On one of my current projects we are using Cassandra and Spark Streaming to do some somewhat-close-to-real time analytics. The good folks at Datastax have built a commercial packaging (Datastax Enterprise, aka DSE) of Cassandra and Spark that allow you to get this stack up and running with relatively few headaches. One thing the Datastax offering does not include is a way to aggregate logs across all of these components. There are quite a few processes running across the cluster, each producing log files. Additionally, spark creates log directories for each application and driver program, each with their own logs. Between the high count of log files and the fact that work happens on all the nodes different each time depending on how the data gets partitioned- it can become a huge time sink to hunt around and grep for the log messages that you care about.
Enter the ELK stack. ELK is made up of three products:
- Elasticsearch – a distributed indexing and search platform. It provides a REST interface on top of a fancy distributed, highly available full text and semi-structured text searching system. It uses Lucene internally for the inverted index and searching.
- Logstash – log aggregator and processor. This can take log feeds from lots of different sources, filter and mutate them, and output them somewhere else (elasticsearch in this case). Logstash is the piece that needs to know about whatever structure you have in your log messages so that it can pull the structure out and send that semi-structured data to elasticsearch.
- Kibana – web based interactive visualization and query tool. You can explore the raw data and turn it into fancy aggregate charts and build dashboards.
All three of these are open-source, Apache 2 licensed projects built by Elastic, a company founded by the folks that wrote Elasticsearch and Lucene. They have all of the training, professional services, and production support subscriptions, and a stable of products with confusing names that you aren’t quite sure if you need or not…
So how does this look at a high level? Spark and Cassandra run co-located on the same boxes. This is by design so that your Spark jobs can use RDDs that use a partitioning scheme that is aware of Cassandra’s ring topology. This can minimize over-the-wire data shuffles, improving performance. This diagram shows at a high level where each of these processes sit in this distributed environment:
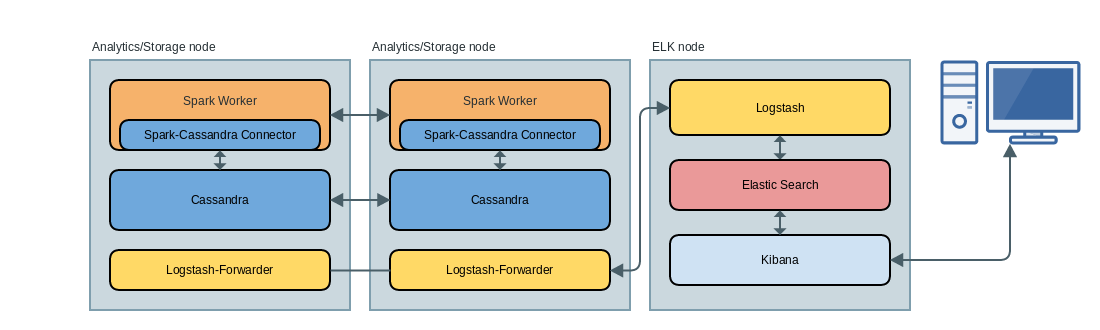
This only depicts two “analytics” nodes and one ELK node, but obviously you will have more of each. Each analytics node will be producing lots of logs. Spark writes logs to:
- /var/log/spark/worker
- /var/lib/spark/worker/worker-0/app-{somelongtimestamp}/{taskslot#}
- /var/lib/spark/worker/worker-0/driver-{somelongtimestamp}
To collect all of these logs and forward, there is an agent process on each node called Logstash-Forwarder that is monitoring user specified folders for new log files and is shipping them over via TCP to the actual logstash server process running on the ELK node. Logstash receives these incoming feeds, parses them and sends them to elasticsearch. Kibana responds to my interactive queries and delegates all of the search work to elasticsearch. Kibana doesn’t store any results internally or have its own indexes or anything.
Others have already done a good job explaining how to setup ELK and how to use Kibana, and therefore I won’t repeat all of that here. I will only highlight some of the differences, and share my Logstash configuration files that I had to create to handle the out-of-the-box log file formats for Cassandra and Spark (as packaged in DSE 4.7 at least).
I installed elasticsearch from the repo, which already created the systemd entries to run it as a service. Following the ELK setup link above, I created systemd entries for logstash and kibana. I also created a systemd unit file for the logstash-forwarder running on each analytics node.
The logstash-forwarder needs to be configured with all of the locations that spark and cassandra will put logfiles. It supports glob syntax, including recursive folder searches like “whatever/**/*.log”, but I ended up not using that because it was duplicating some of the entries due to a wonky subfolder being created under the spark driver program log folder called cassandra_logging_unconfigured. My forwarder configuration picks up all of the output logs for the workers, the applications, and the driver and creates a different type for each: spark-worker for generic /var/log spark output, spark-app for app-* log folder, spark-driver for the driver programs (where most of the interesting logging happens). My logstash-forwarder.conf is in the gist.
For logstash I setup a few files as a pipeline to handle incoming log feeds:
- 00_input.conf – sets up the lumberjack (protocol the forwarder uses) port and configures certs
- 01_cassandra_filter.conf – parses the logback formats that DSE delivers for cassandra. Im not sure if vanilla open-source cassandra uses the same by defualt or not. There are two formats between sometimes there is an extra value in here — possibly from the logback equivalent of NDC.
- 02_spark_filter.conf – parses the logback formats that DSE delivers for spark. I see there are two formats I get here as well. Sometimes with a line number, sometimes without.
- 07_last_filter.conf – this is a multiline filter that recognizes java stacktraces and causes them to stay with the original message
- 10_output.conf – sends everything to elasticsearch
All of my configuration files are available through the links above in this gist. Between the linked guides above and the configuration here that should get you going if you need to monitor cassandra and spark logs with ELK!
Quick tip: While you’re getting things configured and working, you might need to kill the currently indexed data and resend everything (so that it can reparse and re-index). The logstash-forwarder keeps a metadata file called .logstash-forwarder in the working directory where you started the forwarder. If you want to kill all of the indexed data and resend everything, follow these steps:
- Kill the logstash-forwarder:
sudo systemctl stop logstash-forwarder - Delete the logstash-forwarder metadata so it starts from scratch next time:
sudo rm /var/lib/logstash-forwarder/.logstash-forwarder - If you need to change any logstash configuration files, do that and then restart logstash:
sudo systemctl restart logstash - Delete your existing elastic search indexes (be careful with this!):
curl -XDELETE 'http://:9200/logstash-*' - Start the logstash-forwarder again:
sudo systemctl start logstash-forwarder
Also note that by default the logstash-forwarder will only pickup files less than 24 hours old. So if you’re configuring ELK and playing with filters on stagnant data, make sure at least some files are touched recently so it will pick them up. Check out the log file in /var/log/logstash-forwarder to see if it’s skipping particular entries. You can also run the logstash-forwarder with -verbose to see additional debug information.
Quick tip: use the wonderfully useful http://grokdebug.herokuapp.com/ to test out your grow regex patterns to make sure they match and pull out the fields you want.
| Reference: | Using ELK (elasticsearch + logstash + kibana) to aggregate cassandra and spark logs from our JCG partner Steve Ash at the Many Cups of Coffee blog. |