
If you like wrestling with dependencies and version incompatibility issues as much as I do, then this post is for you! This post arises out of a project requiring execution of Gremlin traversals using multiple query APIs, and from both a DSE Graph Analytics cluster and an external Spark cluster at the same time. What we found is that keeping all the different available DSE libraries straight wasn’t always easy. The goal of this blog post is to summarize what we learned from the project so that others can know which library to use and why, particularly when using Spark and Graph with Cassandra. We will look at seven libraries, including DSE Java Driver, OSS Unified Java Driver, dse-java-driver-graph, OSS Spark Cassandra Connector, DSE GraphFrames, BYOS, and dse-spark-dependencies.
If all you are trying to do is just write to Cassandra from your Java app, this blog post is not for you. Allow me to just refer you to the Datastax Java Driver for Apache Cassandra® and you can be on your way.
However, if you want to integrate other related tools, it starts to get a little more complicated. For example, if you are connecting to Cassandra from Spark, you might wonder when you should use the OSS Spark Cassandra Connector and when you should use the “BYOS” (Bring your own Spark) jar. Add Graph on top of Spark, and it gets even more complex: should you use the Java Driver’s graph functionality, DSE GraphFrames, the BYOS jar, or some combination?
Indeed, as will be described below, many of these libraries have overlapping functionality and even overlapping Java classes. There is good reason for this as well, but what it means is that if you get it wrong, you can introduce incompatibilities, for example by accidentally overriding the classes in one of your dependencies with the classes of another. Knowing the what each library is for will help you avoid this problem.
The goal of this post is to line up each of these libraries in a single place and show their specific purpose. It is outside of the scope of this post to give implementation instructions — how you add your libs, whether as some xml in your pom, a jar in your Databricks cluster’s libraries, an SBT dependency, or however you choose to do this, is documented elsewhere. But at the very least this will help you to know which dependency to add to your class path for your use case.
First we will start with the more fundamental and straightforward libraries, and then work our way up to the more complex. Accordingly, the Java Drivers are the place to start. Note that we are focusing specifically on Datastax libraries here, since the goal is to work upwards towards the other Datastax libraries that depend on the Java Drivers in different ways. For non-Datastax Drivers that work on the JVM, see the lists on the Apache Cassandra page for Java or Scala .
Previously, the DSE Java Driver was the Java driver to use with Datastax enterprise. However, as this Datastax blog post explains, this library was merged into the unified OSS Java driver (see below) as of 4.4.0.
One might (mistakenly) think that this means we can ignore the DSE Java Driver. As it turns out, the DSE Java Driver is used as a dependency within other Datastax dependencies. Accordingly, when you are up late at night trying to figure out why your external Spark cluster throws some missing dependency error when connecting to your Datastax C* cluster, these are the docs you will need to look into. Just make sure you look into the docs for the right version!
Note that by definition, the code for this library is not open source. Sometimes however you can get an idea for the code that is used under the hood by checking out the equivalent classes of the OSS Java driver.
However, this isn’t enterprise software for nothing — you’ll often just want to either ask Datastax Community or your friendly Datastax Support for help with this one.
For the most part, don’t!
Just use the OSS Java driver, or use the version that comes bundled in the BYOS jar if you’re using that (e.g., for DSE 6.7, it’s DSE Java Driver 1.7). However, sometimes edge cases come up where you have to use this anyways, especially if you’re working on a project that hasn’t migrated to the OSS Java driver yet.
To be honest here, I’m not sure when anyone should ever use DSE Java Driver 2.x at all (?). If you have any ideas, leave a comment!
- BYOS jar
- DSE Spark Dependencies
None.
However, note that technically the “DSE Java Driver” is not just one dependency, but several, including:
com.datastax.dse:dse-java-driver-corecom.datastax.dse:dse-java-driver-query-buildercom.datastax.dse:dse-java-driver-mapper-runtime
com.datastax.dse:dse-java-driver-graph is also mostly under the umbrella of DSE Java Driver, but I'm discussing it separately below as well. Note that since DSE Java Driver 2.x is based on the OSS Unified Java Driver, it does not have a separate dse-java-driver-graph dependency — all graph functionality is put together under dse-java-driver-core.
- DSE Java Driver documentation
- Explanation of how DSE Java Driver got unified with OSS Java Driver
- DSE Java Driver Java docs for v.2.3 (latest as of time of writing)
- Graph Docs for Java Driver v.2.3 (latest as of time of writing)
- Graph Docs for Java Driver v.1.7 (what is used for BYOS jar for DSE 6.7, at least for now)
As noted above, this is the library that overtook the DSE Java Driver. And that’s a good thing. However, it’s worth repeating that this is not the driver that gets included in even more recent updates to the BYOS jar, that domain still belongs to the DSE Java Driver.
Unless you are executing your jar from a Spark Cluster, this is the library to use. If you are executing from Spark however, then you will either be using the BYOS jar or OSS Spark Cassandra Connector, in which case either the DSE Java Driver or the OSS Driver will already be defined in that respective parent library, and so using the OSS Java Driver could create conflicts.
- OSS Spark Cassandra Connector (see below for separate section on this)
None. Though again, this OSS Java driver technically is an umbrella which includes:
com.datastax.oss:java-driver-corecom.datastax.oss:java-driver-query-buildercom.datastax.oss:java-driver-mapper-runtime
Graph functionality is included in com.datastax.oss:java-driver-core.
- OSS Driver Documentation
- Docs for OSS Driver Graph API (v. 4.13, the most recent version as of writing)
- OSS Driver Github
- OSS Driver Java Docs (v. 4.13)
DSE Java Driver Graph is not technically a separate driver from the DSE Java Driver, and is documented under the same set of developer documentation. Indeed, for OSS Driver 4.4.0+ or DSE Java Driver 2.x, dse-java-driver-graph is no more — everything is included in dse-java-driver-core.
However, for 1.x, it is a separate dependency that you might see in your project’s pom.xml file: com.datastax.dse:dse-java-driver-graph. You will need this on top of the DSE Java Driver Core when performing Graph queries using the Fluent API.
Use whenever you are using the fluent API for graph queries with DSE Java Driver 1.x or some other dependency that includes DSE Java Driver 1.x within it, such as BYOS (see notes under “BYOS” for more on this).
None.
Note that this is not included in the BYOS jar or dse-spark-dependencies.
I mention this just to say, beware: if you do use BYOS jar or dse-spark-dependencies, you will not want to include the DSE Java driver core for example (dse-java-driver-core), but you will want to include DSE Java Driver Graph in your pom (or whatever you're using to get dependencies on to your class path).
None.
Opening up the jar (found here) reveals that it includes the namespace com.datastax.dse.graph only:
These classes are not included in the DSE Java Driver API docs and I was unable to find API docs elsewhere for this either. However, this is where the dependency is mentioned in DSE Java Driver docs (v.1.8).
Having finished an overview of the Java drivers, we can now move on to libraries for integration with Spark. First, we have the OSS Spark Cassandra Connector (SCC).
Note that this is not for use with a DSE Analytics cluster, and believe it or not, also not really for using an external (i.e., non-DSE) Spark cluster with your DSE Cassandra cluster. Though there are some specific use cases where you might consider using SCC for connecting an external Spark cluster with your DSE Cassandra cluster, that domain is actually the specific use case for the BYOS jar (more on that later).
A comparison between SCC and BYOS is helpful here:
In summary, Spark Cassandra Connector is for connecting non-DSE Spark with non-DSE Cassandra. For example, if you’re using some implementation of OSS Cassandra (including Datastax Astra) with Databricks, SCC is for you.
If you’re using non-DSE Spark with DSE Cassandra however, you’ll probably benefit from the extra features that come along with the BYOS jar.
Databricks Spark has its own runtime and accordingly comes with certain dependencies and classes predefined. This is part of why people use Databricks in the first place, since it means you have less to set up yourself. On the other hand, this can lead to dependency conflicts. For example, Datastax Java Driver requires a Guava version of at least 16.0.1, whereas Databricks runtimes use Guava 15 (as of the latest version at time of writing, 9.1 LTS).
Such conflicts can cause exceptions with helpful error messages such as the following:
java.lang.NoSuchMethodError: com.datastax.driver.dse.DseSession.executeGraphAsync(Lcom/datastax/driver/dse/graph/GraphStatement;)Lrepackaged/com/google/common/google/common/util/concurrent/ListenableFuture
Accordingly, if using SCC with Databricks, you will want to use the spark-cassandra-connector-assembly artifact rather than spark-cassandra-connector. As noted in this Datastax community post, spark-cassandra-connector-assembly "is a fat jar with some of the dependencies shaded. It was created to avoid classpath conflicts when SCC is used in Databricks env.” Watch out, since there is not much in the way of documentation for spark-cassandra-connector-assembly, besides this brief comment in the docs and this blog post by one of the maintainers.
Further reading regarding SCC with Databricks:
- The only official comments I could find on
spark-cassandra-connector-assembly - Blog post by Alex Ott on using Astra with Databricks, demonstrating use of spark-cassandra-connector-assembly
- Anant webinar and corresponding blog post on Astra with Databricks
- Databricks Release Notes, with version compatibility matrix. For specific Java/Scala libraries and versions on the Databricks runtime classpath, see release notes for your specific Databricks runtime version (e.g., see here for Databricks runtime v. 9.1).
Some resources related to Guava issues with Datastax Libraries:
- https://docs.datastax.com/en/developer/java-driver-dse/1.8/faq/osgi/#how-to-override-guava-s-version
- https://groups.google.com/a/lists.datastax.com/g/spark-connector-user/c/uB_DN_CcK2k
- https://stackoverflow.com/questions/35618126/dse-cassandra-has-guava-16-0-1-jar-conflict-issue-with-cdh-spark
- https://stackoverflow.com/questions/36877897/detected-guava-issue-1635-which-indicates-that-a-version-of-guava-less-than-16
- BYOS
- dse-spark-dependencies
In other words, if you’re using BYOS or dse-spark-dependencies, don’t add SCC to your pom also.
- OSS Java Driver
According to this Datastax community post: “Similarly to BYOS, SCC comes with a version of the driver that should not be overridden in user apps.”
You can find the OSS Java driver version used by SCC in their repo under project/Versions.scala. E.g,. for SCC 2.5.1, it’s OSS Java driver 4.7.2.
Note also that SCC does not include DSE GraphFrames. Accordingly, you can perform graph traversals on your DSE Graph-enabled cluster using the Graph functionality built into the OSS Java driver if you want to, but to take advantage of the Spark-specific optimization provided by DSE GraphFrames, you will have to add that separately.
As an aside, a separate alternative altogether is to use DSE Graph OLAP queries, which also makes use of DSE Spark with Graph.
- https://github.com/datastax/spark-cassandra-connector
- SCC google group
- Overview of which dependencies to use for connecting to C* from Spark. It’s a little bit outdated though, from May 2017. Note also that it does not discuss when to use BYOS.
As described by the Datastax blog:
“The DseGraphFrame package provides the Spark base API for bulk operations and analytics on DSE Graph. It is inspired by Databricks’ GraphFrame library and supports a subset of Apache TinkerPop™ Gremlin graph traversal language. It supports reading of DSE Graph data into a GraphFrame and writing GraphFrames from any format supported by Spark into DSE Graph.
The package ties DSE Analytics and DSE Graph components together even stronger than it was before! Spark users will have direct access to the Graph and Graph users will be able to perform bulk deletes, updates and have an advanced API for faster scanning operations.”
According to Datastax documentation, when there are more complex queries involved, it is better to use DSE Graph OLAP instead of DSE GraphFrame lib, at least as of DSE 6.7. However, simpler Gremlin queries can benefit from performance optimizations provided by DSE GraphFrame. As stated in the DSE GraphFrames docs: “DSE Graph OLAP has broader support for Gremlin than the DseGraphFrame API. While Graph OLAP is the best choice for deep queries, simple filtering and counts are much faster using the DseGraphFrame API.”
Between DSE GraphFrame and the Graph API provided by the OSS or DSE Java Drivers, in general DSE GraphFrame is going to be a better pick. The main exception is if you have a very specific use case which does not allow use of DSE GraphFrames, for example, if your Gremlin queries are not supported by the more limited DSE GraphFrame API.
However, note that unless I’m mistaken, you should almost never need to define this in your app jar’s dependencies, since DSE GraphFrames is only for DSE graph-enabled Clusters, which means you’ll always either be using BYOS or dse-spark-dependencies, both of which include DSE GraphFrames. The only exception is if there’s some edge case where you have a DSE Graph Cluster, but need to use OSS SCC for whatever reason and still want to use DSE GraphFrame API.
None
- BYOS
- dse-spark-dependencies
- https://www.datastax.com/blog/introducing-dse-graph-frames
- https://www.datastax.com/blog/datastax-enterprise-graphframes-best-practices
- DSE Graph Frame docs (for DSE 6.7)
- When to use DSE Graph OLAP and when to use DSE GraphFrames
Finally, we have arrived at the BYOS library. If you have been able to follow up to this point, then hopefully this section won’t be too bad for you either. Be warned however, that it gets a little crazy in here.
The announcement post for BYOS says it well: “Bring Your Own Spark (BYOS) is a feature of DSE Analytics designed to connect from external Apache Spark™ systems to DataStax Enterprise with minimal configuration efforts.” Part of how it does this is by bundling together several other libraries into one, so you don’t have to include them in your pom yourself.
Use BYOS when connecting from external Spark to DSE C*.
One thing to watch out for: BYOS is only tested with the Spark version that is integrated in the corresponding DSE release, as well as a couple other Spark distributions (e.g., BYOS jar for DSE 6.8 is tested with Spark 2.4, Hortonworks Data Platform 2.5, and Cloudera CDH 5.10). Watch out for this if your external Spark cluster uses a different version (thanks to Adam Fortuno for pointing this out).
When to use instead of SCC:
When you have an external Spark cluster that is connecting to an DSE C* cluster, use BYOS. When connecting to OSS C*, use SCC.
For more on SCC, see separate section above.
When to use instead of DSE spark dependencies:
DSE spark dependencies is for when running on Spark from a DSE Analytics (i.e., Spark-enabled) cluster, BYOS is for when running on an external Spark cluster.
For more on DSE spark dependencies, see separate section below.
- DSE GraphFrames (source: Datastax Community post)
- Spark Cassandra connector (SCC)
BYOS is actually built on top of SCC, but just has some extra features built in and extra dependencies. In other words, DSE is to C* as BYOS is to SCC. I am not sure what version it uses however.
- DSE Java Driver
Note that according to this Datastax Community post, the version of DSE Java Driver included is “the same DSE Java driver (not OSS) that ships with the particular version of DSE. For example, DSE 6.7.7 includes DSE Java driver 1.7.1.” However, also note that according to a comment by a maintainer, as of December 2020, there is a “plan to upgrade to 1.8.3-dse (unreleased yet) in the near future”.
Implication: What this means is that if you are using the BYOS library to execute Gremlin traversals, make sure not to also include DSE GraphFrames or SCC or a separate Java Driver, or else you might run into conflicts. However, since BYOS is including DSE Java Driver 1.x, sometimes you will have to add dse-java-driver-graph also, for example, when using the fluent API.
One other takeaway from what’s not on this list: while BYOS includes DSE Java Driver (which has some Graph functionality baked in) and DSE GraphFrames, BYOS does not include DSE Java Driver graph (com.datastax.dse:dse-java-driver-graph).
General overviews:
- https://www.datastax.com/blog/bring-your-own-spark
- https://docs.datastax.com/en/dse/6.7/dse-dev/datastax_enterprise/spark/byosOverview.html
More specific posts:
- https://community.datastax.com/questions/9525/can-i-use-byos-jar-at-the-same-time-as-dse-java-dr.html
- https://community.datastax.com/questions/734/in-a-byos-approach-what-is-the-minimum-config-requ.html
One could be forgiven for thinking that we would be able to stop at six dependencies, but alas, there is yet one more: the dse-spark-dependencies dependency. According to the Datastax blog:
“[The dse-spark-dependencies library] instructs a build tool to include all dependency JAR files that are distributed with DSE and are available in the DSE cluster runtime classpath. These JAR files include Apache Spark JARs and their dependencies, Apache Cassandra JARs, Spark Cassandra Connector JAR, and many others. Everything that is needed to build your bootstrap Spark Application is supplied by the dse-spark-dependencies dependency. To view the list of all dse-spark-dependencies dependencies, visit our public repo and inspect the pom files that are relevant to your DSE cluster version.”
As noted in the same blog post, this is specifically for use with a DSE Analytics-enabled (i.e., Spark-enabled) cluster.
DSE spark dependencies is for when executing your jar on Spark from a DSE analytics cluster, in contrast to BYOS, which is for when running on external Spark.
According to the Datastax blog and the dse-spark-dependencies pom file (as of v. 6.8.9):
- DSE Java Driver Core (as of DSE 6.7.7, that’s DSE Java Driver 1.7.1)
- DSE Spark Cassandra Connector (note that this is not the same as the OSS SCC mentioned above, but comparable)
- DSE GraphFrames
- Apache Spark JARs and their dependencies
- https://docs.datastax.com/en/dse/6.8/dse-dev/datastax_enterprise/spark/sparkJavaApi.html
- Overview of which dependencies to use for connecting to C* from Spark. It’s a little bit outdated though, from May 2017. Note also that it does not discuss when to use BYOS.
- https://community.datastax.com/questions/734/in-a-byos-approach-what-is-the-minimum-config-requ.html
- https://community.datastax.com/questions/9525/can-i-use-byos-jar-at-the-same-time-as-dse-java-dr.html
- Example code repo provided by Datastax for Spark + Cassandra
A chart to summarize what gets included into what might be helpful here:
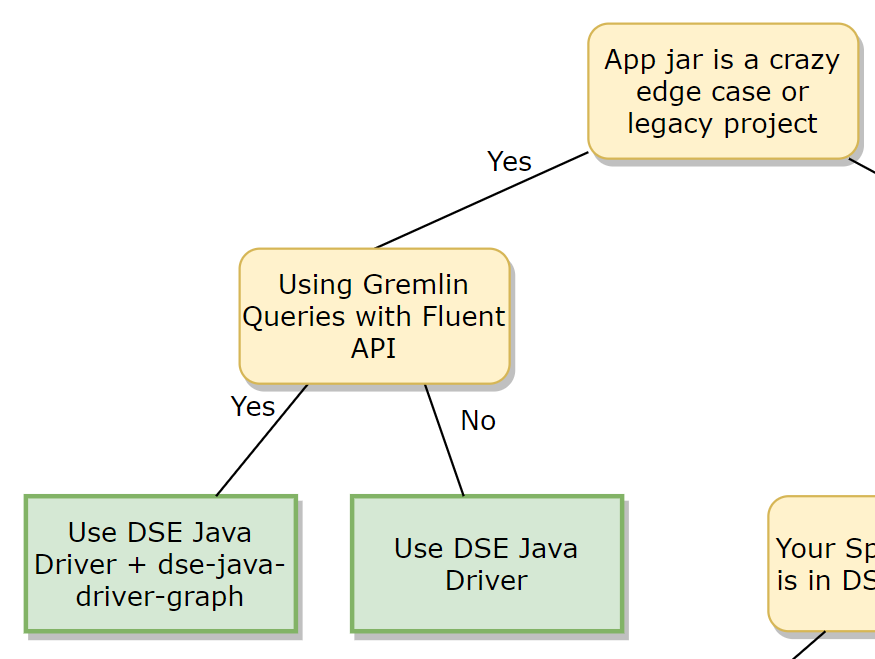
If we gloss over some details, we can also give a rough decision tree as well:
In summary, depending on your use case, Datastax has put out a number of very helpful libraries, and in general each individual library is fairly well documented. The problem is that there is not as much documentation describing how all of these libraries relate to each other, and when to use which library when. I can understand if this hasn’t been much of a page-turner, but hopefully this post will help to keep things straight somewhat.
P.S., I apologize in advance for broken links, which are bound to arise as time passes and pages move. If you find some, please let me know and we can keep this post updated for future readers.





