Successfully reported this slideshow.
Spark, File Transfer, and More: Strategies for Migrating Data to and from a Cassandra or Scylla Cluster

Upcoming SlideShare
Loading in …5
×
No Downloads
No notes for slide
- 1. Spark, File Transfer, and More Strategies for Migrating Data to and from a Cassandra or Scylla Cluster WEBINAR
- 2. Presenter 2 Dan Yasny Before ScyllaDB, Dan worked in various roles such as sysadmin, quality engineering, product management, tech support, integration and DevOps around mainly open source technology, at companies such as Red Hat and Dell.
- 3. 3 + The Real-Time Big Data Database + Drop-in replacement for Cassandra + 10X the performance & low tail latency + New: Scylla Cloud, DBaaS + Open source and enterprise editions + Founded by the creators of KVM hypervisor + HQs: Palo Alto, CA; Herzelia, Israel About ScyllaDB
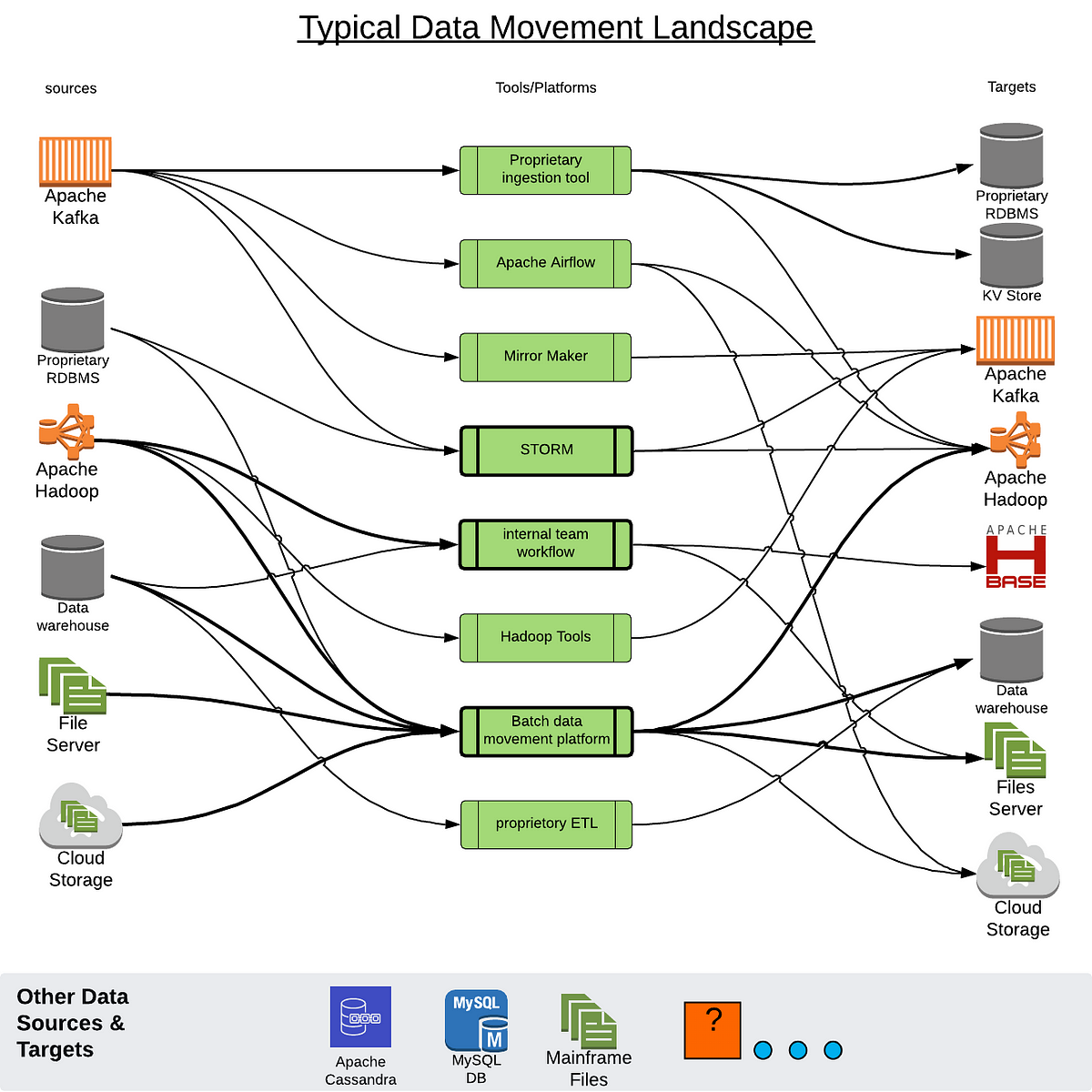
- 4. Migration overview + Online and Offline migrations + Common steps: Schema, Existing data Online migrations + Dual Writes + Kafka + Custom application changes Existing data migration + Highly volatile/TTL’d data + CQL COPY + SSTableloader + Mirror loader (Danloader) + Spark Migrator Agenda
- 5. Migration Overview + Online migration + Added complexity + Added load + Offline migration + Downtime + Common steps + Schema migration and adjustments + Existing data migration + Data validation SSTable Loader SSTables CQL CQL CQL Client CQLCQL Client
- 6. Migrate Schema + Use DESCRIBE to export each Cassandra Keyspace, Table, UDT + cqlsh [IP] "-e DESC SCHEMA" > orig_schema.cql + cqlsh [IP] --file 'adjusted_schema.cql' + Schema updates when migrating from Cassandra 3.x + Different syntax for some schema properties might be needed https://docs.scylladb.com/operating-scylla/procedures/cassandra_to_scylla_migration_process/#notes-limitations-and-kn own-issues
- 7. Online Migration
- 8. Write to DB-OLD Cold Migration - No Dual Writes Time Read from DB-OLD
- 9. Write to DB-OLD Migrate Schema Cold Migration - No Dual Writes Time Read from DB-OLD
- 10. Write to DB-OLD Forklifting Existing Data Migrate Schema DBs in Sync Cold Migration - No Dual Writes Time Read from DB-OLD
- 11. Write to DB-OLD Forklifting Existing Data Validation* Migrate Schema DBs in Sync Cold Migration - No Dual Writes Time Fade off DB-OLD Read from DB-OLD
- 12. Write to DB-OLD Forklifting Existing Data Validation* Migrate Schema DBs in Sync Cold Migration - No Dual Writes Time Read from DB-NEW Fade off DB-OLD Read from DB-OLD Write to DB-NEW
- 13. Write to DB-OLD Dual Writes Time Read from DB-OLD
- 14. Write to DB-OLD Migrate Schema Dual Writes Time Read from DB-OLD
- 15. Write to DB-OLD Dual Writes Migrate Schema Dual Writes Time Read from DB-OLD
- 16. Write to DB-OLD Dual Writes Migrate Schema Dual Writes Time Read from DB-OLD Write to DB-NEW
- 17. Write to DB-OLD Dual Writes Forklifting Existing Data Migrate Schema Dual Writes Time Read from DB-OLD Write to DB-NEW
- 18. Write to DB-OLD Dual Writes Forklifting Existing Data Migrate Schema DBs in Sync Dual Writes Time Read from DB-OLD Write to DB-NEW
- 19. Dual Reads Write to DB-OLD Dual Writes Forklifting Existing Data Validation Migrate Schema DBs in Sync Dual Writes Time Read from DB-OLD Write to DB-NEW
- 20. Dual Reads Write to DB-OLD Dual Writes Forklifting Existing Data Validation Migrate Schema DBs in Sync Dual Writes Time Read from DB-NEW Read from DB-OLD Write to DB-NEW
- 21. Dual Reads Write to DB-OLD Dual Writes Forklifting Existing Data Validation Migrate Schema DBs in Sync Dual Writes Time Read from DB-NEW Fade off DB-OLD Read from DB-OLD Write to DB-NEW
- 22. Apache Kafka based dual writes Already using Kafka + Start buffering the writes to new cluster + Increase the TTL and add buffer time while migration is in progress/about to start + Keep sending writes to old cluster + Once existing data migration is complete, stream the data to new cluster + Use the Kafka-connect framework with the Cassandra connector + Use KSQL if you want to run a couple of transformations on the data (EXPERIMENTAL)
- 23. Dual Writes: App changes code sample writes = [] writes.append(db1.execute_async(insert_statement_prepared[0], values)) writes.append(db2.execute_async(insert_statement_prepared[1], values)) results = [] for i in range(0,len(writes)): try: row = writes[i].result() results.append(1) except Exception: results.append(0) # Handle it if (results[0]==0): log('Write to cluster 1 failed') if (results[1]==0): log('Write to cluster 2 failed')
- 24. Existing Data Migration
- 25. Existing data migration strategies + CQL COPY + SSTableloader + Mirror loader + Spark Migrator When performing an online migration, always use a strategy that preserves timestamps, unless all keys are unique
- 26. Databases: Under the hood + Native CQL to native CQL + Scylla Spark Migrator + SSTable files to CQL + SSTableloader + SSTable files to SStable files + Mirror loader + Arbitrary data files to CQL + COPY
- 27. Highly volatile data with low TTL + Establish dual writes + Keep running until last record in the old DB is expired + Turn off dual writes + Phase out old DB SQL NoSQL
- 28. CQL COPY
- 29. CQL COPY: Database Compatibility + Scylla and Cassandra: Common file format + Schema Migration vs Schema Redesign SQL NoSQL
- 30. COPY continued Some knobs: + HEADER + CHUNKSIZE + DATETIMEFORMAT + DELIMITER + INGESTRATE + MAXBATCHSIZE + MAXROWS + NULL + PREPAREDSTATEMENTS + TTL + File size matters + Skipping unwanted columns + Formatting + NULL + DATETIME + Quotes + Escapes + Delimiters + Best practices + Small files + Separate host
- 31. COPY and CSV files Pros + Simplicity + CSV transparency + Easy to validate + Destination schema can have less columns than the original + Can be tweaked, plenty of language support + Can be used for any data ingestion, not necessarily from Scylla/Cassandra (incompatible DBs) + Compatible with Cassandra, Scylla and Scylla Cloud Cons + Not for large data sizes + Timestamps not preserved - be careful with online migrations
- 32. SSTableloader
- 33. + Create snapshot of each Cassandra node + Run sstableloader from each Cassandra node, or from intermediate servers + Use throttling -t to limit the leader throughput if needed + Run several sstableloaders in parallel Both Cassandra and Scylla ship with an sstableloader utility. While they are similar, there are differences between the two: + Use Scylla’s sstableloader to migrate to Scylla SSTableloader Scylla’s SSTable Loader SSTables CQL SQL NoSQL
- 34. SStableloader continued + No Schema update during forklifting + Scylla’s sstableloader has support for simple column renames + Assuming RF=3, you end up with 9 copies of the data until compaction happens Failure handling: + What should I do if sstableloader fails? + What should I do if a source node fails? + What should I do if a destination node fails? + How to rollback and start from scratch? https://docs.scylladb.com/operating-scylla/procedures/cassandra_to_scylla_migration_process
- 35. Mirror Loader
- 36. Mirror Loader Preparation: + Temporarily mirror the original DB + Establish node pairs + Clone the token sets between node pairs + nodetool ring + Every node has token assignment, which has to match the data on disk + We want to bring up a similar Scylla setup, using the same token ranges + Then let Scylla’s internals do the work Source DB Temp DB File copy SQL NoSQL
- 37. Mirror Loader + Start the mirrored Scylla cluster + Bring up destination Scylla nodes in a new DC in the same cluster, using the temp cluster as seed + Start synchronization (repair or rebuild) + Wait for synchronization to complete + Phase out the Old and Temporary clusters Native sync Source cluster Destination Cluster temporary DC1 Destination cluster DC2
- 38. Mirror Loader Pros + Very simple approach + Direct file copy, no data digesting + Very low effect on source DB load + Native sync to destination DB + Very fast - files are copied and the temporary DB is ready to be used immediately. Cons + Supported file formats + ka, la, mc + Temporary machines required + Not usable with Scylla cloud + Schema adjustments might be needed
- 39. Scylla Spark Migrator
- 40. Scylla Spark migrator + Highly resilient to failures, and will retry reads and writes throughout the job + Continuously writes savepoint files which can be used to resume the transfer from the point at which it stopped + Access compatible Databases using a native connector + High performance parallelized reads and writes + Unlimited streaming power + Reduce data transfer costs + Can be configured to preserve the WRITETIME and TTL attributes of the fields that are copied + Can handle column renames as part of the transfer SQL NoSQL
- 41. Scylla Spark Migrator A very simple and easy to use tool + Install the standard Spark stack (Java JRE and JDK, SBT) + Edit configuration file + Run Links: + https://www.scylladb.com/2019/02/07/moving-from-cassandra-to-scylla-via-apache-spark-scylla- migrator/ + https://github.com/scylladb/scylla-migrator/
- 42. Scylla Spark Migrator - configuration source: host: 10.0.0.110 port: 9042 credentials: username: <user> password: <pass> keyspace: keyspace1 table: standard1 splitCount: 256 connections: 4 fetchSize: 1000 target: ... preserveTimestamps: true savepoints: path: /tmp/savepoints intervalSeconds: 60 renames: [] skipTokenRanges: []
- 43. STDOUT: 2019-03-25 20:30:04 INFO migrator:405 - Created a savepoint config at /tmp/savepoints/savepoint_1553545804.yaml due to schedule. Ranges added: Set((49660176753484882,50517483720003777), (1176795029308651734,1264410883115973030), (-246387809075769230,-238284145977950153), (-735372055852897323,-726956712682417148), (6875465462741850487,6973045836764204908), (-467003452415310709,-4589291437737669003) ... Scylla Spark migrator
- 44. Takeaways: Online Migration This webinar covered ways to do online migration (no downtime) to and from Apache Cassandra, Scylla, and Scylla Cloud. This requires the writes to be sent to both clusters + Have an existing Kafka infrastructure: replay kafka streams + For all other scenarios: small changes to the application to do dual writes
- 45. Takeaways: Existing Data Migration + If Source database is SQL, MongoDB, etc: + Use COPY command + If you have control of the topology and can afford temporary extra nodes: + Use Mirror Loader + If you have access to the original SSTable files: + Use SSTableloader + Want a fully flexible streaming solution and can afford the extra load in the source: + Use the Scylla Spark Loader
- 46. United States 1900 Embarcadero Road Palo Alto, CA 94303 Israel 11 Galgalei Haplada Herzelia, Israel www.scylladb.com @scylladb Thank you
- 47. Q&A Stay in touch dyasny@scylladb.com @dyasny
Public clipboards featuring this slide
No public clipboards found for this slide