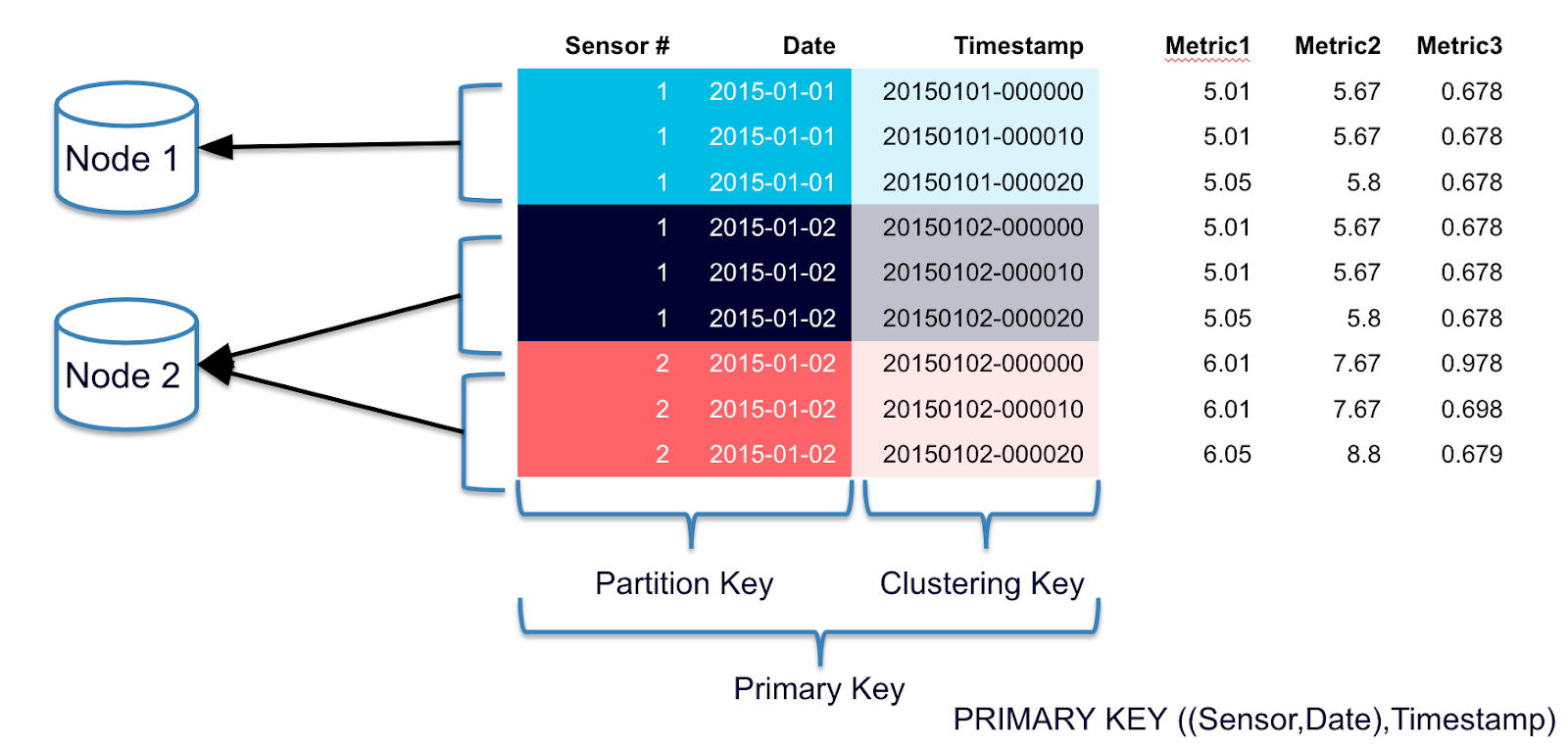
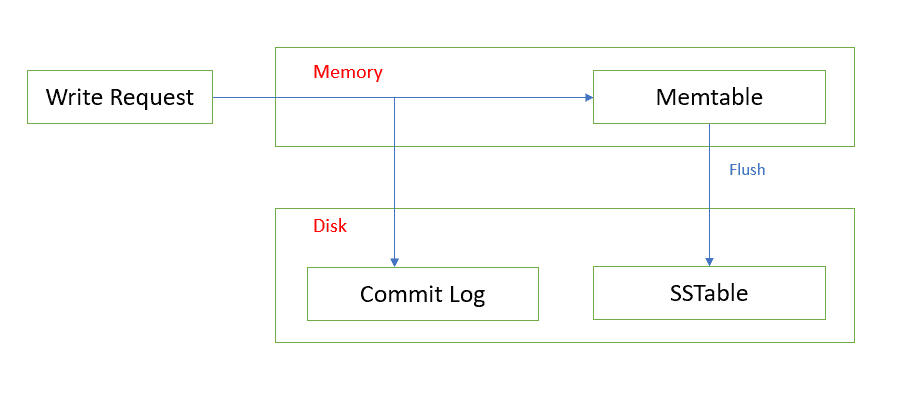
RubyScale — Understanding the Cassandra Data Model from a SQL... Sounds perfect Wahhhh, I don’t wanna If you come from the SQL world, sometimes it can be difficult to understand the Cassandra Data Model and all that it implies in terms of management and scalability. For this post, we’re going to go backwards. Instead of writing an example application using Cassandra to understand it, I’ll describe implementing Cassandra on a traditional SQL database and what that would look like.1. Mapping a Column Family to SQL TablesIn Cassandra, a Column Family has any number of rows, and each row has N column names and values. For this example, let’s assume that in Cassandra we have a Users Column Family with uuids as the row key and column name/value pairs as attributes such as username, password, email, etc. If we had 10000 such users, then in SQL we’d have 10000 tables that looked like the following where 91b56770-bf40-11df-969c-b2b36bca998e was the actual uuid of a user:CREATE TABLE users-91b56770-bf40-11df-969c-b2b36bca998e (column_name varchar, column_value varchar) UNIQUE column_name PRIMARY KEY column_name;INSERT INTO users-91b56770-bf40-11df-969c-b2b36bca998e VALUES ('username', 'joe'), ('password', 'weak'), ('email', 'joe@example.com');10000 tables! That’s right, 10000 tables. In SQL, that many tables would be absurd but Cassandra is designed to scale that way and lots of rows are encouraged as it helps load balancing and scalability. In fact, millions and billions of rows are the norm. You can think of Cassandra as a system that distributes these tables over many nodes with some consistency and replication guarantees.You said N rows, but then said a table is on a single node. You don’t really mean N do you? No, not really. A row has to fit on a single node just like a table has to fit on a single machine for most SQL implementations. For older versions of Cassandra, a row also had to fit in RAM.It looks like I can only query one user at a time and I already have to know his UUID. Is that true? In SQL terms, Cassandra can perform table ranges and row slices on table ranges. In Cassandra terms, you can get a slice of keys and a slice of columns within those keys. This is what is meant by ‘column-oriented key-value store’. One thing you don’t get to do is join. Cassandra does not join. Cassandra does not join. If you want to join, you do it in your application.What is a Column Family for then? Just a table prefix? A Column Family has a number of settings that go with it that alter it’s behavior. There are cache settings for the keys (the UUIDs in this example), cache settings for the entire rows (the entire table in this example), and most importantly, sorting. In Cassandra there is no OFFSET, only LIMIT and the equivalent of BETWEEN. In this example, the column names are just strings but they could also be integers or timestamps and they are always stored in sort order. One Column Family might have timestamp-sorted data where you query things by time slice and another might be address book data where you query things in alphabetical order. The only sorting you get to do after the fact is reversing a particular slice. What if I want to sort by column value and by column name? Then you have two Column Families, one sorted by whatever datatype your column names are, and one sorted by whatever your column values are.So if I wanted to find the user who had a particular email address, how would I do that? I don’t know what table to query! Exactly! If you want to answer that question, you’ll have to make another Column Family that keys on e-mail address and points to the UUID of the user that has it, then you can query the relevant users table. Think about it this way .. in SQL, you can CREATE INDEX for things you want to query and in Cassandra, you have to manually maintain that index. (Secondary indexes are present in 0.7+, but I’ll cover that another time.)In SQL, I can still do a full table scan to pull out the information I’m looking for. Why can’t Cassandra do that? You can iterate with Cassandra and functionally get the same result, but I wouldn’t if I were you.But if I have two Column Families with the same data sorted differently, that’s denormalized. I heard that was bad. Denormalization is the norm with Cassandra. This is a complicated topic but in short, denormalization is a requirement for linear horizontal scaling and many people were already doing this in their SQL databases to avoid joins anyway.Wait, there is no OFFSET? How do I paginate with cassandra? Awkwardly. You have to start at the beginning, get N items, then on the next page you’d have to start at the last of the previous items and get N+1, throwing away the first one, etc. Alternately, you can create another Column Family which caches pages but in general, pagination is not what Cassandra was designed for.2. Mapping a Super Column Family to SQL tablesA Super Column Family is exactly like a Column Family, except you get one more column in your table. For this example, we’ll make an address book.CREATE TABLE addressbooks-91b56770-bf40-11df-969c-b2b36bca998e (super_column_name, column_name varchar, column_value varchar) UNIQUE (super_column_name, column_name) PRIMARY KEY super_column_name;INSERT INTO addressbooks-91b56770-bf40-11df-969c-b2b36bca998e VALUES ('bob', 'street', '1313 Mockingbird Lane'), ('bob', 'city', 'Chicago'), ('bob', 'state', 'IL');INSERT INTO addressbooks-91b56770-bf40-11df-969c-b2b36bca998e VALUES ('alice', 'street', '123 Foo St.'), ('alice', 'city', 'Kona'), ('alice', 'state', 'HI');Do the column_names have to be the same for each Super Column? No.Can the super_column_name and column_name be sorted differently? Yes.Does the entire table still have to fit on one node or does it split out the Super Columns? The entire row still has to fit on one node.Is there a limit to how many Columns can be in a Super Column? Other than the space limitation already mentioned, theoretically, no. There is one gigantic caveat: Accessing a single Column in a Column Family is efficient and fast. Accessing a single Column in a Super Column ('city’ or 'state’ in this case) requires deserialization of the entire Super Column. For this example, this means that to get alice -> state, Cassandra has to load everything in the alice super column. For an addressbook, this doesn’t really matter but if you had 1000 columns and a read-heavy load, it could heavily impact performance since you’d have to deserialize all 1000 columns just to get one of them.It sounds like Super Column Families can be dangerous if I’m not careful. Exactly! They were designed specifically for inverted indexing. If you aren’t doing that or don’t know what that is, don’t use them.3. Transactions and/or RollbacksCassandra does neither transactions nor rollbacks. I you want those, some other thing such as Cages/ZooKeeper has to do that.Next PostTo learn more about how these tables would be replicated and queried, continue on to the next post, Replication Factor and Consistency Levels.If you read the last post, Understanding the Cassandra Data Model from a SQL Perspective, then you already have a decent handle on what a column-oriented key/value store is. The next thing that tends to confuse new users of Cassandra is the notion of Consistency Level and Replication Factor. This post doesn’t really have a lot to do with SQL in particular, it’s more of a discussion about how tables would be replicated across multiple servers and how you read/write from those tables.1. Replication FactorIn the previous post, we described how every single Cassandra Row would be a separate table in SQL with an arbitrary number of rows. The Replication Factor (aka ‘RF’) determines how many nodes have a copy of that table. If you have 10 nodes and your RF=3, then every single table will exist on 3 nodes. Table users-91b56770-bf40-11df-969c-b2b36bca998e might exist on nodes 2 through 4 and users-28b56770-b410-15ef-968c-b2c36d511e78 might exist on nodes 6 through 8.Can the RF be any number? Anything one or higher works but make sure it’s not higher than the actual number of nodes you have. This may be fixed by now but it used to be handled ungracefully. In general it should also be an odd number >=3 so that quorum is a useful consistency level (for more details on this, keep reading).How do I know which node to query to get my data if it could be anywhere? Do I have to know where to write it? Each node acts as a storage proxy for every other node. If you query node 5 for data that is on nodes 8-10, it knows to ask one or more of those nodes for the answer. This is also true of writes.What if a node goes down? How do I synchronize them? What if they have different values? This will be covered in the next section, Consistency Levels.2. Consistency LevelConsistency in Cassandra is Eventual, which is to say that the N nodes responsible for a particular table could have a slightly different opinion of what it’s contents are. That’s ok! When reading from or writing to a Cassandra cluster, you can tune the tolerance for that sort of tomfoolery by reading or writing at a varying Consistency Level (aka 'CL’). Remember that each node acts as a proxy for every other node so you don’t have to worry about which node you are interacting with (unless you are really trying to optimize network activity but in general, this is unnecessary).CL::ALL will not return success unless it has successfully written the same value to every node responsible for holding whatever you are writing. Using CL::ALL, you can guarantee that whatever you are writing is the same on all nodes when success is returned. There is of course a performance penalty for this, but in return you get very strong Consistency. Reading at CL::ALL functions in a similar way .. if one of the nodes does not respond, it will return an error since it cannot guarantee that all of the nodes are consistent for the value in question.CL::QUORUM only requires a majority of the nodes responsible for a table to respond instead of all of them. This allows for one or more nodes to be down or otherwise unavailable and still have your read/write return. If your RF=3, then only 2 nodes responsible for a table need to be online in order to reliably manipulate the data in that table. Note that if RF=1 or RF=2 then there is no meaningful difference between CL::ALL and CL::QUORUM so if you want the benefits of CL::QUORUM, make sure your RF>=3.CL::ONE requires that only one of the nodes responsible for a table respond. This makes reads and writes fast, but it also means that depending on what else is reading and writing, it’s possible that they could briefly give conflicting answers. This is a fine tradeoff for speed in many applications, but not all. For example, recording votes or website hits where the outside possibility of a few going missing on machine failure is probably fine. Recording a financial transaction of some sort, probably not so much.CL::ANY is only used for writing, not reading. CL::ANY means that as soon as a write is received by any node, the call returns success. This occurs when your client might be connecting to node 5 but the nodes responsible for it are 6-8. The difference between CL::ONE and CL::ANY is that with CL::ANY, as soon as node 5 receives the write, it returns success (but nodes 6-8 could be down or whatever). CL::ONE means that if you write to node 5, either 6, 7, or 8 have to return success before node 5 returns success.OK .. so if I use CL::ALL and it fails, does that mean that my write failed? Not necessarily! It may have succeeded on two nodes and failed on the third which means that eventually it will be propagated to the third, but the required guarantee was not met.Uh .. ok. So if that happens, how do I know that any of my writes succeeded? You don’t! At least not yet. The error doesn’t indicate percentage of success, just failure. Not great, I know.I have multiple datacenters. How do I tell Cassandra to put some data in each? There are various strategies and snitches that tell Cassandra where to put things and they are constantly in flux. You can also write your own if you have specific requirements. For more information, see the Cassandra Wiki.What happens if I write at CL::ANY and that node explodes before it can send data to where it belongs? Congratulations, you just lost data. If you can’t tolerate that, don’t use CL::ANY.What happens if all 3 nodes are up, but have different values for something for some reason and I read at CL::ALL. Does it give me the finger or what? Cassandra performs 'read repair’. That is, upon reading, if you are using a CL that requires more than one node and they disagree on the value, Cassandra will compare the values and use whichever one has the latest timestamp. It will also write that value back to the node which had an outdated value hence 'repairing it’.What if a node goes offline for a whole day, then comes back and has all sorts of wonky outdated data. Is there a way to fix it all at once instead of on read? That sounds expensive and slow to do all ad-hoc. Indeed it is! You can initiate a complete 'repair’ of a node after a failure like that using nodetool.Cassandra-cql has been updated for the latest version of cassandra. It supports all of the datatypes and has proper encoding support for ruby 1.9. It is also now published as a gem so a simple ‘gem install cassandra-cql’ should get you ready to roll with Ruby and Cassandra.The official location for the code is now Google Code but I also use the Cassandra-CQL github repo if you want to participate that way. For a quick introduction on usage, check out the Google Code Wiki.Enjoy!Our recently-released Cassandra storage plugin for paperclip was lacking one thing: the ability to specify read/write consistency levels. Well, now you can just by adding the following options to your has_attachment specification (these are the defaults, btw).:read_consistency => Cassandra::Consistency::ONE:write_consistency => Cassandra::Consistency::QUORUMEnjoy!Cassandra Query Language (CQL)Cassandra originally went with a Thrift RPC-based API as a way to provide a common denominator that more idiomatic clients could build upon independently. However, this worked poorly in practice: raw Thrift is too low-level to use productively, and keeping pace with new API methods to support (for example) indexes in 0.7 or distributed counters in 0.8 is too much for many maintainers.CQL, the Cassandra Query Language, addresses this by pushing all implementation details to the server; all the client has to know for any operation is how to interpret “resultset” objects. So adding a feature like counters just requires teaching the CQL parser to understand “column + N” notation; no client-side changes are necessary.(CQL Specification: github.com/apache/cassandra/blob/trunk/doc/cql/CQL.textile)Cassandra-CQL For RubyCassandra-CQL implements a DBI-like interface on top of CQL in Ruby that should be familiar to anybody who has worked with a traditional RDBMS before. It is not yet released as a gem as it will shortly be included in Apache Extras and distributed from there. To get started developing with it now, just clone it from Github and build/install the gem locally with ‘rake install’.(Github:http://github.com/kreynolds/cassandra-cqlIt’s been a while since the last release of the cassandra-cql gem, and this version fixes a few long-standing encoding and data-access bugs as well as support for CQL3. The driver now also uses Travis for continuous integration.The largest improvement is the ability to cast single columns at a time. One of the major pain points previously was that if a column in Cassandra had existing data and it’s validation changed to make that data invalid (empty string in an Integer-validated column for instance), none of the data in that row would be accessible as the entire row was casted at once. Each column is now individually casted and cached and if there is invalid data in a validated column, it will raise a CastException that contains a useful description of the problem as well as the bytes that raised the exception.Another important bug fix is for character encoding in Ruby 1.9. The previous version incorrectly used ASCII-8BIT on data retrieved from ASCII-validated columns which when stored back into Cassandra, would encode it as binary. A simple change to US-ASCII in the casting has fixed that.gem install cassandra-cqlEnjoy!editors note: as of 7 Mar 2012, this info is still current and correct.One of the most common use cases for Cassandra is tracking time-series data. Server log files, usage, sensor data, SIP packets, stuff that changes over time. For the most part this is a straight forward process but given that Cassandra has real-world limitations on how much data can or should be in a row, there are a few details to consider.Basic Inserts and QueriesThe most basic and intuitive way to go about storing time-series data is to use a column family that has TimeUUID columns (or Long if you know that no two entries willhappen at the same timestamp), use the name of the thing you are monitoring as the row_key (server1-load for example), column_name as the timestamp, and the column_value would be the actual value of the thing (0.75 for example):Inserting data – {:key => ‘server1-load’, :column_name => TimeUUID(now), :column_value => 0.75}Using this method, one uses a column_slice to get the data in question:Load at Time X – {:key => 'server1-load’, :start => TimeUUID(X), :count => 1}Load between X and Y – {:key => 'server1-load’, :start => TimeUUID(X), :end => TimeUUID(Y)}This works well enough for a while, but over time, this row will get very large. If you are storing sensor data that updates hundreds of times per second, that row will quickly become gigantic and unusable. The answer to that is to shard the data up in some way. To accomplish this, the application has to have a little more intelligence about how to store and query the information.For this example, we’ll pick a day as our shard interval (details on picking the right shard interval later). The only change we make when we insert our data is to add a day to the row-key:Inserting data – {:key => 'server1-load-20110306’, :column_name => TimeUUID(now), :column_value => 0.75}Using this method, one still uses a column slice, but you have to then also specify a different row_key depending on what you are querying:Load at Time X – {:key => 'server1-load-<X.strftime>’, :start => TimeUUID(X), :count => 1}Load between Time X and Y (if X and Y are on the same day) – {:key => 'server1-load-<X.strftime>’, :start => TimeUUID(X), :end => TimeUUID(Y)}Now what to do if X and Y are not on the same day? No worries! You can use a multi-get to fetch more than one key at a time (or issue parallel gets for maximum performance). If your X and Y span two days, you just need to generate keys for those two days and issue them in a multiget:Load between Time X and Y – {:key => ['server1-load-<X.strftime>’, 'server1-load-<Y.strftime>’], :start => TimeUUID(X), :end => TimeUUID(Y)}Then in your application, you will need to aggregate/concatenate/iterate those two rows however you see fit. If your data spans 3 or more days, you’ll need to also generate every key in between. Don’t be tempted to use the Order-Preserving Partitioner here, it won’t save you that much typing and it’ll will make managing your cluster much more difficult.Calculating Shard SizeNow on the topic of determining your shard interval .. that’s a complicated topic that is often application dependent but the single biggest issue is to make sure your rows don’t get too big. The better you are at the ops side of Cassandra, the larger you can let your rows get but if I have to tell you that, you should keep them small. A quick ballpark formula for determining shard size is as follows (yes rcoli, it ignores overhead):shard_size_in_seconds / update_frequency * avg_data_size_in_bytes == row_size_in_bytesSet your shard size so that the row_size doesn’t get much larger than 10MB (this number can move around for many reasons but I’d consider it safe). For example, if you are storing hits on a website that gets 10 hits/sec and each entry is about 200B, then we have:Daily – 86400 / (1 / 10) * 200 = 172800000 (165MB)Hourly – 3600 / (1 / 10) * 200 = 7200000 (6.9MB)Looks like sharding this up on hours hits our target row size. Of course you can use any shard size you want, 6 hours, 2 hours, seconds, months, whatever. If you code up your application properly, it should be easy to adjust. Even if you decide to change your shard partway through the life if your application, you just have to know that before a certain point, use keys with one format, and after a certain point, use another, it’s that simple.Indexing and AggregationIndexing and aggregation of time-series data is a more complicated topic as they are highly application dependent. Various new and upcoming features of Cassandra also change the best practices for how things like aggregation are done so I won’t go into that. For more details, hit #cassandra on irc.freenode and ask around. There is usually somebody there to help.These have already been sent to the port maintainers so they should find their way into the ports collection soon enough but if you can’t wait, here are some scripts for pfstat (pfstatd in particular) and cassandra./usr/local/etc/rc.d/pfstatd#!/bin/sh# PROVIDE: pfstatd# REQUIRE: LOGIN# BEFORE: securelevel# KEYWORD: shutdown# Add the following lines to /etc/rc.conf to enable `pfstatd':## pfstatd_enable="YES"# pfstatd_flags=""## See pfstat(1) for pfstatd_flags#. /etc/rc.subrname="pfstatd"rcvar=`set_rcvar`command="/usr/local/bin/pfstatd"# read configuration and set defaultsload_rc_config "$name": ${pfstatd_enable="NO"}run_rc_command "$1"/usr/local/etc/rc.d/cassandra#!/bin/sh# PROVIDE: cassandra# REQUIRE: LOGIN# BEFORE: securelevel# KEYWORD: shutdown# Add the following lines to /etc/rc.conf to enable `cassandra':## cassandra_enable="YES"# cassandra_flags=""## See cassandra(1) for cassandra_flags#. /etc/rc.subrname="cassandra"procname="java"rcvar=`set_rcvar`command="/usr/local/share/cassandra/bin/cassandra"pidfile="/var/run/$name.pid"command_args="-p ${pidfile}"# read configuration and set defaultsload_rc_config "$name": ${cassandra_enable="NO"}run_rc_command "$1"I’m sure you were expecting another post with a brief topical analysis of why Facebook chose HBase instead of Cassandra with some similarly topical and mostly incorrect summary of how those two systems work and why one is better than the other one.Sorry to disappoint, but rather than pour more fuel on what is already a pointless fire, I’m going to suggest instead that you look at what your application and your business requires for success and can operationally support. That might mean that you need transactional rollback so Cassandra won’t work straight up, or that you already have HDFS for other jobs so HBase is easier to support than adding on an entirely new technology.Regardless, please take the time to understand the systems and realize that the choices one company makes aren’t necessarily the same choices you should make for many reasons, technical and otherwise.I recently had a conversation in #cassandra about the Data Model that I thought might be useful to try to distill into a few lines. These few lines ignore all of the implementation details to make it work in practice but it gives you the starting point. It looks a little something like this …Keyspace - What method should I use to turn my application key into a Row Key?Row Key - Which Node is my value on?Column Family - Which file on the node is my value in?Column Name - Which piece of the file on the node contains my value?Column Value - My value!Since the columns are already sorted in the file, getting a slice of them is very efficient, and this is what makes Cassandra a column-oriented database. It’s worth noting that with most Cassandra clients, the Row Key and the Column Family are almost always conceptually swapped because it’s more common to access multiple keys in the same column family than to access multiple column families with the same key. Given the above, let’s revisit some of the other concepts that are required to make it work in practice.PartitionerThe partitioner determines how your application keys get turned into Row Keys. RandomPartitioner (which should be called HashedPartitioner in my opinion) takes an MD5 of the key and uses that as the Row Key and ByteOrderedPartitioner uses the key unmodified.Replication Factor and Replica Placement StrategyReplicationFactor determines how many nodes get a copy of a particular key. There is no master/slave thing going on here, it’s just how many nodes get a copy of a key. The Strategy determines which exact nodes get a copy of your key based on network topology or ring placement.Consistency LevelsMost relevant when the ReplicationFactor > 1, the ConsistencyLevel determines how many nodes have to successfully record a write or agree on the value of a read for the operation to be considered successful. There are tables of consistency levels and what exactly they mean in multiple places so I won’t repeat them here.Memtables, Commitlog, SSTables, and CompactionAs writes come in to a ColumnFamily, they are simultaneously (don’t argue) stored in memory in a memtable and written out to disk in a commitlog. The memtable is periodically written out to disk in in column-order as an sstable for efficient slicing later. Over time, a column could exist in a memtable and/or multiple sstables at once so a timestamp is used to determine which one to use, highest one wins. The timestamp is supplied by the client and can be any integer. Over time, you get a number of sstables and a process called compaction combines them all and throws away the out of date stuff to save space. Back to the commitlog, that’s there so that if the node explodes while some things are only in a memtable, they get replayed when the node starts back up so no data is lost (durability). Since the commitlog is serial write-only, if you put it on a separate disk, you can accept writes really fast.MiscellaneousYou can ask any node anything, they all act as proxies for one another.If your ReplicationFactor > 1, then ReadRepair will propagate the most recent column value to the nodes responsible or it.There are various operations in nodetool that let you move nodes, add nodes, clean out old data/keys, manually compact things, repair everything at once, get statistics about each node, etc.Gossip is used to propagate node status and information to other nodes.Cassandra works in a complicated problem space and there are many subtle operational and technical details that aren’t covered her, but this is the gist of it.Mi Casa Verde. You can read the specifications of the devices for yourself but I like them because they are inexpensive, have low-power requirements, are capable of interfacing with a number of different kind of home automation systems, and most importantly, have a documented JSON/XML API. Coincidentally, they also have adeveloper special programand lack a ruby gem, so another rainy day project is born!The operating system these devices run is called MiOS which is essentially Linux/ARM and lots of glue. Mi Casa Verde operates a free VPN service that allows you to operate them remotely, and there are a number of free/paid smartphone apps available (though none struck me as particularly special). All of the interactions with MiOS work on a job queue basis. When a job is submitted, it’s status must be polled for success/failure. The Ruby library embraces this and allows jobs to be run synchronously or asynchronously.Some snippets from the github page:mios = MiOS::Interface.new('http://192.168.15.1:3480')switch = mios.devices[0]switch.off! { |obj| puts "The #{obj.name} is now off"}puts "This will get printed once the switch is off and the block has been executed"switch.on!(true) { |obj| puts "The #{obj.name} is now on"}puts "This will output immediately"sleep(5) # Sleep to wait for the thread to finishEvery device is supported by manually issuing commands as listedin the wiki and the devices that I currently use have nice wrappers around those for idiomatic usage (example).Installation instructions and additional usage examples can be found on github under theruby-mios project.Enjoy! See this in the app Show more