when working with it. Let’s analyze a few of them.
Note: This blogpost is based on my presentation: Cassandra — How to fail?
I have written recently a similar blog post about 7 mistakes when using Apache Kafka. Take a look and learn about best practices!
We’ve already heard people saying “we will have a lot of data”, “it worked for Apple” or “it worked for Walmart”. However, in practice, it means nothing. Cassandra is not a typical database which fits in every Big Data use case. ThoughtWorks warns in their Technology Radar:
It’s a great tool and we like it, but too often we see teams run into trouble using it. We recommend using Cassandra carefully. Teams often misunderstand the use case for Cassandra, attempting to use it as a general-purpose data store when in fact it is optimized for fast reads on large data sets based on predefined keys or indexes. (…)
So, be careful. Why? Let’s take a look at the next mistake.
It’s a pretty common approach, to start from implementing the domain model in the database, right? In Cassandra’s case, it’s not that simple. You need to start with queries. Yes, you should know all important access patterns to data beforehand. You don’t? Maybe then, Cassandra is not (yet) for you. In many situations, projects may be startups, without fully known requirements. Cassandra usage in such situation is just risky, because later it may appear that it hasn’t really been a fit.
The recommended modeling methodology includes a few steps:
You need to start with two diagrams:
- Conceptual Data Model — in the form of a standard entity-relationship diagram
- Application Workflow — graph of all transitions in the application
Then by applying specific mapping rules combine those graphs into a Logical Data Model represented by the Chebotko Diagram. It includes all views in the application together with data being presented on them and queries made to retrieve them.
After optimizations, the Chebotko Diagram can be transformed into the Physical Data Model in CQL (Cassandra Query Language).
No, unfortunately not. Let’s say that Potato table on the previous screen would contain a few dimension related columns and customer would like to add a filtering feature using those columns. In SQL that would be pretty simple, so why is that difficult here?
- Every row in Cassandra is identified by a primary key consisting of two parts:
- partition key — defining location in the cluster. Partition key hash indicates on which node on the Cassandra cluster the partition is located
- clustering key — defining row location inside of the partition
Queries by partition key or by partition key and clustering key are fast & efficient. However those are usually equality comparisons (non-equality comparison can be performed only on the last part of clustering key), and the dimensions columns do not really fit the key.
2. Secondary indexes offer equality comparisons as well, but they are not recommended due to poor performance. They are kept on each Cassandra node and to use them Cassandra needs to send the query to all nodes in the cluster.
3. Newer Cassandra versions allow usage of special keywords allow filtering. They indicate that you agree that the query may perform in-memory filtering, which is not efficient. It is highly not recommended to use those keywords in production.
4. Materialized views are not suitable for production
5. SSTable Attached Secondary Indexes (SASI) — improved secondary indexes. They could really work for dimensions filtering. However, e.g. DataStax, the company supporting Cassandra, still marks them as experimental and does not recommend for production usage.
As you can see simple filtering by a few numbers, which initially looks simple is not that simple in the Cassandra world!
In SQL you can always add a new column, and then execute a query similar to the following one:
UPDATE table1
SET new_column = column1 + column2
Simple sum of two other column values. Can we do this in Cassandra? Not really. CQL does not allow such operations. Generally, Cassandra does not allow any inefficient operation. Setting values for all rows in the table can be quite heavy when you have terabytes of data.
So what can we do for schema changes and data migrations? Often you may need to write a separate data migrating application. Another choice is to use Apache Spark. It’s quite easy to define their input table, transformations, and schema of the new table which will be automatically created. Just remember that operating on TB of data may take a lot of time.
People tend to choose less but bigger machines. Huge slow disks make the Compaction process longer.
Compaction is about merging sstables, since partitions in sstables are sorted based on the hash of the partition key it is possible to efficiently merge separate sstables. Content of each partition is also sorted so each partition can be merged efficiently.
http://cassandra.apache.org/doc/latest/operating/compaction.html
Assigning tons of RAM & huge heap spaces also may increase Garbage Collection times. Remember that it may be better for you to have more smaller nodes, than few large ones. Take a look also at Apache and DataStax hardware recommendations.
It is not enough, just to run the database and forget about it. You have to monitor cluster state, how replication works and others. However, the most important is to… run the repair process. In current versions, it is not run automatically, but it is greatly recommended, why? To avoid… rise of the zombies!
Let’s say that you have a cluster with replication factor 3 and consistency level quorum. Your row is stored on 3 nodes.
And now you want to delete it. But wait, something went wrong, one of the nodes is not responding!
Let’s say that V2 means deleted row (with a tombstone). Application still has a correct view on the data, because the coordinator can return data from other copies, but what Cassandra can do now to achieve consistency?
- Hinted handoff-when node is off by up to
max_hint_window_in_msthe query coordinator will store operations for it. They would be reapplied after node is up. But let’s say our outage lasts longer. - Read repair-when data is read, with
read_repair_chanceprobability, the coordinator will query all of the replicas and compare fetched data. This way client will get V2. But let’s say our row wasn’t queried and this mechanism couldn’t be applied.
So what now? It gets worse! Tombstones are kept for gc_grace_seconds which is by default 10 days. What happens when after more than 10 days compaction will be run? Two old replicas will no longer have any idea that our row has ever existed.
And now let’s say someone runs repair. The repair process has noticed that one node contains row which should appear on other replicas, result?
Our deleted row exists on all replicas! How to avoid that? Quite simply, run repairs more often than gc_grace_seconds, e.g. every 7 days. To get more detailed info on this process, take a look at “About Deletes and Tombstones in Cassandra” blogpost from The Last Pickle.
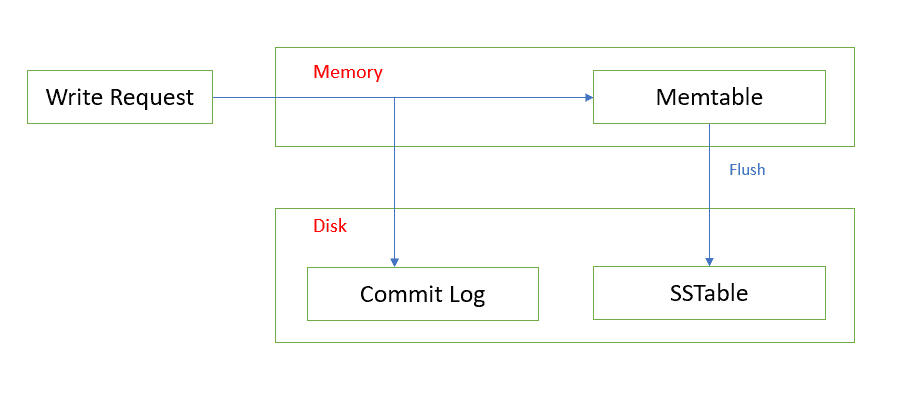
Let’s say you have a table with short-lived tasks to be performed. Rows are often added and often deleted. Looks simple. However, in practice, this is the worst thing which can happen to Cassandra. SSTables are immutable. Delete is actually a write of a tombstone. This means that although your tasks table may be empty, the disk may be actually full! The only way to free space is to perform compaction, which, as said before, is using CPU and disk throughput. Finishing compaction does not guarantee that all tombstones are deleted. Depending on the algorithm, e.g. only tables with similar size are compacted together. If row A information is located in a large old SSTable and a tombstone is in some small fresh SSTable, this means they won’t be compacted together, and they may occupy disk for days or weeks.
- Let’s use external Load Balancer — Cassandra driver applies a client-side load balancing. External Load Balancer may become a Single Point of Failure.
- Let’s use Cassandra as a search engine— having a lot of queries is very difficult to implement in Cassandra. A search engine would be just difficult and expensive to achieve.
- Let’s use Cassandra as a filestore — Cassandra does not like too big rows. If you want to store big files, then you need to split them into multiple parts. You may also just consider using some dedicated file storages, like e.g. Ceph.
Apache Cassandra is not the easiest database to learn on the market. You need to take a thoughtful decision about its usage in your project. Be careful-check if Cassandra is really a database for you. Start from analyzing your domain form the perspective of the queries. Remember that there are no full transactions here. If all of the tradeoffs are acceptable then choose the right environment for the deployment. Keep away from too large disks. Avoid deletes in your application (or if possible even updates). Also remember to monitor the cluster, keep it healthy and run the repairs.
When Cassandra works the best? In append-only scenarios, like time-series data or Event Sourcing architecture (e.g. based on Akka Persistence).
Be careful, it’s not a general-purpose database.