Cassandra Schemas for Beginners (like me)
I was awe-struck when I first learned that Cassandra had tables. Then followed was another question along the line of how was it even a NoSQL database.
Upon reading and playing around with it I began to realize that the rows and columns were just what’s on the surface. Cassandra is as NoSQL as any other databases.
I’ve been working on a project that utilizes greatly on using Cassandra as a JSON storage, and that required a great understanding than working with document-based solutions like MongoDB or CouchDB, which already provide ways to store JSON out of the box. The first idea was storing a JSON blob as a string value in a single column, but that was a pretty bad idea to start with and contradicts greatly to the very reason of using Cassandra, since it would require my application to parse that JSON string every time.
Storing JSON in a Cassandra column as a text or []byte contradicts greatly to the very reason of using Cassandra.
Cassandra is more similar to key-value-based NoSQL databases like Redis or a hashtable. For someone coming from relational SQL world, the comfort will end at the CQL syntax and setting primary keys. Coming from NoSQL like MongoDB, however, one will have to get over the query language and schemas but once they pass the NoSQL mental model can be adapted to Cassandra very quickly.
This is my best attempt at relating Cassandra schema design to a more traditional key-value data format like JSON to better educate myself with the hope of somebody else getting something out of it too.
NoSQL != Schemaless
NoSQL stands for Not Only SQL. It does not mean no schemas. For many, using document- and key-value-based NoSQL databases can lead to this misconception. Even key-value data pairs like JSON has schema or structure. It’s just more flexible to changes than a relational table-based schema.
The Only Difference
The only real distinction most, if not all, NoSQL databases have from SQL or relational databases is the lack of relationship between two distinct data collections, tables, documents or whatever each database uses as the term to define a a set of related data. You kind of just query a table or a document, get the appropriate data, and then query another table to perform a cross-table query or namely the JOIN operation in the SQL world (This will lead to the argument number 2 below).
The only distinction NoSQL databases have from a relational SQL-based databases is the lack of inter-collection relationships.
The long-standing argument between the SQL and NoSQL camps sums up to:
- the fact that a relational database can never scale as easily as NoSQL.
- Relational databases provide more flexible and robust queries while for NoSQL, without knowing the structure or schema, one is forced to think hard about how an application will access the data. This is known as query-driven design.
I will not talk about the topic of scalability since most NoSQL users should be well-aware of that, and it’s best discussed somewhere else. However, I will focus on the underlying structure of Cassandra for the hope of a better understanding that will lead to a better query-driven designed schemas.
Cassandra as a Key-value Database
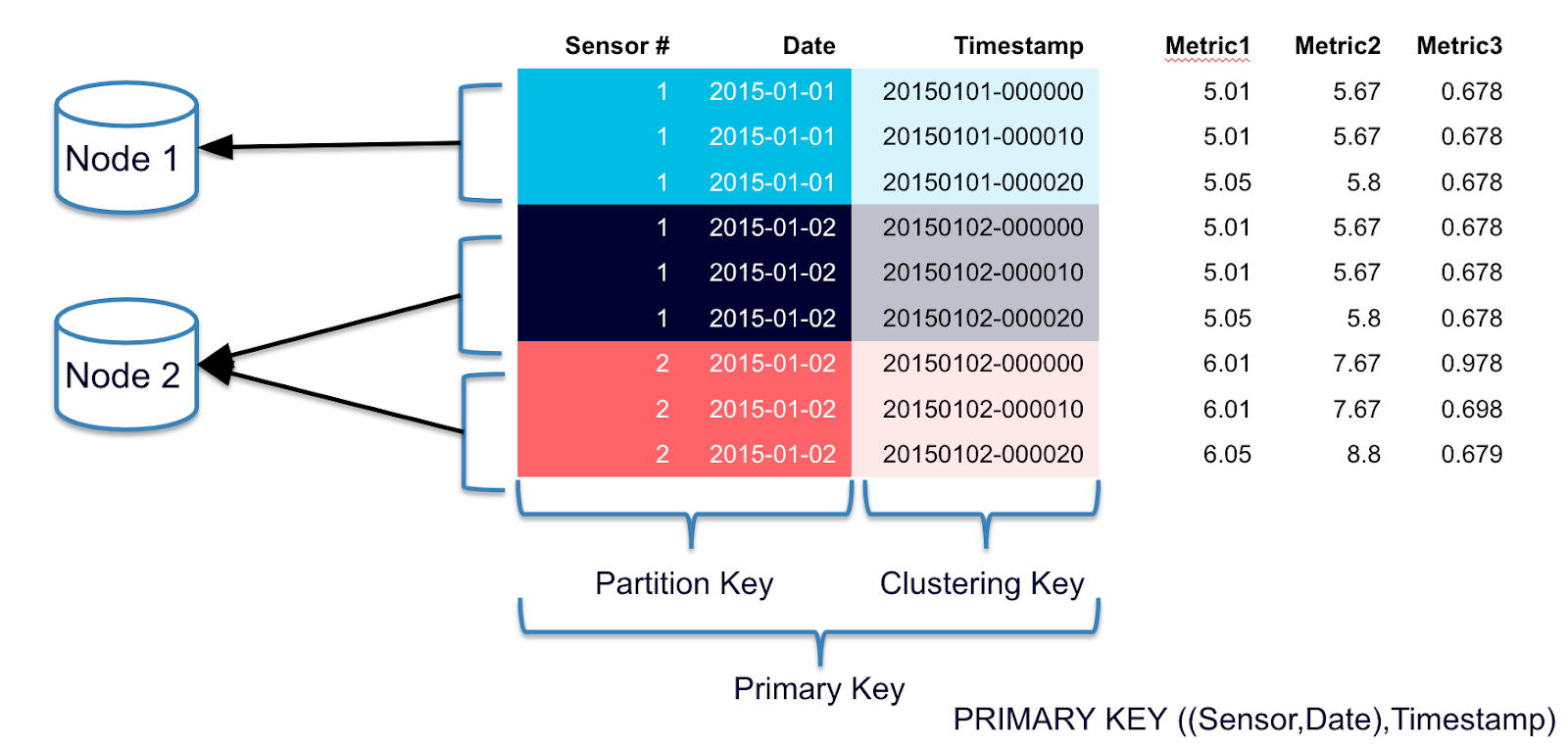
Cassandra can be thought of as a key-value database. Under the hood and beyond its Cassandra Query Language (CQL) and schemas, it actually contains a lookup key for every data in the form of a primary key.
Considering this user_tweets table:

The username field acts as a first and only primary key, which in Cassandra’s speak is called the partition key. A partition key is very important in Cassandra and it basically groups all the related rows together for efficient storage and lookup. This will become clearer once we have more than one tweet per username. The partition key hence can be seen as the “lookup” key similar to what you might have dealt with in any hash table, map, dictionary or other key-value structure.
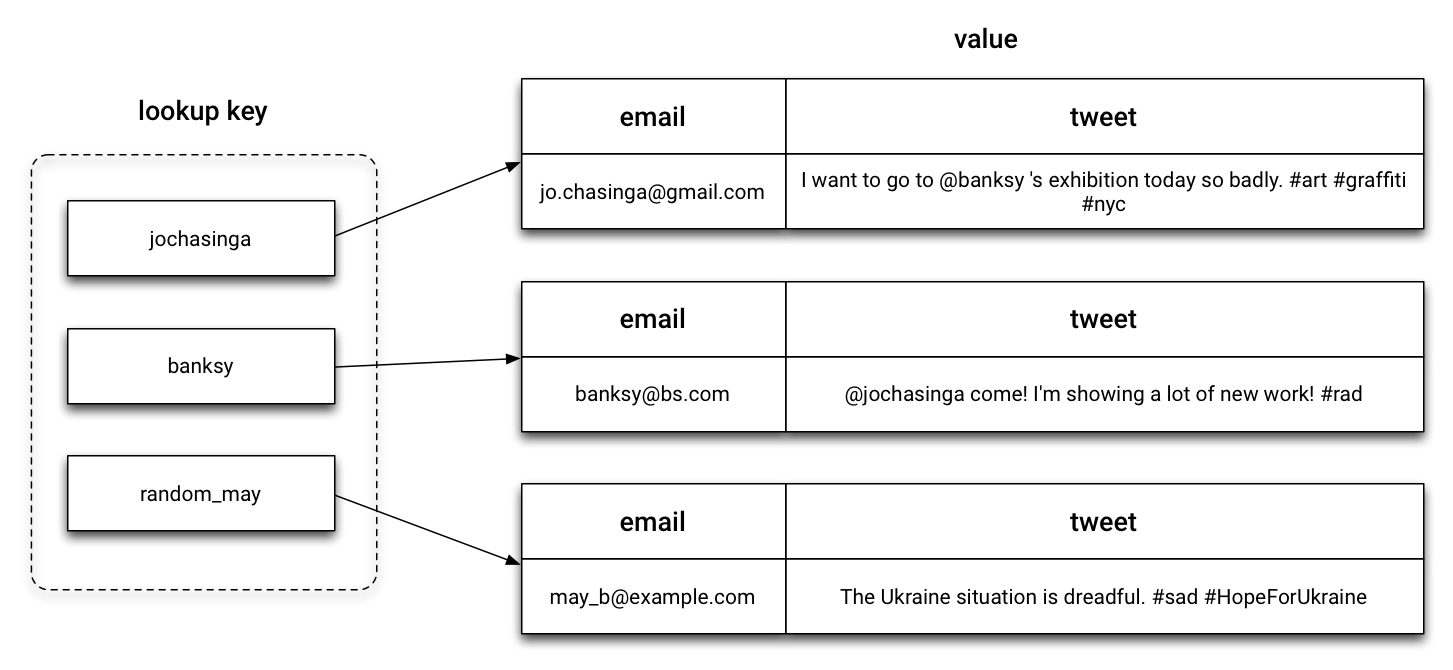
We can simplify it to a JSON structure (not entirely accurate, but useful as a mental model for someone coming from Redis or MongoDB).
One thing that should be noted very cautiously is that in Cassandra, unlike what the JSON array might portray, each partition of grouped rows under a partition key is stored non-contiguously, possibly on different nodes, making it very costly to access each of them together. In the previous table, if you look at the key-value relationship diagram, you’ll see that each row is not related to one another at all and is stored apart from one another.
This can never be overstated. We can never access the second-level data (for instance, the email of a user) without accessing the primary username key first. Think of it as a JSON array as portrayed previously. To get to my email, the username must be provided as the key beforehand.
var tweets = JSON.parse(tweet_data)
var my_email = tweets[0]['jochasinga']['email'];
The CQL rough equivalence of the above would have been
SELECT "email" FROM "user_tweets" WHERE "username" = 'jochasinga';
We supply the primary key, or the “lookup” key to the WHERE clause, hence it’s very cheap to retrieve the email value of that username.
If we try to query a row by supplying another non-key column to the WHERE clause, we would be getting an error warning us that it’d be very unwise to do so.
SELECT * FROM "user_tweets" WHERE "email" = 'jo.chasinga@gmail.com';
The above CQL query, reads “select all columns from user_tweets table where the email is ‘jo.chasinga@gmail.com’.”, would return an erratic warning:
InvalidRequest: code=2200 [Invalid query] message=”Cannot execute this query as it might involve data filtering and thus may have unpredictable performance. If you want to execute this query despite the performance unpredictability, use ALLOW FILTERING
It makes sense if you think about it. In a table with many more rows, querying by a non-key column like email tells Cassandra to iterate through every primary key username before hitting the right email value and retrieving the row. Here’s the rough approximation of the query in Javascript querying the previous JSON:
tweets.forEach(function(elm, i, arr) {// Retrieve an array of all the keys
var keys = Object.keys[elm]
if elm[keys[0]]['email'] == "jo.chasinga@gmail.com" {
return elm
}
}
If you have a million rows of tweets, or in the JSON version, a million objects, you would end up traversing through every one blindly hopefully hitting your luck early. Also remember that each partition is possibly stored on a separate node from one another. You are of course given an option to execute this query anyway by using ALLOW FILTERING flag, but you’ve been warned.
Things start to become clearer when we introduce another tweet_id column as a clustering column for the tweet table. Let’s say I retweeted to @banksy tweet, making two tweets for me.

The tweet_id is a clustering column with time_uuid type, ordering rows under jochasinga partition key in an time-ascending order. The email field is being declared as STATIC meaning it is consistent for all the tweets for a user and there’s no need of duplicates. The mental model will be similar to this:
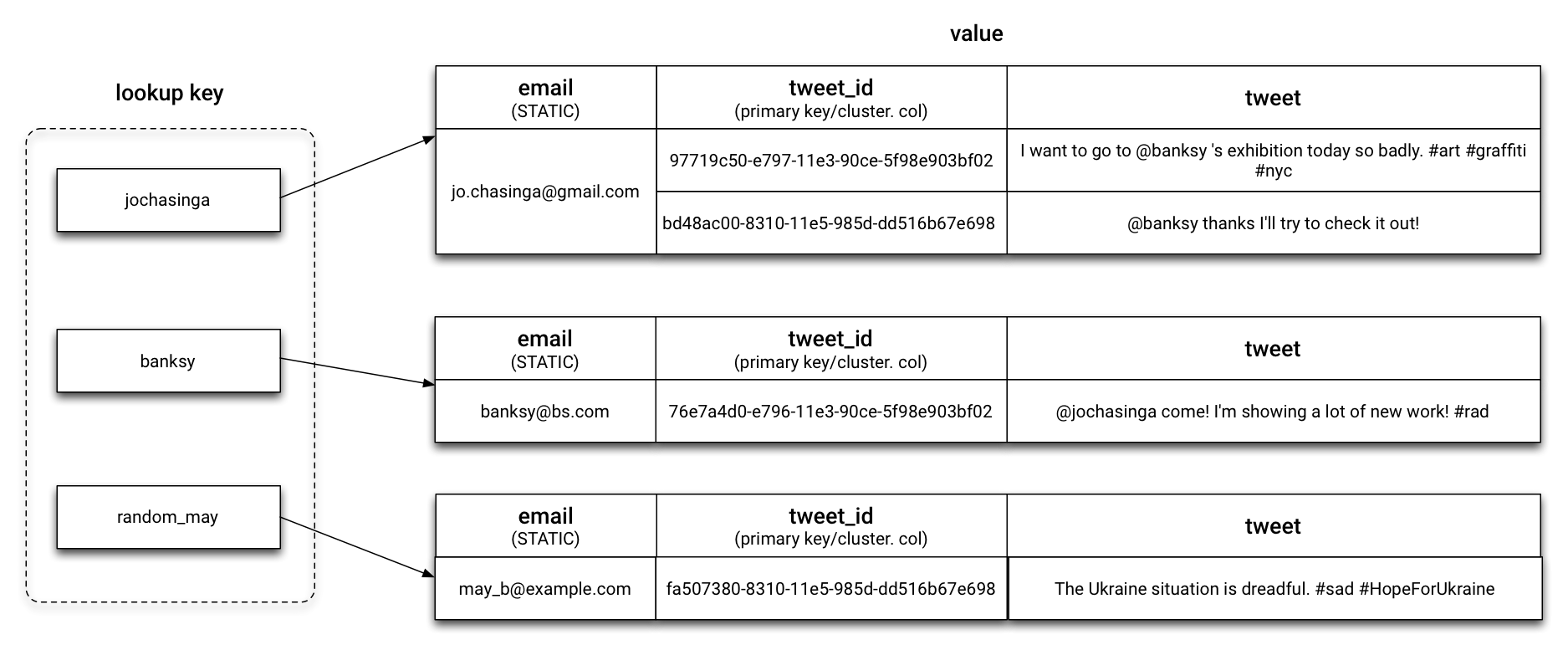
And the approximate JSON-style representation would be something like
Note that tweet_id value is simplified to string instead of time_uuid type for just for brevity, and there was no such field as row_data in the table. It’s just how JSON needs a “key” for every value, and that how tweet_id column orders the row data within a username’s partition is similar to how an array store data. However, in Cassandra, the tweet_id encapsulates the time information used in the ordering of each row. With this JSON representation, the index of the array has nothing to do with the tweet_id value.
Now with ‘jochasinga’ having more than one tweet, to query a specific one, you either have to do the following:
- Query directly using a partition key and a unique primary key, in this case, the tweet_id.
SELECT * FROM "user_tweets" WHERE "username" = 'jochasinga' AND "id" = bd48ac00-8310-11e5-985d-dd516b67e698;
2. Query using a partition key and another unique primary key column OR non-key column, like the tweet body.
SELECT * FROM "user_tweets" WHERE "username" = 'jochasinga' AND "tweet" = '@banksy thanks I'll try to check it out!'
And in return, this is the row we get

Secondary Indexes
Secondary indexes are sort of a “hack” to promote a non-key column (that is, a column that is not a primary key) to a secondary “key” that you can query against just like a primary key. This is just like a reverse lookup. For instance, querying with a username you can get the email of the user.
SELECT "email" FROM "user_tweets" WHERE "username" = 'jochasinga';
In some case, we may want to query a username based on the email. By creating an index on email, you can perform that kind of reverse lookup.
Note: Right now it is not possible to create an index on a static column, though in theory that can be done. See this thread on how Apache is planning to include this feature in the next versions.
We will add another column of type list<text> to store hashtags in a tweet. It makes sense considering how Twitter displays tweets with the corresponding hashtag in the search results. For instance, when a user search for all the tweets with hashtag #funnycats, Twitter could have queried it this way:
SELECT * FROM "user_tweets" WHERE "hashtags" CONTAINS "funnycats";
Pretty self-descriptive.
But without “marking” the hashtags column, it would return a complaint just like how we tried querying with a non-key column value.
Let’s add the hashtags column and see how that goes.
ALTER TABLE "user_tweets" ADD "hashtags" list<text>;
At this point, we will have to alter the data of the previous tweets’ hashtags column, since the column we have just added contains nothing on each row.
UPDATE "user_tweets" SET "hashtags" = ['art', 'graffiti', 'nyc'] WHERE "username" = 'jochasinga' AND "id" = bd48ac00-8310-11e5-985d-dd516b67e698;
UPDATE "user_tweets" SET "hashtags" = ['rad'] WHERE "username" = 'banksy' AND "id" = 76e7a4d0-e796-11e3-90ce-5f98e903bf02;
UPDATE "user_tweets" SET "hashtags" = ['sad', 'HopeForUkraine'] WHERE "username" = 'random_may' AND "id" = fa507380-8310-11e5-985d-dd516b67e698;
Then create a secondary index on the hashtags column
CREATE INDEX ON "user_tweets" ("hashtags")We will turn up with a new version of user_tweets that looks like this:
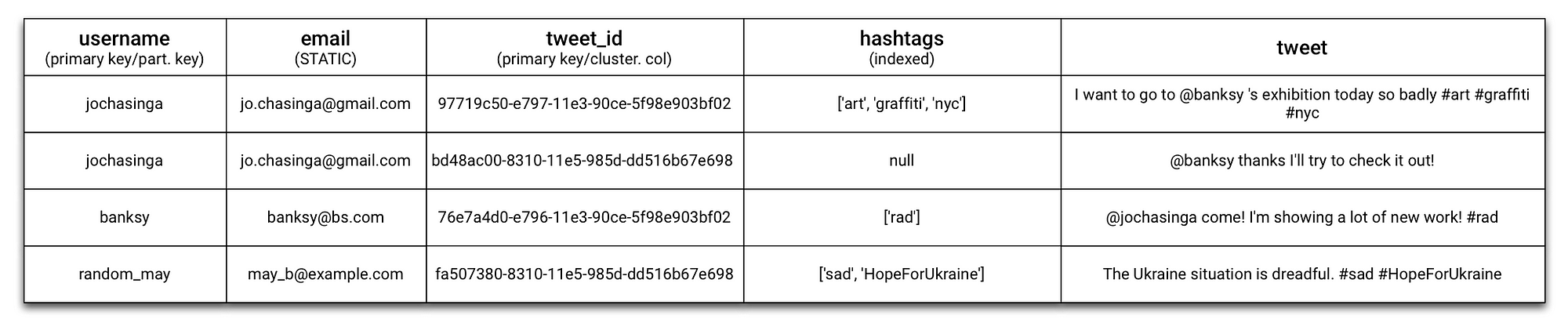
Now we will be able to query against the hashtags like Twitter search would have done it.
SELECT * FROM "user_tweets" WHERE "hashtags" CONTAINS 'art';
Guess which row will be returned. (my first tweet, of course!)
I said secondary indexes are “hacks” because they don’t scale well and should be used sparingly especially on columns with high-cardinality, meaning data are mostly distinct. It is more suitable for columns with low-cardinality like, say, static columns (scroll above to see why it isn’t possible yet to create an index on static columns). This article is great at elaborating the problem that comes with Cassandra’s secondary indexes.
Conclusion
It is best to think of Cassandra as a structure of sorted key-value pairs of documents than cells of data, and this was proved to be very useful for my process of designing the schema around what I needed. Partition keys and clustering columns are almost the only two most important friends of yours.
DON’T RESTRICT YOURSELF WITH SCHEMAS.
Here is a few rules you can remember
- To partition is to separate two things from each other. So if you create your table like this
CREATE TABLE "my_users" (
id uuid,
email text,
password blob,
country text,
PRIMARY KEY (country, id)
);
You are making users from two different countries will be stored separately. Rows in a partition will be ordered according to the unique id.
CREATE TABLE "my_users" (
id uuid,
email text,
password blob,
city text,
country text,
PRIMARY KEY ((country, city), id)
);
Users from the same country, but in different cities will be stored separately. Rows in a partition will be ordered by id.
- Clustering column, or the second primary key, decide how you want the database to be ordered. (Either ascending or descending)
- Secondary indexes avoid denormalization, or the process of creating redundant data to create effective single-partition reads, but they are quite costly and should be used on medium-traffic queries.
- Add columns at will. Cassandra is flexible and rows without data do not take memories (there’s no NULL pointer value for missing value).