my Patch mentioned in this post (RFE-7068625) for JVM garbage collector was accepted into HotSpot JDK code base and available starting from 7u40 version of HotSport JVM from Oracle.
This was a reason for me to redo some of my GC benchmarking experiments. I have already mentioned ParGCCardsPerStrideChunk in article related to patch. This time, I decided study effect of this option more closely.
Parallel copy collector (ParNew), responsible for young collection in CMS, use ParGCCardsPerStrideChunk value to control granularity of tasks distributed between worker threads. Old space is broken into strides of equal size and each worker responsible for processing (find dirty pages, find old to young references, copy young objects etc) a subset of strides. Time to process each stride may vary greatly, so workers may steal work from each other. For that reason number of strides should be greater than number of workers.
By default ParGCCardsPerStrideChunk =256 (card is 512 bytes, so it would be 128KiB of heap space per stride) which means that 28GiB heap would be broken into 224 thousands of strides. Provided that number of parallel GC threads is usually 4 orders of magnitude less, this is probably too many.
Synthetic benchmark
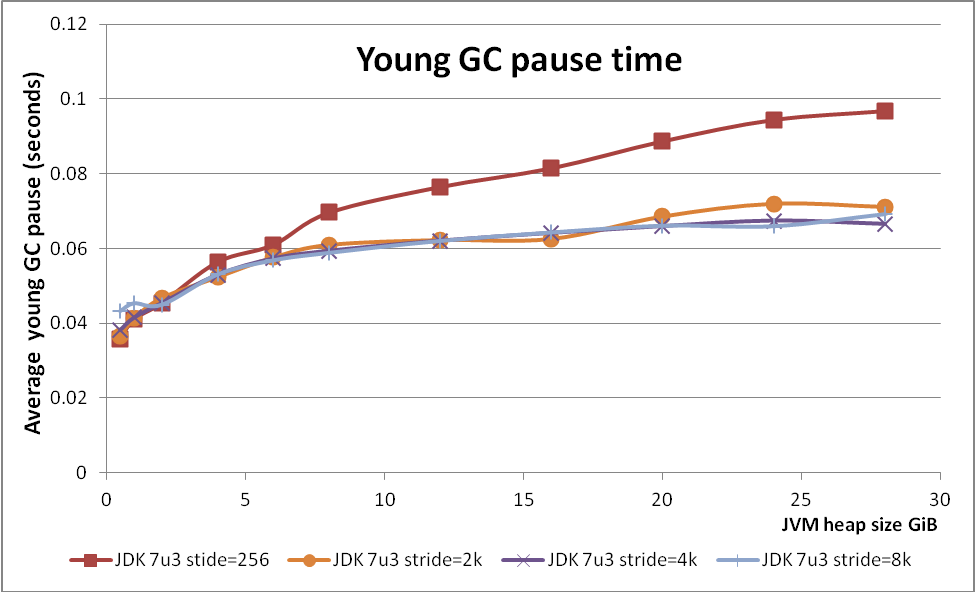
First, I have run GC benchmark from previous
article using 2k, 4k and 8K for this option. HotSpot JVM 7u3 was used in
experiment.

It seems that default value (256 cards per strides) is too
small even for moderate size heaps. I decided to continue my experiments with
stride size 4k as it shows most consistent improvement across whole range of
heap sizes.
Benchmark above is synthetic and very simple. Next step is to choose more realistic use case. I usual, my choice is to use Oracle Coherence storage node as my guinea pig.
Benchmarking Coherence storage node
In this experiment I’m filling cache node with objects (object
70% of old space filled with live objects), then put it under mixed read/write
load and measuring young GC pauses of JVM. Experiment was conducted with two
different heap sizes (28 GiB and 14 GiB), young space for both cases was
limited by 128MiB, compressed pointers were enabled.
Coherence node with 28GiB of heap
JVM
|
Avg. pause
|
Improvement
|
7u3
|
0.0697
|
0
|
7u3, stride=4k
|
0.045
|
35.4%
|
0.0546
|
21.7%
|
|
Patched OpenJDK 7,
stride=4k
|
0.0284
|
59.3%
|
Coherence node with 14GiB of heap
JVM
|
Avg. pause
|
Improvement
|
7u3
|
0.05
|
0
|
7u3, stride=4k
|
0.0322
|
35.6%
|
This test is close enough to real live Coherence work
profile and such improvement of GC pause time has practical importance. I have
also included JVM built from OpenJDK trunk with enabled RFE-7068625
patch for 28 GiB test, as expected effect of patch is cumulative with
stride size tuning.
Stock JVMs from Oracle are supported
Good news is that you do not have to wait for next version of JVM, ParGCCardsPerStrideChunk option is available in all Java 7 HotSpot JVMs and most recent Java 6 JVMs. But this option is classified as diagnostic so you should enable diagnostic options to use it.
-XX:+UnlockDiagnosticVMOptions
-XX:ParGCCardsPerStrideChunk=4096