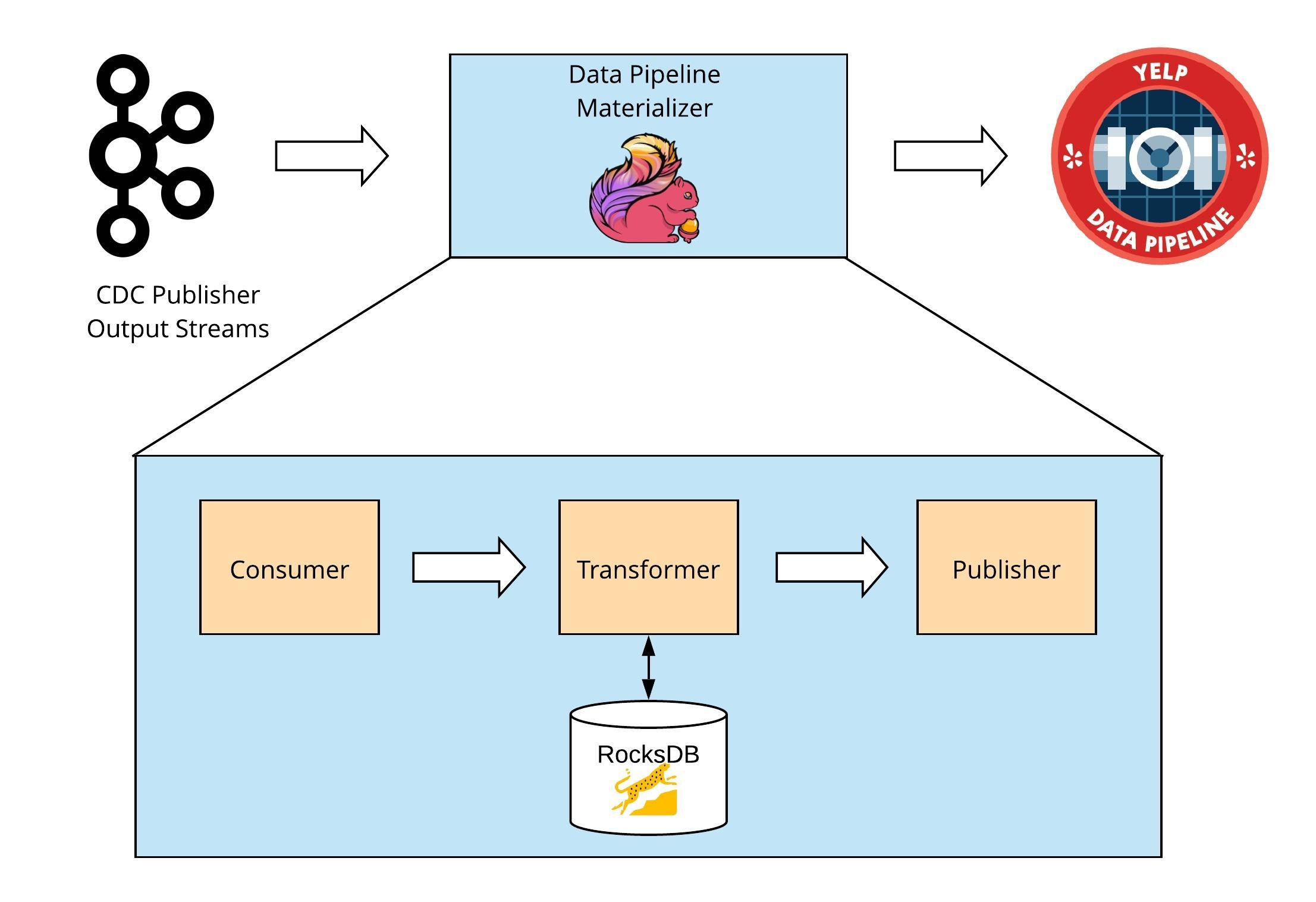
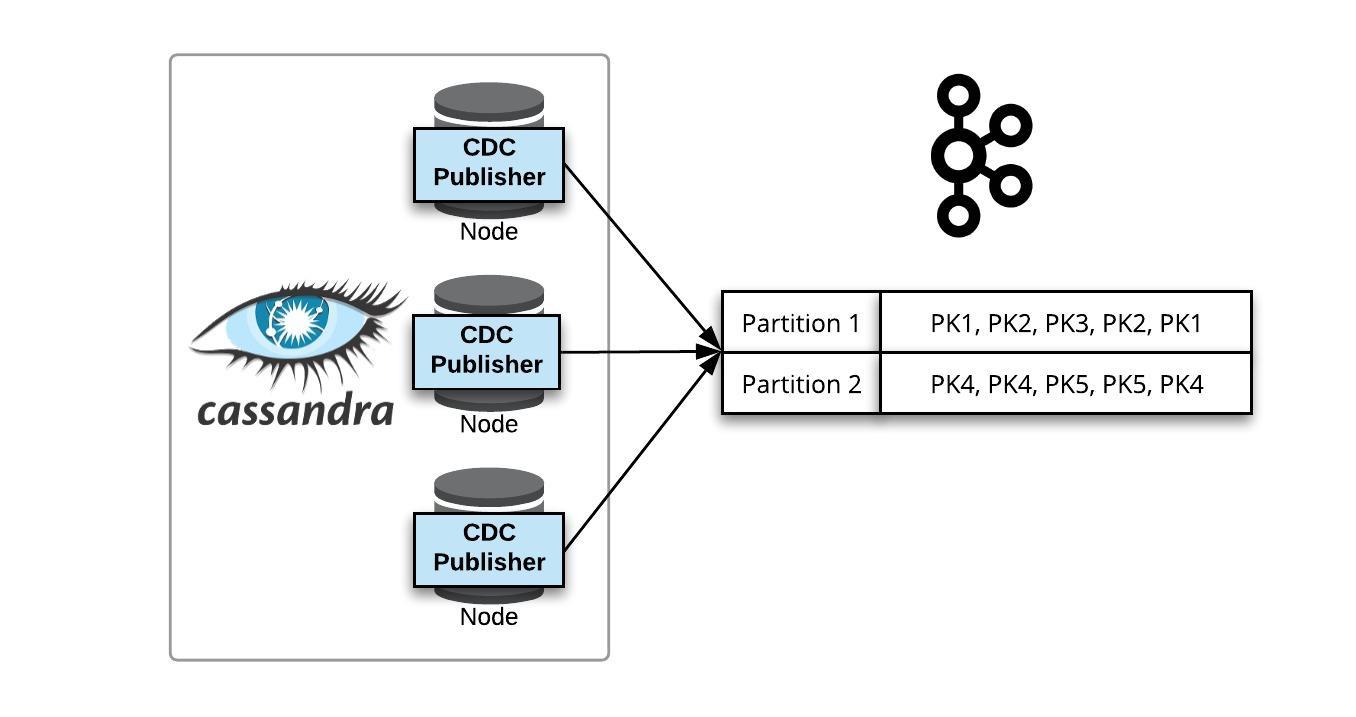
Spark Streaming is a good tool to roll up transactions data into summaries as they enter the system. When paired with an easily idempotent data store like Cassandra you get a high performance low hassle approach to getting your work done.
Useful Background
- Retry Not Rollback: Idempotent Data Models in Cassandra
- Event Sourcing and System Of Record (addresses Message Replay and System Of Record)
- Cassandra CQL Docs on Counters
- WAL: Write Ahead Logging
- Direct API in Spark Streaming
General Best Practice
The safe choice will be an Idempotent Data Model that you can safely retry, Aggregate with Spark Streaming and use Message Replay driven by a System Of Record to handle any lost messages.
Anti-Pattern
Counters with Spark Streaming, this will likely exacerbate over counting which is the nature of incrementing a number in a system where retries are the normal approach to a failed write.
Cheat Sheet: What‘s the correct approach for you?
I care about speed and can allow some temporary but not permanent inaccuracy and using Kafka. Spark Streaming Aggregation and Idempotent Data Model + Direct API with a System of Record that can facilitate message replay. This should be almost the identical speed to the same model without a Direct API.
I care about speed and can allow some temporary but not permanent inaccuracy but not using Kafka. Spark Streaming Aggregation and Idempotent Data Model with a System of Record that can facilitate message replay.
I’m willing to give up speed and can allow some temporary but not permanent inaccuracy but no Kafka. Spark Streaming Aggregation and Idempotent Data Model + WAL with a System of Record that can facilitate message replay. This will work with any message queue or network server, but all records will be written by Spark to a distributed network share first.
I care about speed first and foremost, but only want to count and want maximum data density. May want to investigate Counters without Spark Streaming. There is no way to correct over delivery or replay. Data model will matter. Must be using a recent version of Cassandra (2.1+) to be successful as the counters before that were prone to race conditions.
I care about speed first and foremost, but need more than count and I want maximum data density. Spark Streaming Aggregation is your friend. There is no way to correct for over delivery or message replay. The data model and your expectations will matter a lot how successful this is.
Tradeoffs in Detail
If you do need to dive into the depths of the different approaches, and often use cases will be degrees of comfort as opposed to a true or false.
Counters with No Streaming
session.execute("CREATE TABLE event_counts ( event_id uuid, us_vists counter, uk_visits counter, PRIMARY KEY (event_id))")session.execute("UPDATE event_counts SET uk_visits = uk_visits + 1, us_visits = us_visits + 2 WHERE event_id = 21115d6d-e908-4a82-8f05-335decedfb9b")Fast, inaccurate and simple. You cannot safely retry counters without overcounting, and there is no way to know that you overcounted later. This is hopeful accuracy at best. Typical first attempt at ‘aggregates’ in Cassandra.
Counters + Streaming + WAL
val conf = new SparkConf()
.setMaster("127.0.0.1:7077")
.setAppName("Counters")
.set("spark.streaming.receiver.writeAheadLog.enable", "true")
val ssc = new StreamingContext(conf, Seconds(1))
ssc.checkpoint(checkpointDirectory)
//group by first column which is Country in this case
val events = ssc.socketTextStream("localhost", 9999)
.groupBy(e=>e(0))
.countByKey()
.foreachRDD(rdd=>rdd.foreach(i=>{
connector.withSessionDo(session=>{
val prepared = session.prepare("UPDATE events_counts SET visits = visits += ? WHERE country = ?")
session.execute(prepared.bind(i._2, i._1))
})
}))
Slow, inaccurate and lots of moving parts. Requires shared storage. You cannot safely retry counters without overcounting, and there is no way to know that you overcounted later. This is hopeful accuracy at best. This just adds the extra complexity of a WAL and when combined with Spark Streaming may easily overcount.
Counters + Streaming + Direct API
//group by first column which is Country in this case
val events = KafkaUtils.createDirectStream[String, String, StringDecoder, StringDecoder]( ssc, kafkaParams, topicsSet)
.groupBy(e=>e._2.split(",")))
.countByKey()
.foreachRDD(rdd=>rdd.foreach(i=>{
connector.withSessionDo(session=>{
val prepared = session.prepare("UPDATE events_counts SET visits = visits += ? WHERE country = ?")
session.execute(prepared.bind(i._2, i._1))
})
}))
Must use Kafka. Slow, inaccurate and lots of moving parts. You cannot safely retry counters without overcounting, and there is no way to know that you overcounted later. This is hopeful accuracy at best. This just adds the extra complexity of a WAL and when combined with Spark Streaming may easily overcount.
Spark Streaming Aggregates
//group by first column which is sensorId in this case
val events = ssc.socketTextStream("localhost", 9999)
.groupBy(e=>e(0))
.countByKey()
.foreachRDD(rdd=>rdd.foreach(i=>{
connector.withSessionDo(session=>{
val prepared = session.prepare("UPDATE sensor_counts SET measurements = ? WHERE sensorId = ? and ts = ?")
session.execute(prepared.bind(i._2, i._1, new Date()))
})
}))
Fast, and inaccurate. It is at least retry safe inside of the process, but cannot handle message loss safely.
Spark Streaming Aggregates + WAL
val conf = new SparkConf()
.setMaster("127.0.0.1:7077")
.setAppName("sensors")
.set("spark.streaming.receiver.writeAheadLog.enable", "true")
val ssc = new StreamingContext(conf, Seconds(1))
ssc.checkpoint(checkpointDirectory)
//group by first column which is sensorId in this case
val events = ssc.socketTextStream("localhost", 9999)
.groupBy(e=>e(0))
.countByKey()
.foreachRDD(rdd=>rdd.foreach(i=>{
connector.withSessionDo(session=>{
val prepared = session.prepare("UPDATE sensor_counts SET measurements = ? WHERE sensorId = ? and ts = ?")
session.execute(prepared.bind(i._2, i._1, new Date()))
})
}))
Relatively slow, but more accurate. Any message queue but requires shared storage. Will not lose messages once it’s inside Spark, but it cannot handle message losses at the message queue safely.
Aggregates + Direct API
//group by first column which is sensorId in this case
val events = KafkaUtils.createDirectStream[String, String, StringDecoder, StringDecoder]( ssc, kafkaParams, topicsSet)
.groupBy(e=>e._2.split(",")))
.countByKey()
.foreachRDD(rdd=>rdd.foreach(i=>{
connector.withSessionDo(session=>{
val prepared = session.prepare("UPDATE sensor_counts SET measurements = ? WHERE sensorId = ? and ts = ?")
session.execute(prepared.bind(i._2, i._1, new Date()))
})
}))
Fast and more accurate. Must use Kafka. Will not lose messages once it’s inside Spark, but it cannot handle message losses at the message queue safely.
Aggregates + Idempotent Data Model + System Of Record
//group by first column which is sensorId in this case
val events = ssc.socketTextStream("localhost", 9999).cache()
events.saveToCassandra("keyspace", "sensors_events")events.groupBy(e=>e(0))
.countByKey()
.foreachRDD(rdd=>rdd.foreach(i=>{
connector.withSessionDo(session=>{
val prepared = session.prepare("UPDATE sensor_counts SET measurements = ? WHERE sensorId = ? and ts = ?")
session.execute(prepared.bind(i._2, i._1, i._3))
})
}))
//batch job basically does the same thing and corrects any temporary problems
sc.cassandraTable("keyspace", "sensor_events").groupBy(e=>e(0))
.countByKey()
.foreachRDD(rdd=>rdd.foreach(i=>{
connector.withSessionDo(session=>{
val prepared = session.prepare("UPDATE sensor_counts SET measurements = ? WHERE sensorId = ? and ts = ?")
session.execute(prepared.bind(i._2, i._1, i._3))
})
}))
Speed, temporarily inaccurate but permanently accurate, at the cost of storage. Batch or re-streaming for repair. Can lose messages but it does they can be recovered safely via Message Replay from the System Of Record.
Aggregates + Idempotent Data Model + System Of Record + WAL
val conf = new SparkConf()
.setMaster("127.0.0.1:7077")
.setAppName("sensors")
.set("spark.streaming.receiver.writeAheadLog.enable", "true")
//group by first column which is sensorId in this case
val events = ssc.socketTextStream("localhost", 9999).cache()
val ssc = new StreamingContext(conf, Seconds(1))
ssc.checkpoint(checkpointDirectory)
events.saveToCassandra("keyspace", "sensors_events")events.groupBy(e=>e(0))
.countByKey()
.foreachRDD(rdd=>rdd.foreach(i=>{
connector.withSessionDo(session=>{
val prepared = session.prepare("UPDATE sensor_counts SET measurements = ? WHERE sensorId = ? and ts = ?")
session.execute(prepared.bind(i._2, i._1, i._3))
})
}))
//batch job basically does the same thing and corrects any temporary problems
sc.cassandraTable("keyspace", "sensor_events").groupBy(e=>e(0))
.countByKey()
.foreachRDD(rdd=>rdd.foreach(i=>{
connector.withSessionDo(session=>{
val prepared = session.prepare("UPDATE sensor_counts SET measurements = ? WHERE sensorId = ? and ts = ?")
session.execute(prepared.bind(i._2, i._1, i._3))
})
}))
Slow, pretty accurate and with high cost of storage. Any message queue but requires shared storage. Will not lose messages once it’s inside Spark, but while messages loss is possible at the message queue, they can be recovered safely via Message Replay from the System Of Record.
Aggregates + Idempotent Data Model + System Of Record + Direct API
//group by first column which is sensorId in this case
val events = KafkaUtils.createDirectStream[String, String, StringDecoder, StringDecoder]( ssc, kafkaParams, topicsSet).cache()
events.saveToCassandra("keyspace", "sensors_events")events.groupBy(e=>e(0))
.countByKey()
.foreachRDD(rdd=>rdd.foreach(i=>{
connector.withSessionDo(session=>{
val prepared = session.prepare("UPDATE sensor_counts SET measurements = ? WHERE sensorId = ? and ts = ?")
session.execute(prepared.bind(i._2, i._1, i._3))
})
}))
//batch job basically does the same thing and corrects any temporary problems
sc.cassandraTable("keyspace", "sensor_events").groupBy(e=>e(0))
.countByKey()
.foreachRDD(rdd=>rdd.foreach(i=>{
connector.withSessionDo(session=>{
val prepared = session.prepare("UPDATE sensor_counts SET measurements = ? WHERE sensorId = ? and ts = ?")
session.execute(prepared.bind(i._2, i._1, i._3))
})
}))
Fast and highly accurate but at the cost of storage. Must use Kafka. Will not lose messages once it’s inside Spark, but while messages loss is possible at the message queue, they can be recovered safely via Message Replay from the System Of Record.
Wrapping Up
This is all probably a lot to take in if it’s your first read, but this can be a useful guide later on as you get a better handle on the different options and their tradeoffs. Unfortunately with Big Data we’re still in a world where the best practices are widely established.