
Hi Folks!! In this blog, we are going to learn how we can integrate Spark Structured Streaming with Kafka and Cassandra to build a simple data pipeline.
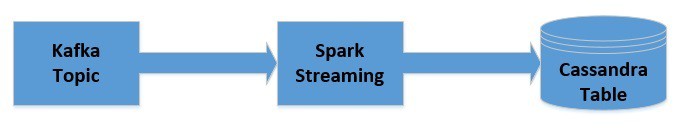
Spark Structured Streaming is a component of Apache Spark framework that enables scalable, high throughput, fault tolerant processing of data streams.
Apache Kafka is a scalable, high performance, low latency platform that allows reading and writing streams of data like a messaging system.
Apache Cassandra is a distributed and wide-column NoSQL data store.
Minimum Requirements and Installations
To start the application, we’ll need Kafka, Spark and Cassandra installed locally on our machine. The minimum requirements for the application:
Java 1.8+, Scala 2.12.10, SBT 1.3.8, spark 2.4.0 , Kafka 2.3.0 , Cassandra 3.10
Dependencies
libraryDependencies ++= Seq( "org.apache.spark" %% "spark-core" % sparkVersion, "org.apache.spark" %% "spark-sql" % sparkVersion, // streaming "org.apache.spark" %% "spark-streaming" % sparkVersion, // streaming-kafka "org.apache.spark" % "spark-sql-kafka-0-10_2.12" % sparkVersion, // low-level integrations "org.apache.spark" %% "spark-streaming-kafka-0-10" % sparkVersion, // cassandra "com.datastax.spark" %% "spark-cassandra-connector" % cassandraConnectorVersion, )
Connecting to Kafka and reading streams.
spark.readStream
.format("kafka")
.option("kafka.bootstrap.servers", "localhost:9092")
.option("subscribe", "kafkaToCassandra")
.option("startingOffsets", "earliest")
.load()
.selectExpr("cast(value as string) as value")
.select(from_json(col("value"), carSchema).as[Car])
In the above code snippet, reading JSON data from Kafka Topic “kafkaToCassandra” which contain information of Cars. The Car Model looks like below:
case class Car(
Name: String,
Miles_per_Gallon: Option[Double],
Cylinders: Option[Long],
Displacement: Option[Double],
Horsepower: Option[Long],
Weight_in_lbs: Option[Long],
Acceleration: Option[Double],
Year: String,
Origin: String
)
By the use of Spark Structured Streaming and reading the JSON data from Kafka topic we will get Dataset[Car] as a result. We can apply some Transformation to the Car Dataset then sink it to the Cassandra Database.
Writing Dataset to CassandraDB.
carDataset
.writeStream
.foreach(new CarCassandraForeachWriter(spark))
.start()
.awaitTermination()
Here we will extends ForeachWriter abstract class and implementing its three abstract method open, process and close for writing custom logic to process data generated by a query.
class CarCassandraForeachWriter(spark: SparkSession) extends ForeachWriter[Car] {
/*
- on every batch, on every partition `partitionId`
- on every "epoch" = chunk of data
- call the open method; if false, skip this chunk
- for each entry in this chunk, call the process method
- call the close method either at the end of the chunk or with an error if it was thrown
*/
val keyspace = "public"
val table = "car"
val connector: CassandraConnector = CassandraConnector(spark.sparkContext.getConf)
override def open(partitionId: Long, epochId: Long): Boolean = {
println("Open connection.")
true
}
override def process(car: Car): Unit = {
// Executing insert query to cassandraDB via CassandraConnector.
connector.withSessionDo { session =>
session.execute(
s"""
|insert into $keyspace.$table("Name", "Cylinders", "Horsepower")
|values ('${car.Name}', ${car.Cylinders.orNull}, ${car.Horsepower.orNull})
""".stripMargin)
}
}
override def close(errorOrNull: Throwable): Unit = println("Closing connection.")
}
We are all set with our handy code. Now lets start the Kafka and Cassandra services locally to test it.
Running Cassandra:
Go to the Cassandra bin directory and run the below command to start cassandra server:
./cassandra
Then, go inside the cassandra shell by open a new terminal and running a command:
./cqlsh
In the shell, Run below commands to create Keyspace public and car table into cassandra.
CREATE KEYSPACE [IF NOT EXISTS] public
WITH REPLICATION = {
'class' : 'SimpleStrategy', 'replication_factor' : 1 }
};
CREATE TABLE [IF NOT EXISTS] public.car("Name" text primary key, "Cylinders" int, "Horsepower" int );
Running Kafka
Go inside your kafka directory:
- Start Zookeper:
bin/zookeeper-server-start.sh config/zookeeper.properties
- Start Kafka server:
bin/kafka-server-start.sh config/server.properties
- Create Kafka Topic:
bin/kafka-topics.sh --create --zookeeper localhost:2181 --replication-factor 1 --partitions 1 --topic kafkaToCassandra
- Start Kafka Producer:
./bin/kafka-console-producer.sh --broker-list localhost:9092 --topic kafkaToCassandra
we can produce some sample messages in the Kafka topic kafkaToCassandra:
{“Name”:”saab 99e”, “Miles_per_Gallon”:25, “Cylinders”:4, “Displacement”:104, “Horsepower”:95, “Weight_in_lbs”:2375, “Acceleration”:17.5, “Year”:”1970-01-01″, “Origin”:”Europe”} {“Name”:”amc gremlin”, “Miles_per_Gallon”:21, “Cylinders”:6, “Displacement”:199, “Horsepower”:90, “Weight_in_lbs”:2648, “Acceleration”:15, “Year”:”1970-01-01″, “Origin”:”USA”} {“Name”:”chevy c20″, “Miles_per_Gallon”:10, “Cylinders”:8, “Displacement”:307, “Horsepower”:200, “Weight_in_lbs”:4376, “Acceleration”:15, “Year”:”1970-01-01″, “Origin”:”USA”}
Result
After running the application, we can check for the data stored in CassandraDB. Go to the Cassandra shell and run the below command:
select * from public.car;
We will get Name of the cars, Number of Cylinders used, and Horsepower of a cars into the CassandraDB that streams from Kafka.
You can find complete source code here






