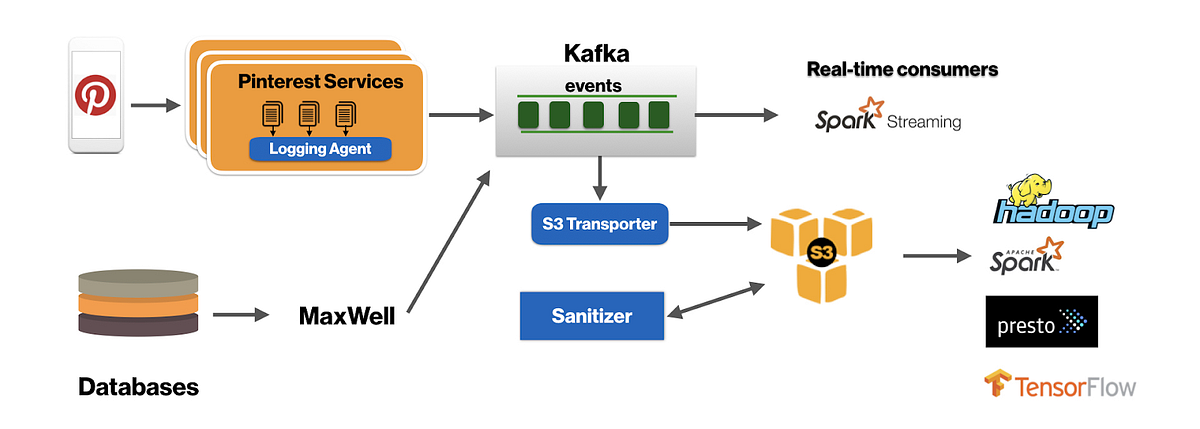
Global Cloud — Active-Active and Beyond
This is a continuing post on the Netflix architecture for Global Availability. In the past we talked about efforts like Isthmus and Active-Active:
We continue the story from where we left off at the end of the Active-Active project in 2013. We had achieved multi-regional resiliency for our members in the Americas, where the vast majority of Netflix members were located at the time. Our European members, however, were still at risk from a single point of failure.
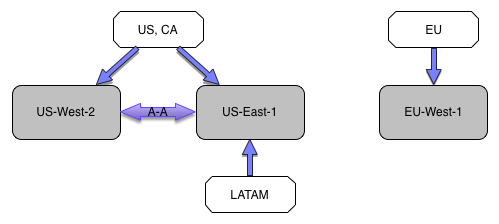
Our expansion around the world since then, has resulted in a growing percentage of international members who were exposed to this single point of failure, so we set out to make our cloud deployment even more resilient.
Creating a Global Cloud
We decided to create a global cloud where we would be able to serve requests from any member in any AWS region where we are deployed. The diagram below shows the logical structure of our multi-region deployment and the default routing of member traffic to AWS region.
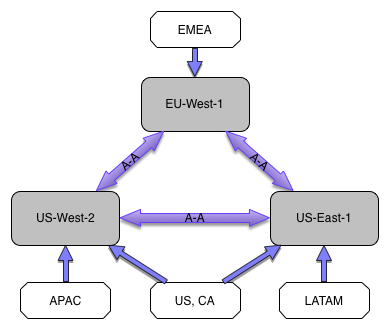
Getting There
Getting to the end state, while not disrupting our ongoing operations and the development of new features, required breaking the project down into a number of stages. From an availability perspective, removing AWS EU-West-1 as a single point of failure was the most important goal, so we started in the Summer of 2014 by identifying the tasks that we needed to execute in order to be able to serve our European members from US-East-1.
Data Replication
When we initially launched service in Europe in 2012, we made an explicit decision to build regional data islands for most, but not all, of the member related data. In particular, while a member’s subscription allowed them to stream anywhere that we offered service, information about what they watched while in Europe would not be merged with the information about what they watched while in the Americas. Since we figured we would have relatively few members travelling across the Atlantic, we felt that the isolation that these data islands created was a win as it would mitigate the impact of a region specific outage.
Cassandra
In order to serve our EU members a normal experience from US-East-1, we needed to replicate the data in the EU Cassandra island data sets to the Cassandra clusters in US-East-1 and US-West-2. We considered replicating this data into separate keyspaces in US clusters or merging the data with our Americas data. While using separate keyspaces would have been more cost efficient, merging the datasets was more in line with our longer term goal of being able to serve any member from any region as the Americas data would be replicated to the Cassandra clusters in EU-West-1.
Merging the EU and Americas data was more complicated than the replication work that was part of the 2013 Active-Active project as we needed to examine each component data set to understand how to merge the data. Some data sets were appropriately keyed such that the result was the union of the two island data sets. To simplify the migration of such data sets, the Netflix Cloud Database Engineering (CDE) team enhanced the Astyanax Cassandra client to support writing to two keyspaces in parallel. This dual write functionality was sometimes used in combination with another tool built by the CDE that could be used to forklift data from one cluster or keyspace to another. For other data sets, such as member viewing history, custom tools were needed to handle combining the data associated with each key. We also discovered one or two data sets in which there were unexpected inconsistencies in the data that required deeper analysis to determine which particular values to keep.
EVCache
As described in the blog post on the Active-Active project, we built a mechanism to allow updates to EVCache clusters in one region to invalidate the entry in the corresponding cluster in the other US region using an SQS message. EVCache now supports both full replication and invalidation of data in other regions, which allows application teams to select the strategy that is most appropriate to their particular data set. Additional details about the current EVCache architecture are available in a recent Tech Blog post:
Personalization Data
Historically the personalization data for any given member has been pre-computed in only one of our AWS regions and then replicated to whatever other regions might service requests for that member. When a member interacted with the Netflix service in a way that was supposed to trigger an update of the recommendations, this would only happen if the interaction was serviced in the member’s “home” region, or its active-active replica, if any.
This meant that when a member was serviced from a different region during a traffic migration, their personalized information would not be updated. Since there are regular, clock driven, updates to the precomputed data sets, this was considered acceptable for the first phase of the Global Cloud project. In the longer term, however, the precomputation system was enhanced to allow the events that triggered recomputation to be delivered across all three regions. This change also allowed us to redistribute the precomputation workload based on resource availability.
Handling Misrouted Traffic
In the past, Netflix has used a variety of application level mechanisms to redirect device traffic that has landed in the “wrong” AWS region, due to DNS anomalies, back to the member’s “home” region. While these mechanisms generally worked, they were often a source of confusion due the differences in their implementations. As we started moving towards the Global Cloud, we decided that, rather than redirecting the misrouted traffic, we would use the same Zuul-to-Zuul routing mechanism that we use when failing over traffic to another region to transparently proxy traffic from the “wrong” region to the “home” region.
As each region became capable of serving all members, we could then update the Zuul configuration to stop proxying the “misrouted” traffic to the member’s home region and simply serve it locally. While this potentially added some latency versus sticky redirects, it allowed several teams to simplify their applications by removing the often crufty redirect code. Application teams were given the guidance that they should no longer worry about whether a member was in the “correct” region and instead serve them the best response that they could give the locally available information.
Evolving Chaos Kong
With the Active-Active deployment model, our Chaos Kong exercises involved failing over a single region into another region. This is also the way we did our first few Global Cloud failovers. The following graph shows our traffic steering during a production issue in US-East-1. We steered traffic first from US-East-1 to US-West-2 and then later in the day to EU-West-1. The upper graph shows that the aggregate, global, stream starts tracked closely to the previous week’s pattern, despite the shifts in the amount of traffic being served by each region. The thin light blue line shows SPS traffic for each region the previous week and allows you to see the amount of traffic we are shifting.
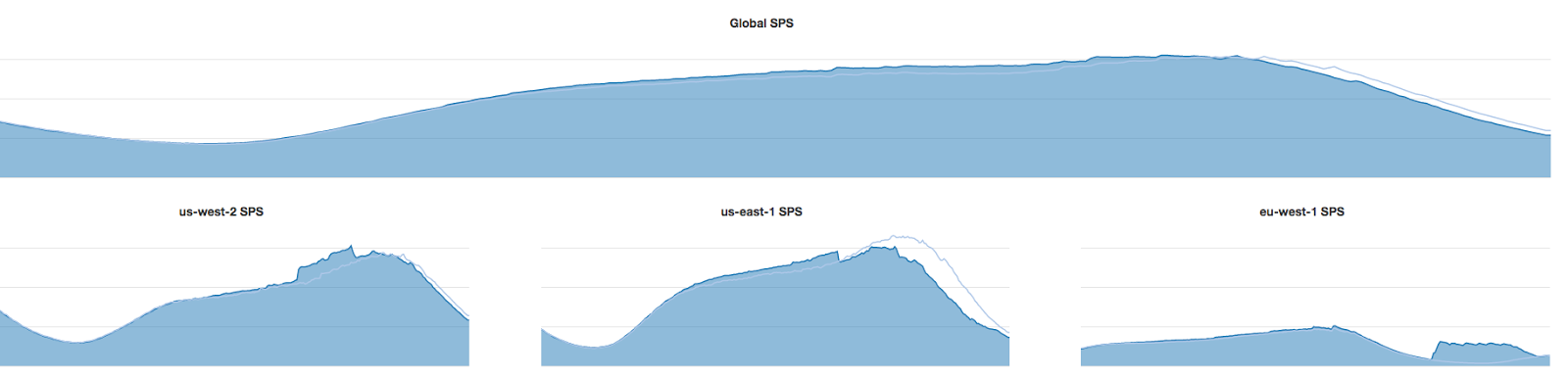
By enhancing our traffic steering tools, we are now able to steer traffic from one region to both remaining regions to make use of available capacity. The graphs below show a situation where we evacuated all traffic from US-East-1, sending most of the traffic to EU-West-1 and a smaller portion to US-West-2.
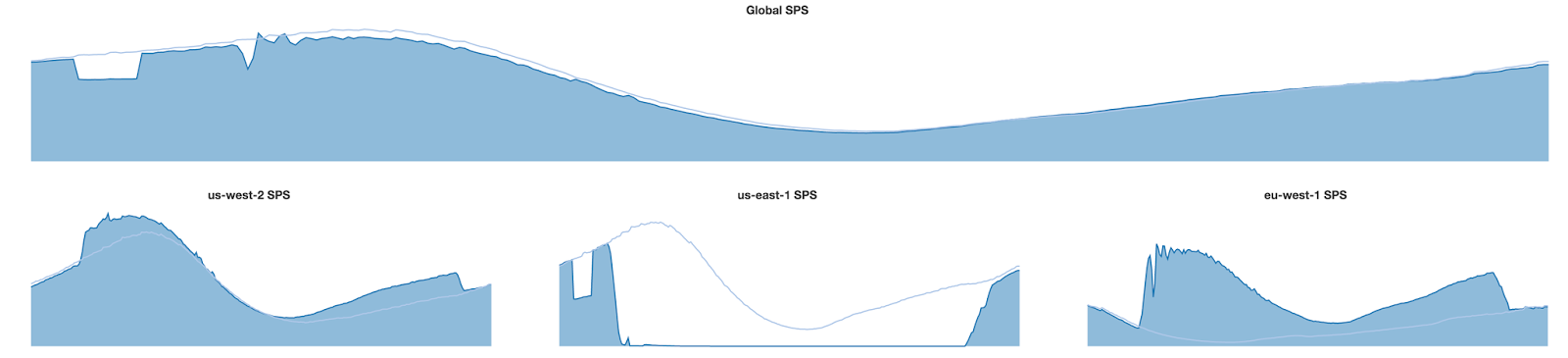
We have done similar evacuations for the other two regions, each of them involving rerouted traffic being split between both remaining regions based on available capacity and minimizing member impact. For more details on the evolution of the Kong exercises and our Chaos philosophy behind them, see our earlier post:
Are We Done?
Not even close. We will continue to explore new ways in which to efficiently and reliably deliver service to our millions of global members. We will report on those experiments in future updates here.
— Peter Stout on behalf of all the teams that contributed to the Global Cloud Project
Originally published at techblog.netflix.com on March 30, 2016.