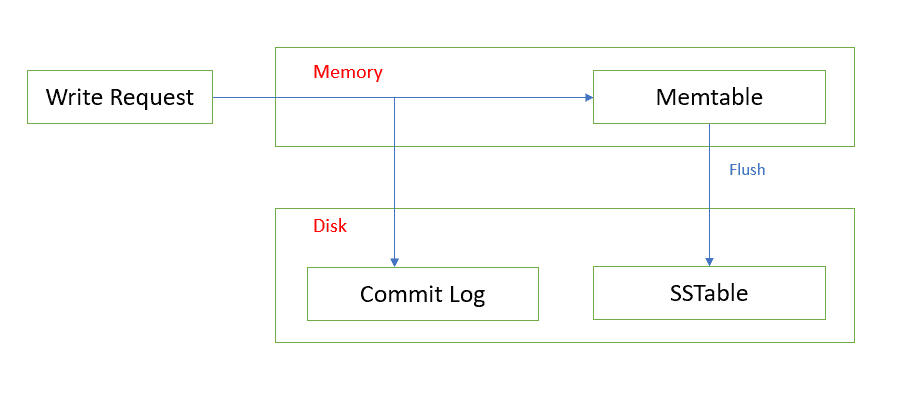

Tombstones are a mechanism which allows Cassandra to write fast but it has an operational price to pay. First of all, tombstones are themselves records. They take up space and can substantially increase the amount of storage you require. Secondly, querying tables with a large number of tombstones causes performance problems explained below.
Large Number of Tombstones Causes Latency and Heap Pressure
The cassandra.yaml comments explain in perfectly: “When executing a scan, within or across a partition, we need to keep the tombstones seen in memory so we can return them to the coordinator, which will use them to make sure other replicas also know about the deleted rows. With workloads that generate a lot of tombstones, this can cause performance problems and even exhaust the server heap.”
For illustration purposes consider the following table with a composite partition key of 2 columns, 2 clustering columns and 2 text columns:
A row with all values set in JSON representation is as follows:
If you delete real_col_1, the row will have a server timestamp, client timestamp and “d” flag which marks the column deleted:
If you delete the entire row, the tombstone will be as follows:
This gives you a rough estimate of how much extra data Cassandra loads into memory when reading tombstones along the way on executing a query. For a simple single partition query consider roughly a 1.5ms penalty for every 1000 tombstones encountered (performance may vary).
“How do we get tombstones without deleting anything?”
One common misconception is that tombstones only appear when the client issues DELETE statements to Cassandra. Some developers assume that it is safe to choose a way of operations which relies on Cassandra being completely tombstone free. In reality there are other many other things causing tombstones apart from issuing DELETE statements. Inserting null values, inserting collections and expiring data using TTL are common sources of tombstones. There is also a type of tombstones currently invisible to Cassandra tools and metrics – column range tombstones, so you may actually have a tombstone problem without realising you have tombstones at all.
Inserting null values
It is worth repeating that Cassandra is optimised for fast writes: it will not read data to check a condition before writing – that would slow writes down (Lightweight Transactions are one exception – they will read before writing at a cost of a 4x latency). As a result, even if the first value you ever write to a column is null, Cassandra will not check to see if that value already exists; it will simply mark the column with a tombstone for deletion. The statement below will result in a tombstone for value_2 even if it is the first insertion for key=1. The tombstone is highlighted in the JSON representation:
To avoid this, do not insert null values, use unset columns instead. In the previous example, we can leave col_2 unset instead of setting it to null in CQL. This is allowed as long as col_2 is not part of the primary key.
When using the Java driver, you can either omit the column name you are not setting when issuing an INSERT or UPDATE statement or use the unset() method (see documentation) on bound statements to explicitly alter it:
Inserting values into collection columns
Using Cassandra collections inevitably results in tombstones even if you never delete a value. Again, this is the result of Cassandra being optimised for writes. Consider the following table with list, set and map columns:
When you insert the first row into this table with collection values set you will see three tombstones recorded in an SSTable for collection_table:
Cassandra optimises for writes and does not check if the list has changed (or even existed), instead, it immediately deletes its before inserting the new one. Be aware of this when choosing to use collections as column types.
Expiring Data with TTL
Expiring data by setting a TTL (Time To Live) is one an alternative to deleting data explicitly but technically results in the same tombstones recorded by Cassandra and requiring the same level of attention as other types of tombstones.
The Invisible Column Range Tombstones
Issuing an explicit delete statement for a range of rows will result in a column range tombstone. Consider the following table:
Even with no data present, issuing the following delete statement will result in a corresponding range tombstone.
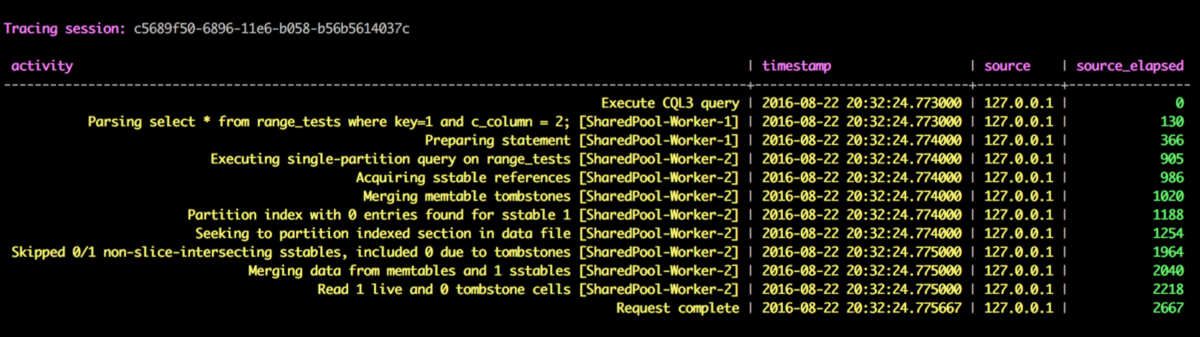
This is a normal column range tombstone whose format tells you that a whole collection for partition key 1 and clustering column 2 has been deleted. The problem with tombstones like this is that they are not accounted for in Cassandra metrics or diagnostic tools. The will not contribute to the number of tombstones in a tracing summary or average numbers of tombstones in nodetool tablestats. At the time of this writing it is a known problem and a ticket is raised for this in Cassandra JIRA. For example, selecting by key 1 and c_column 2 with tracing enabled will not report any tombstones encountered even though we know there is one. Note that tombstone warning / failure alerts set in cassandra.yaml will not detect column range tombstones either; this is also a known issue. For example, see the following tracing output:

Query Tracing
Even though column range tombstones are not currently logged or reported in Cassandra, they have exactly the same implications as other types of tombstones and should be avoided where possible. We suggest using the following tools and approaches to detect problems caused by tombstones.
Look into “Raw” SSTable Content for Answers
When uncertain about performance issues and suspecting tombstones or not knowing what generates tombstones, a good starting point is to inspect the contents of SSTables for the offending table. Use sstable2json (Cassandra sstabledump (Cassandra >= 3.0) to dump a JSON representation of an SSTable to console or file. For example:
This is especially useful for distinguishing between null values for columns and columns which haven’t been set. For example, consider the following insert statements:
Statement 1 will generate a tombstone for col_2, statement 2 will not, it will not create column col_2 for key 555 at all. You can see it in the JSON representation of the SSTable:
However, the data is displayed identically in CQL format, you will not be able to find tombstones caused by null values by looking at SELECT output:
It is also the only way to confirm existence of column range tombstones which are not logged by Cassandra and accordingly are not reported by any tools and metrics.
Set the appropriate gc_grace_seconds on tables
Routine repairs must be run on clusters where deletions occur (they may occur even if you don’t explicitly delete anything, see above) to avoid among other things deleted data becoming live again. You must run repairs more often than the minimum chosen gc_grace_period (see this article for more details). Make sure you are capable of supporting repairs more frequent than the minimum gc_grace_seconds among all your tables.
Changing the tombstone warning / failure threshold
Invisible column range tombstones aside, there are two tombstone threshold settings in cassandra.yaml helpful for detecting a large number of tombstones affecting performance:
– tombstone_warn_threshold (default: 1000): if the number of tombstones scanned by a query exceeds this number Cassandra will log a warning (which will likely be propagating to your monitoring system and send you an alert).
– tombstone_failure_threshold (default: 10000): if the number of tombstones scanned by a query exceeds this number Cassandra will abort the query. The is a mechanism to prevent one or more nodes from running out of memory and crashing.
These values should only be changed upwards if you are really confident about the memory use patterns in your cluster.
Conclusion
Tombstones are among the most misunderstood features of Cassandra and can cause significant performance problems if not investigated, monitored and dealt with in a timely manner. OpenCredo has acquired expertise in detecting and solving tombstone related problems on various projects by successfully using the tools shared above.