
This blog is the second part of a series “Spark — the Pragmatic bits”. Get the full overview here.
My recent blogpost I explored a few cases where using Cassandra and Spark together can be useful. My focus was on the functional behaviour of such a stack and what you need to do as a developer to interact with it. However, it did not describe any details about the infrastructure setup that is capable of running such Spark code or any deployment considerations. In this post, I will explore this in more detail and show some practical advice in how to deploy Spark and Apache Cassandra.
The simplest and most obvious choice is to get DataStax Enterprise which contains Cassandra, Spark with a highly available Spark Master, and many more components bundled up. DataStax has good documentation about how to install and configure their solution: https://docs.datastax.com/en/latest-dse/
If you are already a user of DSE or considering adopting it, this is definitely the way to go.
On the other hand, the components to configure such a setup from scratch are all available as open source software. Going through the process also helps understanding how DSE ultimately works under the hood.
To do this, the following components are needed:
Be careful about the various versions of frameworks and libraries. There is a good “version compatibility” matrix on the GitHub wiki of the Spark-Cassandra connector. At the time of writing, the following versions were used:
- Cassandra 3.10
- Scala 2.11.8
- Spark 2.1.0
- Spark-Cassandra connector 2.0.0 (for Scala 2.11)
In order to keep things simple for this blogpost, I am going to use IP addresses alone to configure everything. In any production deployment you should consider using DNS names instead.
Let’s take a look at the process step-by-step.
First, we are going to need a running Cassandra cluster. The latest version is available for download from the Apache Cassandra website here: https://cassandra.apache.org/download/. We start with a simple Cassandra deployment, where, in the simple case there is no need for any extra configuration (see “Isolating workloads” section for more production-like recommendations).
Having configured and started the cluster, using the nodetool we should be able to view our state which should look as follows:
[centos@ip-10-0-10-73 ~]$ nodetool status
Datacenter: datacenter1
=======================
Status=Up/Down
|/ State=Normal/Leaving/Joining/Moving
-- Address Load Tokens Owns (effective) Host ID Rack
UN 10.0.12.48 266.17 KiB 256 32.2% 01e17441-61c3-4179-a9aa-cbe1795a0259 rack1
UN 10.0.11.65 272.64 KiB 256 34.4% 99f6d8c8-8c01-46c4-99b9-665b8bb98b4c rack1
UN 10.0.10.73 247.37 KiB 256 33.4% 1d6edc64-f625-4613-b8b9-f4d0131aa9ff rack1
To enable us to run a Spark jobs in a distributed fashion, we are going to need some kind of processing cluster overlaid on the Cassandra nodes. Spark is to a certain degree agnostic to what resource management framework we use — out of the box it can run on Mesos, YARN or it’s own standalone cluster manager. The simplest approach is to just use a standalone Spark cluster as it’s easy to set up and will do the job.
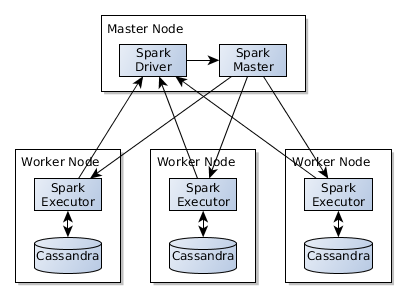
The diagram below shows a running Spark job along with the major components involved:
(source: https://spark.apache.org/docs/latest/cluster-overview.html)
- Cluster manager: the entry point of the cluster management framework from where the resources necessary to run the job can be allocated. The Cluster Manager only supervises job execution, but does not run any data processing
- Spark executor: executors are running on the worker nodes and they are independent processes belonging to each job submitted to the cluster. These executors are responsible to do the actual data processing.
- Driver application: this is what the end-user creates and it contains the coded (Scala, Java, Python, R) logic that is to be executed on the Spark cluster. In my previous blog, all the code examples belonged to the driver application.
The driver does not have to run on the same machines where we run the Spark Master or Workers, but it must be network addressable and reachable from them. The executors connect to the driver at the start of the process to obtain code and other artefacts as well as the decomposed processing tasks they need to execute.
It is generally a good idea to run the driver application “close” to the processing cluster, but not a strict requirement as long as the network addressability is fulfilled.
To perform a standalone cluster setup, the following needs to be done:
For a standalone cluster we are going to need 1 x Spark-master node and n number of Spark-slaves. To achieve optimal performance the slaves should be overlaid on the Cassandra cluster.
The Spark master node can be located on any of these slave machines, or on a separate box. It does not require a lot of resources to run therefore contention is not a major concern.
Additionally the location of the Spark driver application should be considered. Running this on a dedicated Spark master node would be a good place to do this.
In this example I will use a dedicated Spark master node that sits outside of the 3-node Cassandra cluster — with each Cassandra nodes additionally running a Spark slave. Having the dedicated Spark master is not essential, it could easily be co-located with one of the Spark slaves.
Spark can be downloaded from the Apache project website: https://spark.apache.org/downloads.html (please note that you have to download the Hadoop 2.7 pre-built version, even though in this case Hadoop will not actually be used).
Simply unpack this and move it to a directory where you ultimately want the Spark framework to be located (let’s say under /opt).
Spark comes with a number of configuration files located in the $SPARK_HOME/conf directory. Of these, we are specifically interested in spark-env.sh which configures some of the lower-level settings (IP addresses and port bindings of the Spark standalone cluster) and spark-defaults.conf which is responsible for setting defaults for the driver application.
Within spark-env.sh we set the following environ,environment variables:
export SPARK_LOCAL_IP=<host IP address to bind Spark worker to>
export SPARK_MASTER_HOST=<the IP address of Spark-master>
More interesting though is spark-defaults.conf. Although strictly speaking it is not necessary to configure these settings here, it is possible to supply the same values in the driver application or from the command-line — as I did previously. However, if we do configure these values here, it makes job submission easier. Also we know in advance that we want to use Spark and Cassandra together, there is no reason not to set these up.
spark.master spark://<Spark Master IP>:7077
spark.jars.packages datastax:spark-cassandra-connector:2.0.0-s_2.11
spark.cassandra.connection.host <comma separated list of IP addresses of the Cassandra cluster>
Let’s take a look line-by-line:
- spark.master: specifies the Spark master URL for any job submissions. When invoking
spark-submitit’ll by default send it to this cluster manager – our freshly set up Spark master - spark.jars.packages: specifies additional libraries to be included in executor classpaths. These maven coordinates point to the correct version of the Spark-Cassandra connector ensuring that by default, if we execute any jobs on this Spark cluster, the connector will be available, removing the need to specify it explicitly
- spark.cassandra.connection.host: the Cassandra nodes to connect to when reading/writing Cassandra tables from Spark. At minimum we’ll need to supply one Cassandra node (the driver will auto-discover the rest), but some fault-tolerance is introduced if we specify more than one.
Starting the standalone Spark cluster processes is simple — a start script is supplied in the $SPARK_HOME/sbindirectory. For the master, launchstart-master.sh.
By default this will start the Spark master process in the background. In a more production like setup,you would probably want this to be controlled by systemd – and consequently to run it in foreground. Setting environment variable SPARK_NO_DAEMONIZE=true achieves this.
Once the Spark Master is up, it exposes a simple web-based interface to monitor the workers, submitted applications, etc… This is available on http://{spark-master-ip}:8080
After startup, the Spark UI web page should look like the screenshot shown below:
With the Spark master up, the slaves can be started too. On each worker node launch start-worker.sh from$SPARK_HOME/sbin. This takes a single parameter – the location of the master node in the following form: spark://{spark-master-ip}:7077. Similarly to the master process, using SPARK_NO_DAEMONIZE will keep it in the foreground.
Once all the workers have started up, the Spark UI will list them:
At this point we have a working Spark standalone cluster that is pre-configured to talk to the the underlying Cassandra deployment and is ready to accept our job submissions.
Submitting an application is then simply achieved by running the spark-submit script on the Master node. As opposed to the examples in my previous post, most parameters are picked up from spark-defaults.conftherefore we no longer need to specify the Spark Master and the Cassandra node locations directly on the command line at job submission time:
$SPARK_HOME/bin/spark-submit \
--class com.opencredo.spark.CalculateCurrentBalance \
/<path-to-jar>/cassandra-spark-demo_2.11-1.0.jar
This script will stay in the foreground running until the job has finished (either successfully or with an error).
The Spark UI is quite versatile and useful — it allows you to track job executions as well as see detailed progress of each job and access the logs of the executors.
So far we have been running a single application on our Spark cluster. However in the real world it is likely you will have more than one job submitted at the same time — in fact in my previous examples there were 3 different use-cases. Let’s see what happens if we try to run them all at the same time:
for class in CalculateCurrentBalance CalculateAverageSpendingPerCounty FindSuspiciousTransactions; do \
spark-submit --class com.opencredo.spark.$class cassandra-spark-demo_2.11-1.0.jar & \
done
Please note how in this particular setup, two of the three jobs are currently in WAITING state. This is because the first one – Calculate Balances is currently using all the CPU resources in this cluster.
To counter this we can limit the CPU consumption of each job:
for class in CalculateCurrentBalance CalculateAverageSpendingPerCounty FindSuspiciousTransactions; do \
spark-submit --class com.opencredo.spark.$class --total-executor-cores 3 cassandra-spark-demo_2.11-1.0.jar & \
done
In this case we will have two jobs running in parallel — each using only 3 CPU cores, as specified at job submit time.
A standalone Spark cluster will otherwise schedule jobs in a FIFO manner.
Different cluster managers (specifically Mesos) allows for more fine-grained resource allocation, where jobs dynamically use only the resources they need at a given time.
Please note that if you are using spark-shell over this cluster, it shares the same resource pool that the jobs are using. As a result, you should limit its CPU and memory quota, too.
The setup described above is not highly available. While the executors and the data has redundancy and can survive nodes going down, the Spark Master node is a single point of failure (especially since it also runs the driver application). Problems on this node will at minimum remove our ability to submit new jobs and monitor existing processing.
In a standalone Spark cluster, it is possible to deploy “standby masters” using ZooKeeper: https://spark.apache.org/docs/latest/spark-standalone.html#high-availability
Note that in DataStax Enterprise you get a highly available Spark Master out of the box.
If other cluster managers (Mesos or YARN) are used, the HA model of the chosen technology should be considered.
The example deployment I describe in this blog uses a 3-node Cassandra cluster overlaid by a 3-node Spark cluster and a Spark Master node. This setup is appropriate for development and experimentation, but not recommended in any serious production deployments. The main reason is resource contention — Spark and Cassandra will compete for system resources; especially CPU and memory. If you have a highly transactional system with a large volume of reads and writes into Cassandra; running Spark jobs on the same infrastructure will impact the latencies of these reads and writes.
The recommended setup for any deployment where these technologies are to be used together is to isolate the workloads physically. This would be achieved by introducing a “logical” datacenter in Cassandra, specifically for analytical processing.
In that case we would have some Cassandra nodes that don’t have Spark running and others that do. Transactional processing would be directed to the “pure” Cassandra side of the cluster, while all data would still be replicated to the “analytics” side, where the batch processing happens. This way the Spark job execution would not impact the low-latency operations.
Manually executing the steps I have described above is possible, but not recommended. Cassandra and Spark are technologies that makes sense in a scale-out cluster environment, and work best with uniform machines forming the cluster. Automating the setup on these cluster members is highly recommended as it makes scaling out much easier and quicker. While writing this article, I have created an Ansible playbook that installs the infrastructure described above. Although this should not be considered a production-ready setup, it is a good starting point and illustration of how one would get started with an automated deployment.
The playbook is designed to work with Centos7 machines and is available here: https://github.com/opencredo/cassandra-spark-ansible










