At Yelp, we use Cassandra to power a variety of use cases. As of the date of publication, there are 25 Cassandra clusters running in production, each with varying sizes of deployment. The data stored in these clusters is often required as-is or in a transformed state by other use cases, such as analytics, indexing, etc. (for which Cassandra is not the most appropriate data store).
As seen in previous posts from our Data Pipeline series, Yelp has developed a robust connector ecosystem around its data stores to stream data both into and out of the Data Pipeline. This two-part post will dive into the Cassandra Source Connector, the application used for streaming data from Cassandra into the Data Pipeline.
Data Pipeline Recap
Yelp’s Data Pipeline is an abstraction on top of Apache Kafka (explained in this blog post) and is backed by a schema registry called Schematizer. It currently serves as the backbone of hundreds of use cases at Yelp, ranging from analytics and experimentation to notifications, ranking, and search indexing.
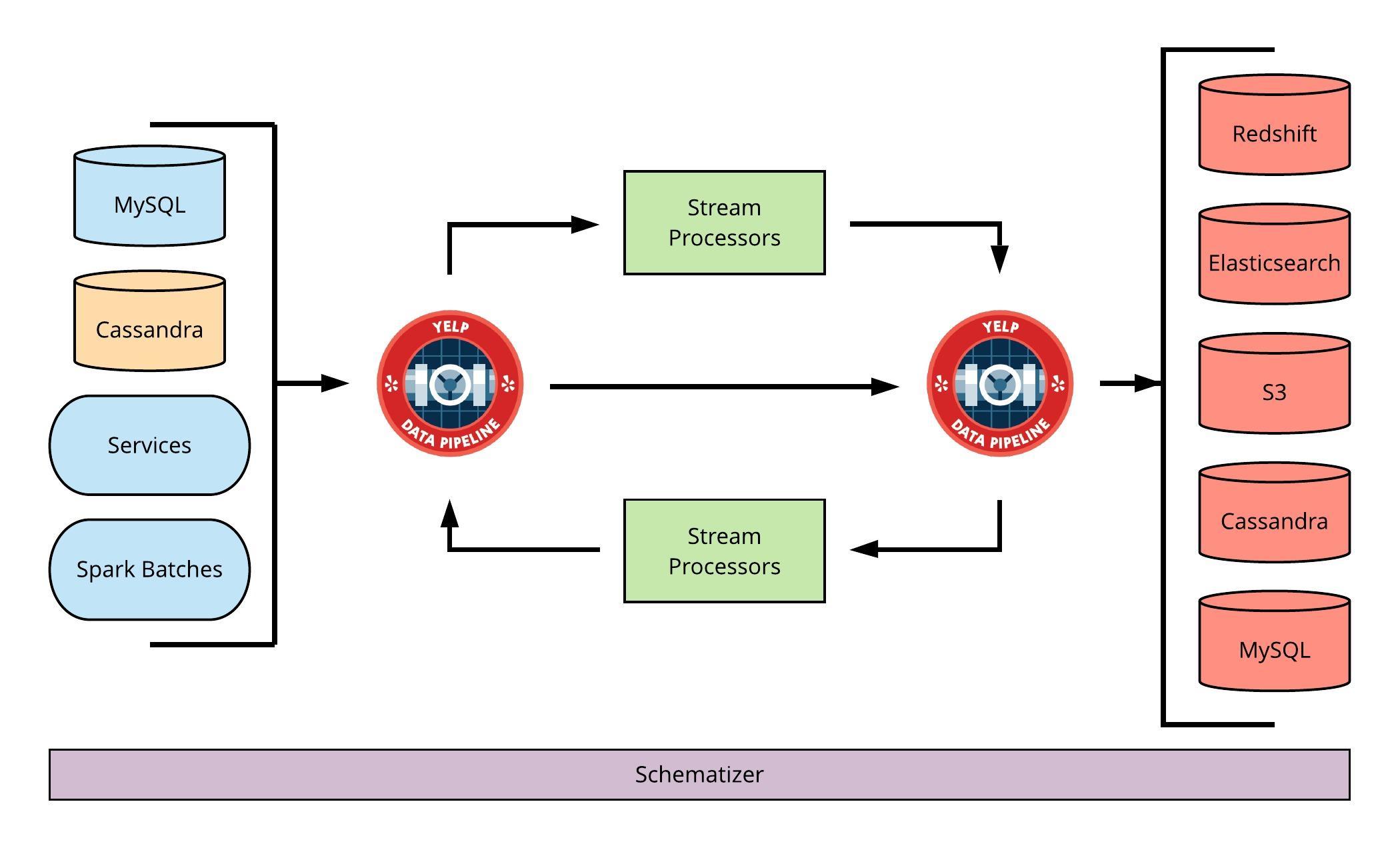
The Data Pipeline Ecosystem at Yelp
Here’s a quick recap of the Data Pipeline:
- Data published into the Data Pipeline must be schematized. In essence, data cannot be published if it doesn’t have a predefined schema.
- For data backed by data stores, the corresponding streams in the Data Pipeline must conform to the stream-table duality.
- Every message in the Data Pipeline must contain the full content of an equivalent row in the data store. In addition, UPDATE and DELETE messages must also contain the previous snapshot of the equivalent row before the change.
Challenges With Streaming Data From Cassandra
Due to the nature of how Cassandra works, meeting the aforementioned Data Pipeline requirements can present some challenges.
Achieving Ordering of Writes
Cassandra uses multiple replicas of data for availability. However, there’s no actual concept of a global replication stream. Each write is independently replicated, with all nodes eligible to coordinate. As a result, concurrent writes may be processed in different orders on different replicas. Cassandra uses several mechanisms (hinted handoffs, repairs, last write wins) to ensure that data is eventually consistent. Although the replicas eventually agree on the final value of the data, this does not resolve the differences in write order. Thus, the Cassandra Source Connector needs to conform to the write ordering guarantees similar to those of Cassandra.
Obtaining Complete Row Content
There’s no requirement for Cassandra writes to contain all table columns. Even if this were the case, the current state of the row would depend on both the data in the write and all previously written data that shadows it. Thus, the write data alone is not sufficient to determine the new row state.
Obtaining Previous Row Content
As is the case when determining new row value, knowledge of the row state prior to a given mutation is required. This prior row state represents the accumulation of all previous writes.
Distributed Data Ownership
The ownership of data in Cassandra is distributed between the nodes in each datacenter. There’s no special “master”; all nodes are able to coordinate writes. Thus, processing these writes to a cluster involves combining information from multiple nodes.
Possible Approaches
Several approaches were considered when designing the Cassandra Source Connector. This post by WePay gives a solid description of the primary streaming options available along with the pros and cons of each, including:
- Writing to both Cassandra and Kafka (“Double Writing”)
- Writing directly to Kafka and using a Cassandra Sink to load the data in Cassandra (“Kafka as Event Source”)
- Processing the commit log exposed by Cassandra’s Change Data Capture or CDC (“Parsing Commit Logs”)
The use of Kafka Connect’s Cassandra Source was also investigated. This connector streams data from a Cassandra table into Kafka using either “bulk” or “incremental” update modes. Both modes function by periodically polling the table for data. Bulk mode performs a full table scan, publishing the entire result, while incremental mode queries the rows written since the last sampling. Both modes have their disadvantages:
- Bulk mode table scans are very expensive on large tables, and each scan publishes a lot of duplicate data.
- Incremental mode is only viable for a certain type of workload. The writes must be append-only with monotonically increasing columns (such as timestamps) as part of the primary key. Additionally, polling for this data can cause extra cluster load.
Ultimately, a solution based on processing Cassandra CDC made the most sense for the connector.
Cassandra’s distributed deployment characteristics coupled with both the need to achieve an ordering of writes and meet Data Pipeline semantics made creating a single application quite challenging. Thus, the Cassandra Source Connector was built as two separate components, each addressing a subset of these issues:

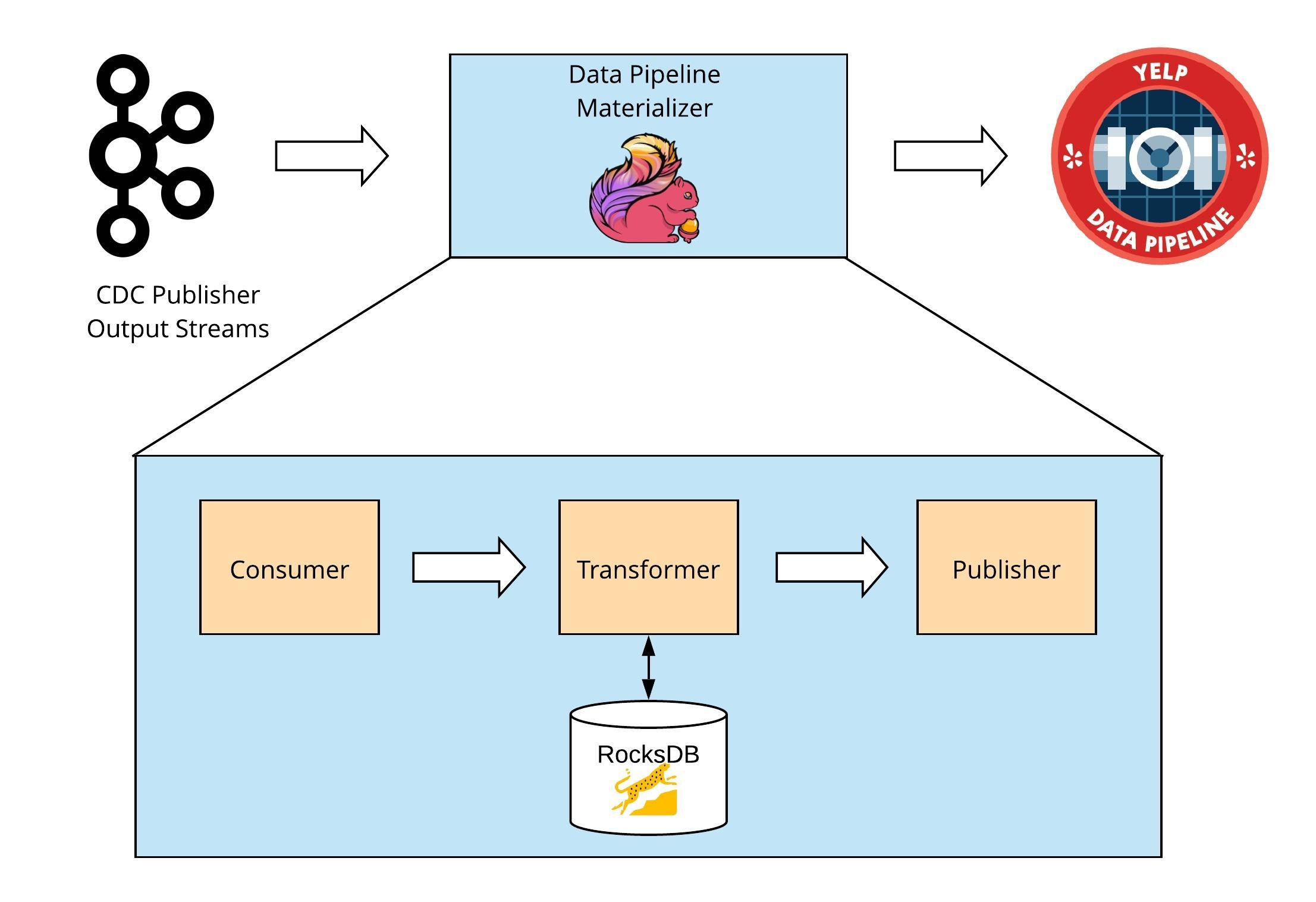
Cassandra Source Connector at a High Level
CDC Publisher: A service running locally on Cassandra nodes that uses CDC to publish raw Cassandra writes into intermediate Kafka streams. These streams serve as unified commit logs, removing the aspect of distributed data ownership and defining an order of events to process.
Data Pipeline Materializer (DP Materializer): An application running on Apache Flink which processes raw Cassandra writes produced by the CDC Publisher and publishes them as Data Pipeline messages.
CDC Publisher
The CDC Publisher produces all writes made in Cassandra tables as serialized partition updates into table-specific Kafka streams.
Processing Cassandra Writes with CDC
The Change Data Capture (CDC) capability introduced in version 3.8 of Cassandra is used by the CDC Publisher to process writes.
Normally (with CDC disabled), writes are stored by Cassandra in the following manner:
- Client writes are persisted to memtables and the commit log by every node
- Memtables are periodically flushed to SSTables on disk
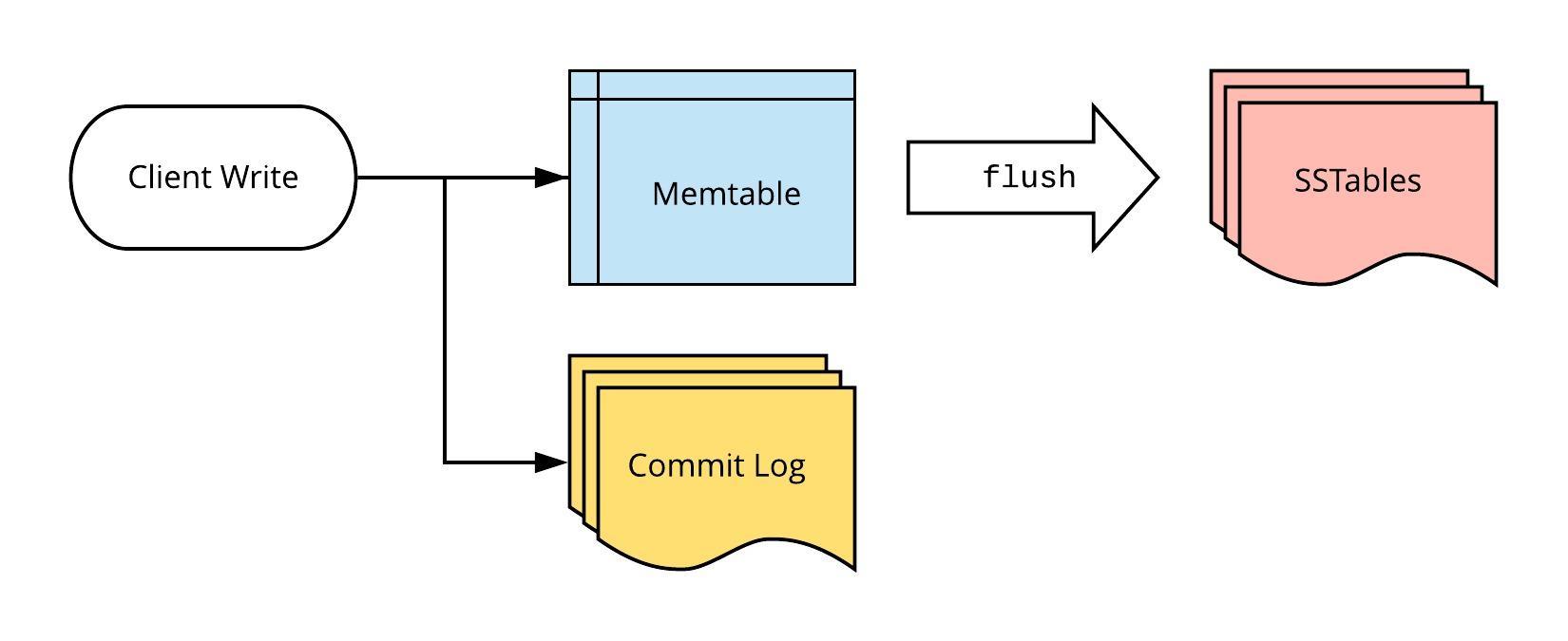
Cassandra Write Path
The commit log is composed of a series of fixed-sized files (defaulted at 32MB) called “commit log segments”. Once the memtables are flushed to SSTables, these segments are discarded by Cassandra.
If CDC is enabled, all Cassandra commit log segment files containing writes to a tracked table are flagged. When the files are no longer referenced by corresponding memtables, they’re moved into a separate directory (instead of being discarded).
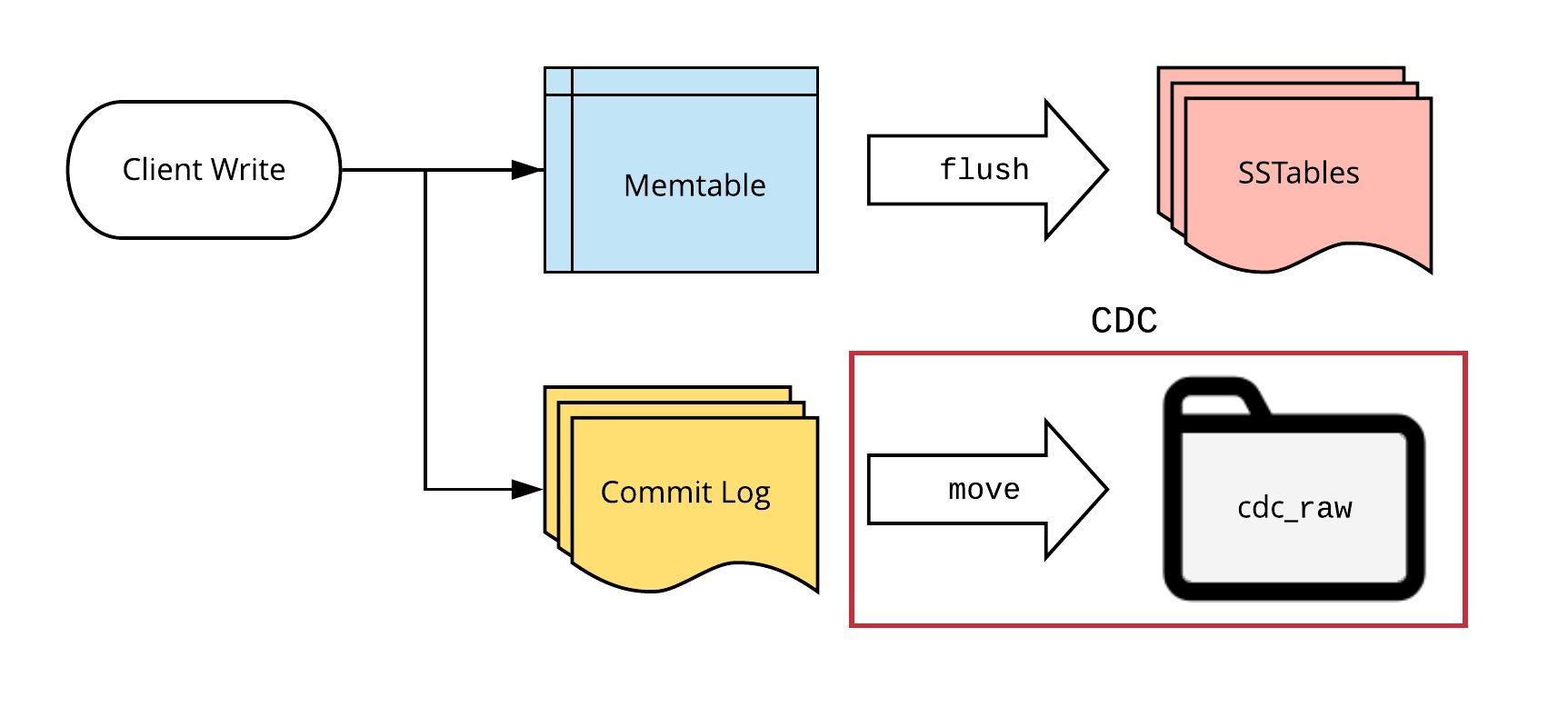
Cassandra Write Path with CDC
There are several challenges with using the current implementation of Cassandra’s CDC:
- Per-node processing: As each node stores only a portion of the complete table data, CDC must be processed on multiple nodes.
- Replication: The same write is stored on each data replica, resulting in duplicate processing.
- Partial data: Commit log segments only contain the information from incoming writes and do not have the full view of the corresponding rows.
- CDC does not contain schema information about the tables.
- CDC directory size limit: If the CDC directory gets too large in size, the node will reject new table writes.
- Poorly bounded latency: Commit log segments must be full and no longer referenced by memtables before being made available for processing. For clusters with low write rates, the commit log segments can take a while to fill up, affecting latency.
Despite these drawbacks, CDC was used because it is the solution developed by the Cassandra open source community for processing committed data. This also means that any future improvements to the CDC implementation can be leveraged by upgrading Cassandra versions.
Wrangling CDC
Deployment
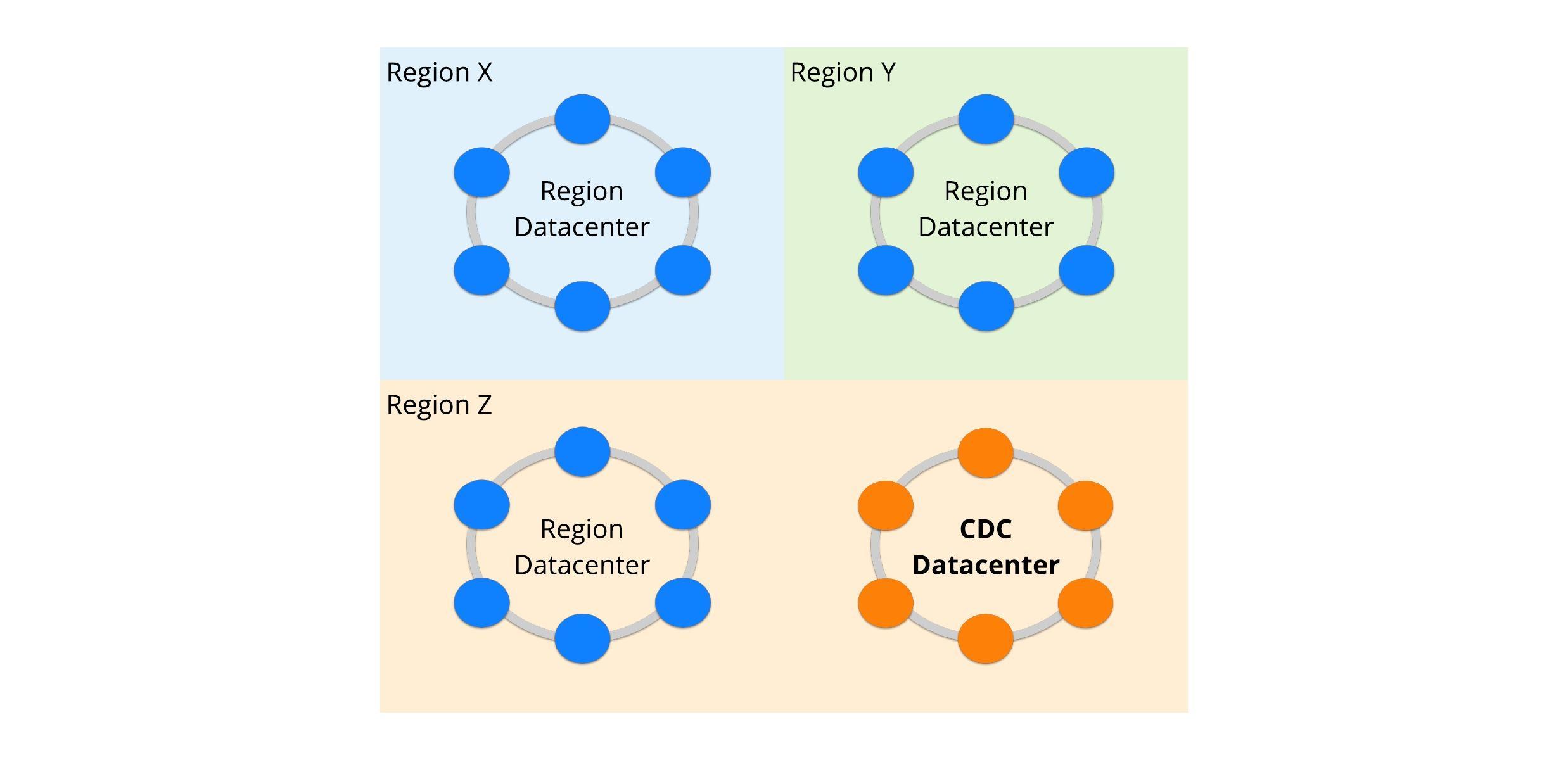
CDC Datacenter Deployment
To ensure that processing CDC doesn’t cause any performance issues on the actual cluster, a virtual Cassandra datacenter is created, which is logically separate from the standard region-specific datacenters. The CDC Publisher is deployed only on the nodes of this datacenter. As all writes go to data replicas in all datacenters, this is sufficient to ensure coverage of all table changes. Additionally, nodes in this datacenter can be provisioned differently as they don’t serve live client read requests.
Bounding Latency
As mentioned earlier, one of the issues with using CDC is that the latency (defined as the time between the write to Cassandra and the data being made available for processing) is poorly bounded. CDC only allows processing of commit log files that are no longer needed, meaning they should be full and not referenced by an existing memtable. To introduce predictable latency bounds to the connector, the following approaches were adopted:
Removing Memtable References
Memtables are periodically flushed by Cassandra to SSTables when they get too large. However, a table with a low write rate will rarely be flushed, thus delaying CDC processing for the whole cluster. To ensure this does not happen, an explicit flush of all memtables is triggered at periodic intervals (typically 5-10 minutes) for nodes in the CDC datacenter. This ensures that a full commit log segment will only wait, at most, one flush interval before it can be processed. As only the CDC datacenter nodes are flushed, there’s no impact to client read performance in the other datacenters.
Filling Segments
Commit log segment sizes are fixed. If the tracked table has a slow write rate, it may be a while before a segment completely fills up. This fill-up time is bound by creating a process separate from the CDC Publisher which writes to a “filler” table at a predictable rate. This table is replicated only in the CDC datacenter and is fully replicated to all nodes. To limit any performance impact, fewer large writes (~100K) are performed, only a single key is written to, and the data is aggressively TTL’ed.
Processing CDC
To aid with the processing of CDC commit log segments, the Cassandra library provides a handler interface for applications to implement. This interface allows processing of a stream of all mutations (writes) present in a commit log segment. The Mutation class is the Java object Cassandra uses to represent data, namely:
- A Mutation contains PartitionUpdate objects for multiple tables
- A PartitionUpdate contains Row objects for a single partition key value
- A Row contains data for a single clustering key value
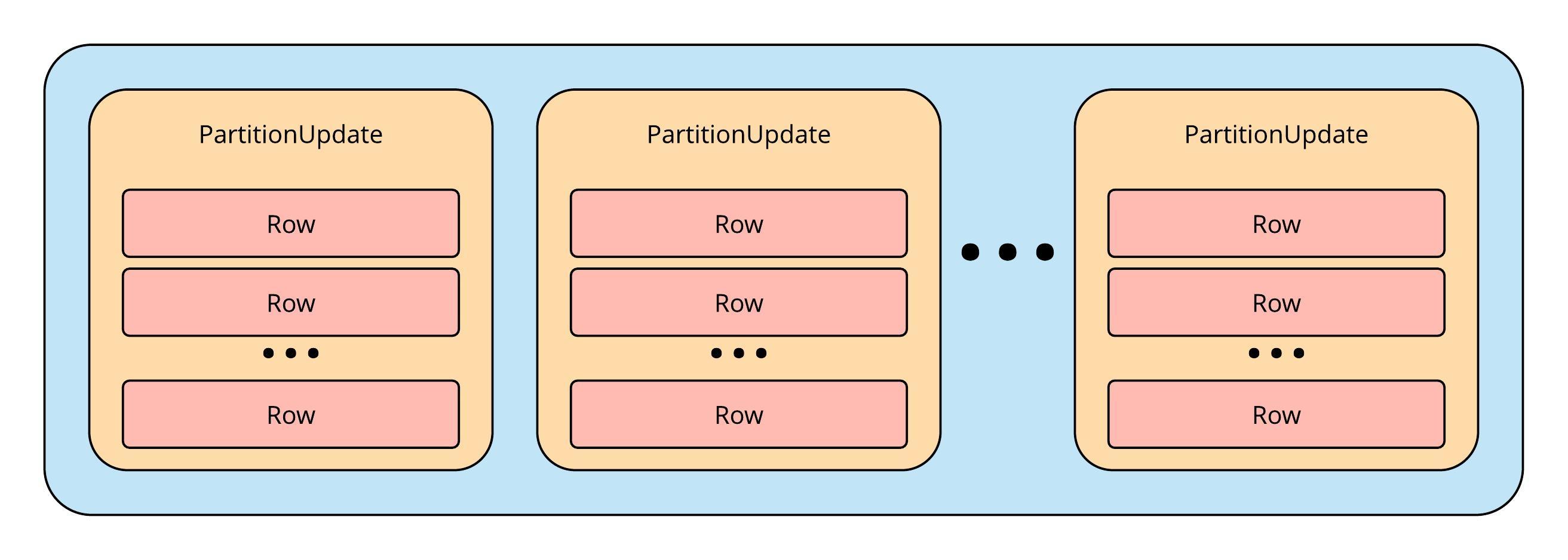
Structure of a Cassandra Mutation
The primary function of the CDC Publisher is to break these mutations up into individual PartitionUpdate objects. If a PartitionUpdate contains multiple rows, these are further broken down into a series of updates with single rows. Thus, each update contains data only for a single Cassandra primary key.
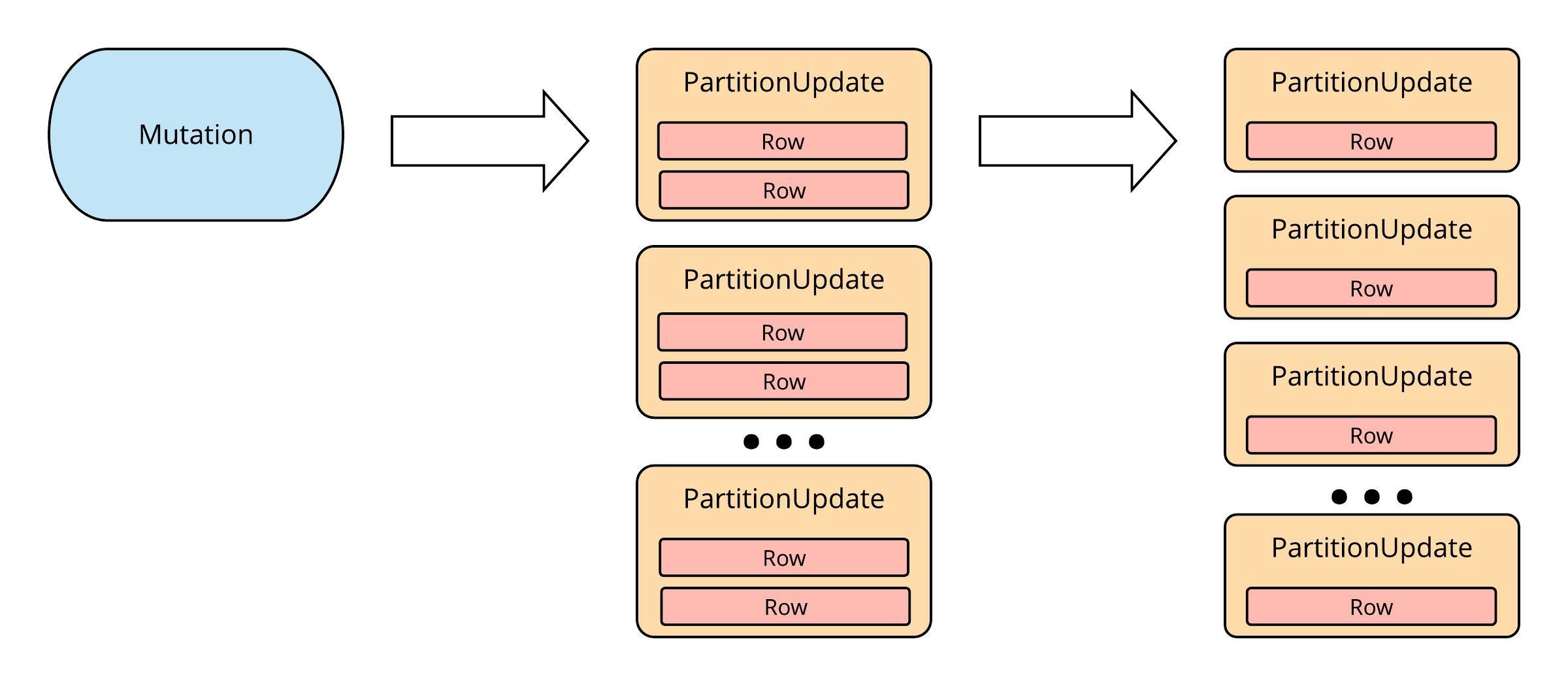
Breakdown of a Mutation into Individual Row Objects
Each of the resulting PartitionUpdate objects is serialized for publishing to Kafka streams. Serializers provided by the Cassandra library are used for serialization before publishing.
Publishing to Kafka
The PartitionUpdate payloads are used to build messages to publish to the intermediate Kafka stream. Each message includes:
- The serialized PartitionUpdate
- The Cassandra messaging version used for serialization
- Metadata for auditing (host, file, position, etc.)
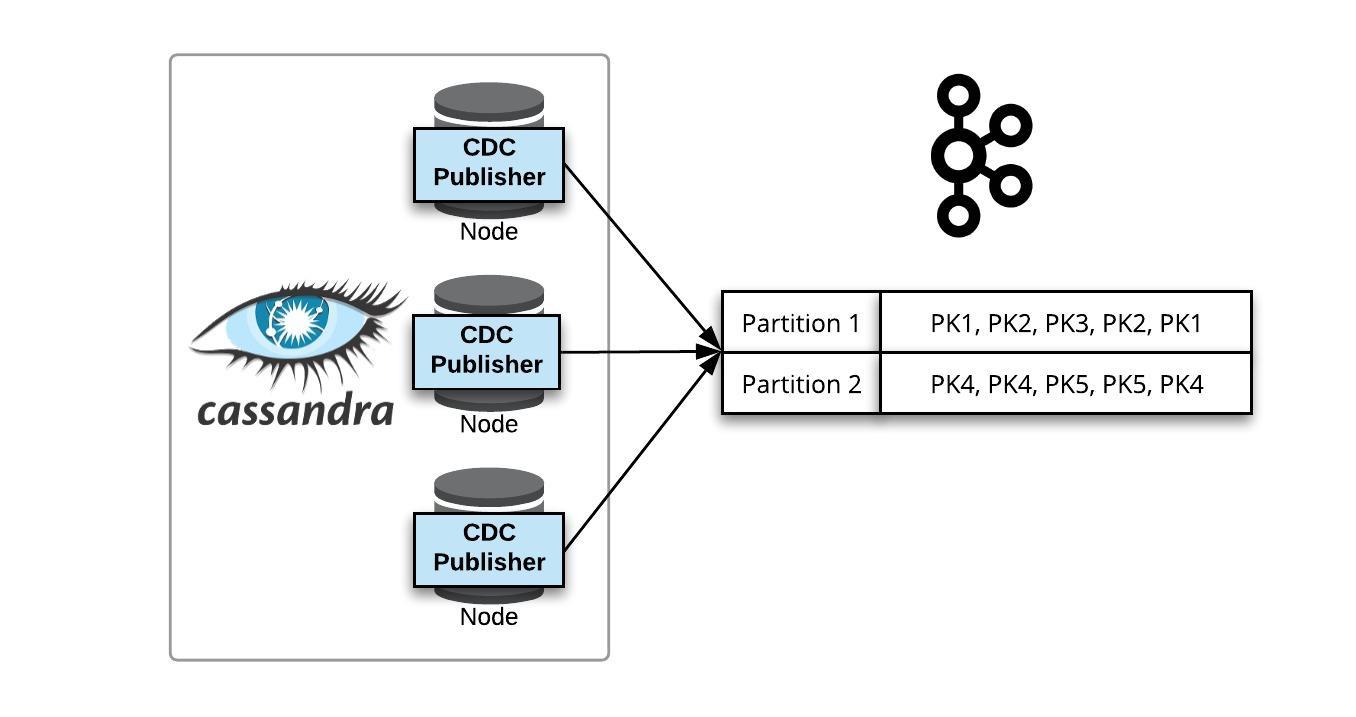
The messages are then published to table specific Kafka streams. A stream can have multiple partitions for scalable publishing; in which case, messages are routed to Kafka partitions based on the Cassandra partition key. Thus, all writes for a single partition key will end up in the same topic-partition.
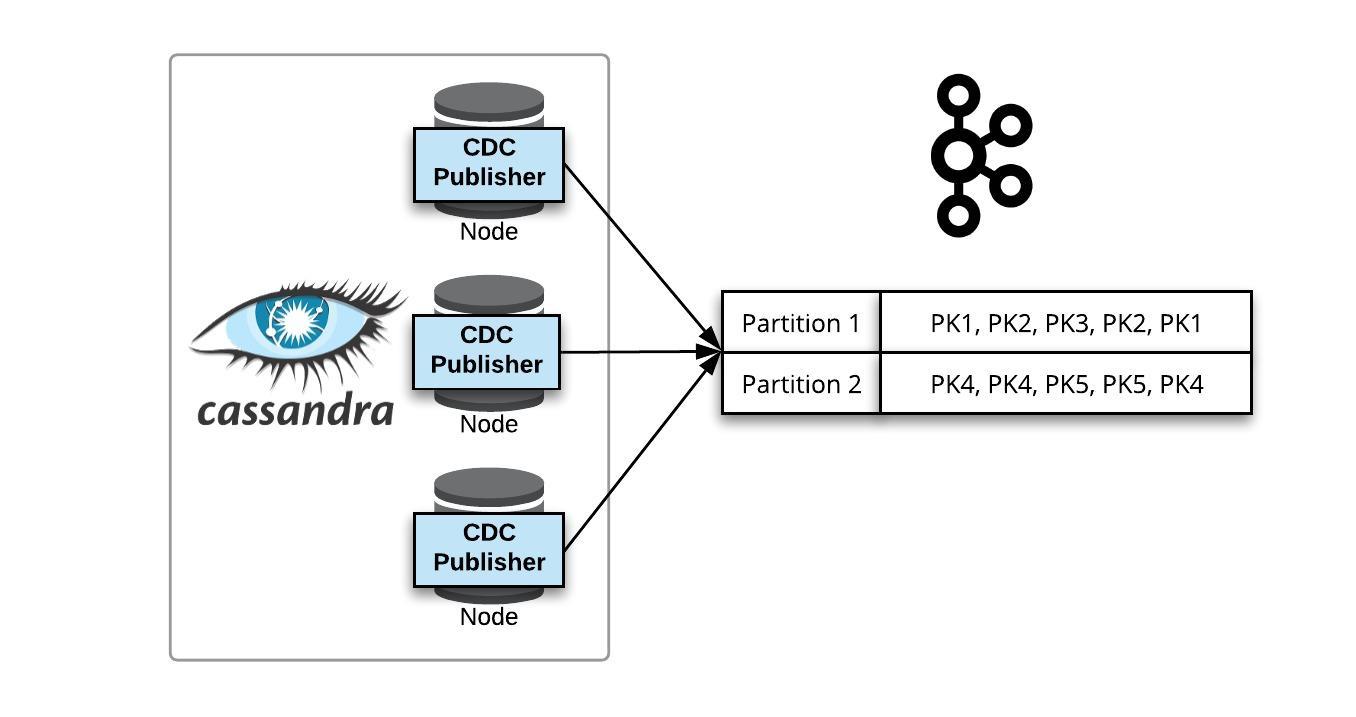
Publishing CDC to a Multi-Partition Kafka Topic
Intermediate Kafka Streams
The resulting Kafka streams contain all writes to the tracked Cassandra tables. As all updates to a primary key reside in the same topic partition, this sets an ordering of writes for each key.
While there’s no guarantee events will be in writetime order, there’s also no guarantee that writes will commit to a Cassandra replica in writetime order. Additionally, there will be a duplicate write copy for each data replica. Even though this is the case, the intermediate streams act as unified commit logs for the tables. They provide an order of events per key that can be deterministically processed into the ordered stream of row updates needed for publishing to the Data Pipeline.
Stream Consistency
Given that the connector uses the Cassandra write path, the consistency of the resulting Kafka stream will not be more consistent than the underlying datastore. As writes are published from each replica in their local commit order, the processed stream should initially be no less consistent than reading from a single replica. As data from additional replicas is processed, the stream becomes eventually consistent. When all replicas have published updates, the consistency will be equivalent to a read covering all CDC datacenter nodes.
The time-boundness of this eventual consistency is determined by the write consistency level used by the Cassandra clients. If the update has to immediately show up in the stream, a high consistency level (e.g., EACH_QUORUM) must be used to ensure commits to nodes in the CDC datacenter. If a lower/local consistency is used for writes, the PartitionUpdate may not appear in the output stream (in the worst case) until the next table repair. Note that this is in line with the guarantees given to clients reading Cassandra directly.
What’s Next?
At this point, the intermediate Kafka streams contain Cassandra PartitionUpdate objects partitioned by keys and in a loosely ordered manner. These objects must now be deserialized, converted into ordered Data Pipeline messages, and published into the pipeline. This is done through the DP Materializer.
The DP Materializer is covered in the second half of this two-part post.
Read the posts in the series: