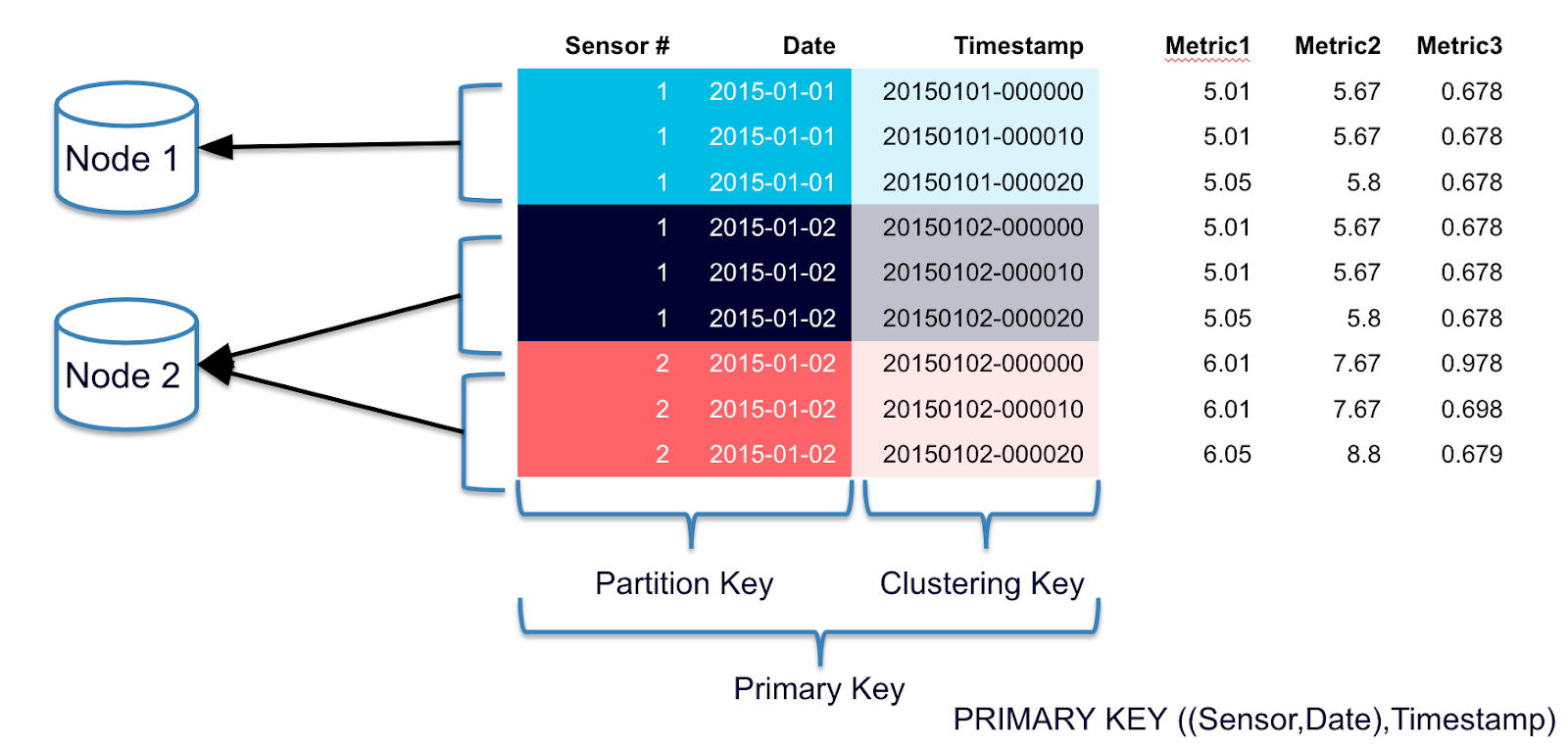
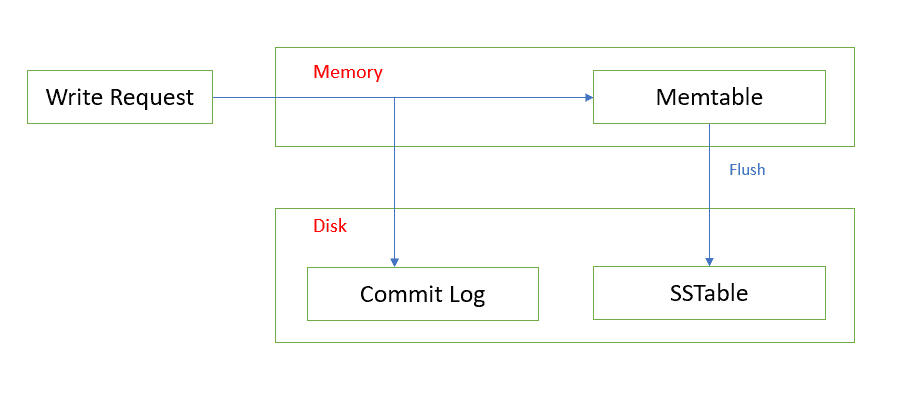
Extremely overdue that I write this down as it’s a common problem, and really applies to any database that needs to scale horizontally, not just Cassandra.
Problem Statement
Good partition keys are not always obvious, and it’s easy to create a bad one.
Defining A Bad Partition
- Uneven Access. Read OR write count is more than 2x different from one partition to another. This is a purist view and some of you using time series are screaming at me right now, but set that aside, I’ll have another blog post for you, but if you’re new to Cassandra consider it a good principle and goal to aim for.
- Uneven Size. Same as above really you can run cfhistograms and if you see really tiny or empty partitions next to really large ones or ones with really high cell count, you are at least on ingest uneven. I would shoot for within an order of magnitude or two. If you’re smart enough to tell me why I’m wrong here that’s fine, I’m not gonna care, but if you’re new to Cassandra this is a good goal.
- Too Many Cells. The partition cell count for a given partition is over 100k (run cfhistograms to get these numbers). This is entirely a rule of thumb and varies amazingly between hardware, tuning and column names (length matters). You may find you can add more and not hit a problem and you may find you can’t get near this. If you want to be exacting you should test.
- Too Large. Your partition size is over 32mb (also in cfhisograms). This also varies like cell count. Some people tell me this matters less now (as of 2.1), and they run a lot larger. However, I’ve seen it cause problems on a number of clusters. I repeat as a new user this is a good number to shoot for, once you’re advanced enough to tell me why I’m wrong you may ignore this rule. Again you should test your cluster to get the number where things get problematic.
Options if you have a bad partition
- Pick a better partition key (read http://www.datastax.com/dev/blog/basic-rules-of-cassandra-data-modeling).
- Give up and use Synthetic Sharding.
- Pretend it’s not a problem and find out the hard way that it really is, usually this is at 3 am.
Synthetic Sharding Strategy: Shard Table
Pros
- Always works.
- Easy to parallelize (can be writing to shards in parallel).
- Very very common and therefore battle tested.
Cons
- May have to do shards of shards for particularly large partitions.
- Hard for new users to understand.
- Hard to use in low latency use cases (but so are REALLY large partitions, so it’s a problem either way).
Example Idea
-shard table
CREATE TABLE IF NOT EXISTS shard_table ( id uuid, shard_id uuid, PRIMARY KEY(id, shard_id));
-data table
CREATE TABLE IF NOT EXISTS my_table ( id uuid, shard_id uuid, clustering_id timeuuid, data text, PRIMARY KEY((id, shard_id), clustering_id));
— first you have to query the shard table
SELECT * FROM shard_table WHERE id = 38bea878–3bc9–48ea-9b12–38aefcefb749;
— the shard table returns
— 7bc5204a-f24f-4a1a-8dcc-e19073d3e4d2
— f3836d84-a694–47d5-ba1e-65eea128de13
— and you do queries for each shard (using async in the driver)
SELECT * FROM my_table WHERE id = 38bea878–3bc9–48ea-9b12–38aefcefb749 AND shard_id = 7bc5204a-f24f-4a1a-8dcc-e19073d3e4d2;
SELECT * FROM my_table WHERE id = 38bea878–3bc9–48ea-9b12–38aefcefb749 AND shard_id = f3836d84-a694–47d5-ba1e-65eea128de13;
- ingest will have to first create shards (say every 10k or split up by workers).
INSERT INTO shard_table (id, shard_id) VALUES (38bea878–3bc9–48ea-9b12–38aefcefb749, 7bc5204a-f24f-4a1a-8dcc-e19073d3e4d2);
- insert into my_table using the shard you just created.
INSERT INTO my_table (id, shard_id, clustering_id, data) VALUES (
38bea878–3bc9–48ea-9b12–38aefcefb749, 7bc5204a-f24f-4a1a-8dcc-e19073d3e4d2, 9eb3f56a-bf24-11e5-9912-ba0be0483c18, 'my data');
INSERT INTO my_table (id, shard_id, clustering_id, data) VALUES (
38bea878–3bc9–48ea-9b12–38aefcefb749, 7bc5204a-f24f-4a1a-8dcc-e19073d3e4d2, f84532ba-bf24-11e5-9912-ba0be0483c18, 'my other data');
- repeat insert until you "fill up" the shard with your calculated max.
Synthetic Sharding Strategy: Shard Count Static Column
Pros
- No separate shard table.
- No shards of shards problem
- 2x faster to read when there is a single shard than the shard table option.
- Still faster even when there is more more than a single shard than the shard table option.
Cons
- Maybe even harder for new users since it’s a little bit of a surprise.
- Harder to load concurrently.
- I don’t see this in wide use.
Example Idea
-single table
CREATE TABLE IF NOT EXISTS my_table ( id uuid, shard_count int STATIC, shard_id int, clustering_id timeuuid, data text, PRIMARY KEY((id, shard_id), clustering_id));
— first you have to query the first shard to see if there are more.
SELECT * FROM my_table WHERE id = 38bea878–3bc9–48ea-9b12–38aefcefb749 AND shard_id = 0
— and it returns
- | id |shard_count|shard_id|
— |38bea878–3bc9–48ea-9b12–38aefcefb749|2 |0 |
- |clustering_id |data |
- |9eb3f56a-bf24-11e5-9912-ba0be0483c18|'my data'|
— Since we have more than one shard we can now query the other shard
SELECT * FROM my_table WHERE id = 38bea878–3bc9–48ea-9b12–38aefcefb749 AND shard_id = 1;
You can just update the count as a separate update as you generate new shards or if you know how many shards you'll end up with before you start ingesting.
UPDATE my_table set shard_count = 2 WHERE id = 38bea878–3bc9–48ea-9b12–38aefcefb749 AND shard_id = 0
- ingest into a given shard.
INSERT INTO my_table (id, shard_id, clustering_id, data) VALUES (
38bea878–3bc9–48ea-9b12–38aefcefb749, 0, 9eb3f56a-bf24-11e5-9912-ba0be0483c18, 'my data');
INSERT INTO my_table (id, shard_id, clustering_id, data) VALUES (
38bea878–3bc9–48ea-9b12–38aefcefb749, 0 , f84532ba-bf24-11e5-9912-ba0be0483c18, 'my other data');
- ingesting into another shard.
INSERT INTO my_table (id, shard_id, clustering_id, data) VALUES (
38bea878–3bc9–48ea-9b12–38aefcefb749, 1, f84532ba-bf24-11e5-9912-ba0be0483c18, 'my shard 2 data');
INSERT INTO my_table (id, shard_id, clustering_id, data) VALUES (
38bea878–3bc9–48ea-9b12–38aefcefb749, 1, f84532ba-bf24-11e5-9912-ba0be0483c18, 'my other shard 2 data');
Synthetic Sharding Strategy: Known Shard Count
Pros
- No separate shard table.
- No shards of shards problem
- Not as fast as static column shard count option when only a single shard.
- Easy to grasp once the rule is explained.
- Can easily abstract the shards away (if you always query for example 5 shards, then this can be a series of queries added to a library).
- Useful when you just want to shrink the overall size of the partitions by a set order of magnitude, but don’t care so much about making sure the shards are even.
- Can use random shard selection and probably call it ‘good enough’
- Can even use a for loop on ingest (and on read).
Cons
- I don’t see this in wide use.
- Shard selection has to be somewhat thoughtful.
Example Idea
-single table
CREATE TABLE IF NOT EXISTS my_table ( id uuid, shard_id int, clustering_id timeuuid, data text, PRIMARY KEY((id, shard_id), clustering_id));
— You always assume there are 5 shards. This is useful when you
— just want to shrink the max partition size down and so you throw every record in a different shard.
SELECT * FROM my_table WHERE id = 38bea878–3bc9–48ea-9b12–38aefcefb749 AND shard_id = 0;
SELECT * FROM my_table WHERE id = 38bea878–3bc9–48ea-9b12–38aefcefb749 AND shard_id = 1;
SELECT * FROM my_table WHERE id = 38bea878–3bc9–48ea-9b12–38aefcefb749 AND shard_id = 2;
SELECT * FROM my_table WHERE id = 38bea878–3bc9–48ea-9b12–38aefcefb749 AND shard_id = 3;
SELECT * FROM my_table WHERE id = 38bea878–3bc9–48ea-9b12–38aefcefb749 AND shard_id = 4;
- ingest into a shard.
INSERT INTO my_table (id, shard_id, clustering_id, data) VALUES (
38bea878–3bc9–48ea-9b12–38aefcefb749, 0, 9eb3f56a-bf24-11e5-9912-ba0be0483c18, 'my data');
INSERT INTO my_table (id, shard_count, shard_id, clustering_id, data) VALUES (
38bea878–3bc9–48ea-9b12–38aefcefb749, 0 , f84532ba-bf24-11e5-9912-ba0be0483c18, 'my other data');
- inserting into another shard.
INSERT INTO my_table (id, shard_count, shard_id, clustering_id, data) VALUES (
38bea878–3bc9–48ea-9b12–38aefcefb749, 1, f84532ba-bf24-11e5-9912-ba0be0483c18, 'my shard 2 data');
INSERT INTO my_table (id, shard_count, shard_id, clustering_id, data) VALUES (
38bea878–3bc9–48ea-9b12–38aefcefb749, 1, f84532ba-bf24-11e5-9912-ba0be0483c18, 'my other shard 2 data');
Appendix: Java Example For Async
A lot of folks seem to struggle with async queries. So for example using an integer style of shards this would just be a very simple:
private final Cluster cluster;
private final Session session;
private final PreparedStatement query;
public CassandraDAO(){
cluster = Cluster.Builder.addContactPoint(“127.0.0.1”).build();
session = cluster.newSession();
query = session.prepare(“SELECT * FROM my_table WHERE id = ? and shard_id = ?”);
}public List<String> findDataById(UUID id) {
List<ResultSetFuture> futures = new ArrayList<>(); for (int i = 0; i<5; i++) {
futures.add(session.executeAsync(query.bind(id, i)));
}List<String> dataResults = new ArrayList<>();
for(ResultSetFuture future: futures) {
Result result = future.getUninterruptibly();
dataResults.add(result.getString(“data”));
}
return dataResults;
}