


How we build a robust analytics platform using Spark, Kafka and Cassandra
In today’s online world, supply chain is one of the most important pillars of any online shop. Not just quality products, but customers also want swift deliveries. This requires maintaining item availability at key locations, so that these items can reach customers in shortest possible time. This will also allow business users to keep a constant tab on inventory availability.
Given the sheer volume of items available on the Walmart website, it can become difficult to follow them on an individual SKU level. What business users need is a dashboard, where they can see the aggregated data of availability.
In this blog, we are going to cover exactly that — the platform we build to provide visualization for users to track item availability.
What were our main concerns?
With the new platform, we had to address a few concerns. Here is a look into them and the choices we made:
- High data flow
Given that a lot of orders get placed on the Walmart website every second, item availability also changes frequently. Updating data (which can be 100 MB per second) means streaming information to analytics platform in real-time.
So, how did we solve this issue? We chose Apache Kafka for it. Kafka is a distributed, scalable fault-tolerant messaging system which by default provides a streaming support.
- Storing terabytes of data with frequent updates
To store item availability data, we needed datastore which can process huge amount of upsert without compromising on performance . To even generate reports, data had to be processed every few hours — so read had to be fast too.
Though RDBMS can store large amount of data however it cannot provide reliable upsert and read performance. We had good experience with Cassandra in past, hence, it was the first choice. Apache Cassandra has best write and read performance. Like Kafka it is distributed, highly scalable and fault-tolerant.
- Processing huge amount of data
Data processing had to be carried out at two places in the pipeline. First, during write, where we have to stream data from Kafka, process it and save it to Cassandra. Second, while generating business reports, where we have to read complete Cassandra table, join it with other data sources and aggregate it at multiple columns.
For both the requirements, Apache Spark was a perfect choice. This is because Spark achieves high performance for both batch and streaming data, using a state-of-the-art DAG scheduler, a query optimizer, and a physical execution engine.
Architecture
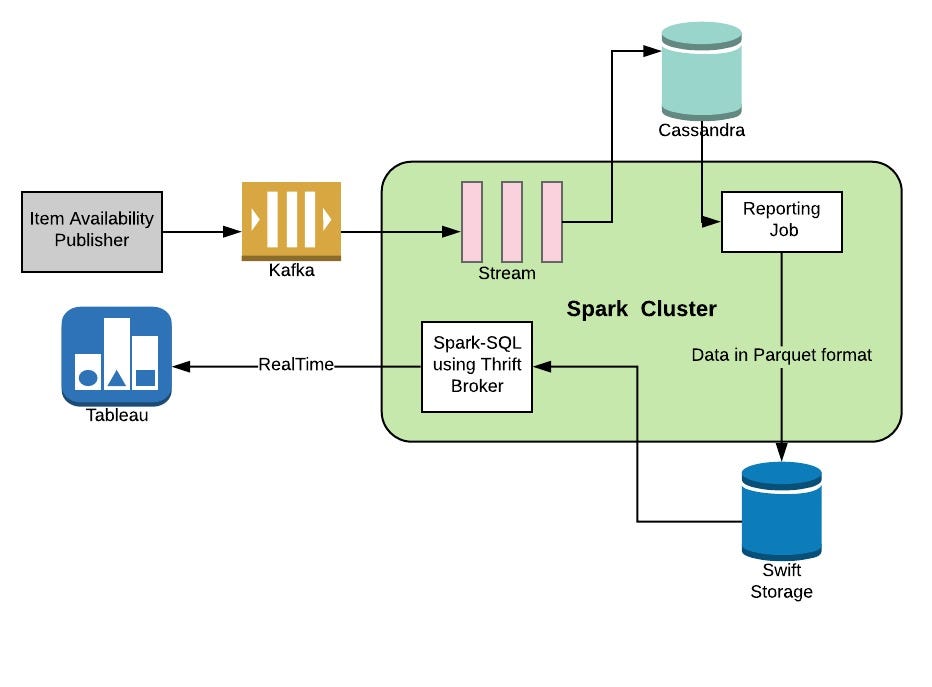
Below(Figure 1) is final architecture of our analytics platform we built using above-mentioned technologies.
Application maintaining item availability publish item availability updates in kafka topic. Spark streaming process kafka messages and persist data in cassandra.
Spark batch job are scheduled to run every 6 hour which read data from availability table in cassandra and write aggregated data in swift storage as parquet format.
For visualization we leverage Tableau. Hive table is created to read swift storage data in spark sql. To connect tableau with spark sql we use thrift server in spark side and spark sql connector in tableau side.
And that’s a wrap!
In conclusion, using Spark, Kafka and Cassandra can help us achieve both real-time, as well as batch processing. Go ahead and try out this platform to help you solve your streaming and batch issues!







