Apache Cassandra was open-sourced by Facebook. It is designed to handle large amounts of data across many commodity servers, with high-availability across multiple datacenters, master-less replication, and low latency. It can store hundreds of terabytes of data, is decentralized, and fault-tolerant. Its data model is based on the Cassandra Query Language, or CQL. It is a hybrid between two families of databases: key-value and column-oriented.
Cassandra data modeling is a process of structuring the data and designing the tables by identifying entities and their relationships, using a query-driven approach to organize the schema in light of the data access patterns. Understanding indexing is an important step in the data modeling process, as it impacts performance of the queries.
A good data model can be the difference between a successful NoSQL project and a failed one. This is also true for Cassandra data model where the schema design greatly influences the speed at which data is written and retrieved.
Cassandra's Data Model
The Cassandra data model can be difficult to understand initially as some terms, similar to those used in the relational world, can have a different meaning here, while others are completely new.
A keyspace is the container for tables in a Cassandra data model. A table is the container for an ordered collection of rows. Rows are made of a primary key plus an ordered set of columns, themselves made of name/value pairs.

There is no need to store a value for every column each time a new row is stored. Cassandra's data model can hold wide rows with lots of columns (up to millions of columns!...) It can also hold many rows with a smaller set of columns.
The primary key is a composite made of a partition key plus an optional set of clustering columns. The partition key is used to determine the nodes on which rows are stored, and it can consist of multiple columns. The clustering columns control how data is sorted within a partition. Cassandra also supports static columns, storing data that is not part of the primary key, but shared by every row in a partition.
When a column is created, a data type is defined to constrain the values stored in that column. Data types include character and numeric types, collections, and user-defined types. Three types of collections can be defined: sets, lists, and maps. A column also has other attributes: timestamps and time-to-live. A timestamp is generated for a column value, each time it is created or updated, to resolve any conflicting change to the value. The time-to-live (TTL) is used to indicate how long to keep the value.
A secondary index is an index on any columns that is not part of the primary key. Since Cassandra partitions data across multiple nodes, each node must maintain its own copy of a secondary index for the rows it stores. Therefore, secondary indexes are not recommended on columns with high cardinality or very low cardinality, or on columns that a frequently updated or deleted.
Joins cannot be performed at the database level. If there is need for a join, either it must be performed at the application level, or preferably, the Cassandra data model should be adapted to create a denormalized table that represents the join results.
Chebotko Diagrams
Dr. Artem Chebotko, a Solution Architect at DataStax, introduced a methodology and notation to capture and visualize Cassandra data models for table schemas and supporting. The methodology is based on the successive steps of traditional relational normalized data modeling: conceptual, logical, physical. It results in Chebotko Diagrams for better visualization.
Hackolade recognizes several novelties brought to light by the Chebotko diagrams and notation, but takes some liberties with them in order to further simplify and streamline the process. As explained in this article, we advocate that conceptual modeling should be replaced by Domain Driven Design, whose approach and terminology are a much better fit with NoSQL concepts. In particular, DDD aggregates map directly to denormalization and data nesting, allowing the elimination of data joins. This direct mapping between DDD bounded context aggregates to nested objects has another sizable advantage: it allows the elimination of the logical data modeling step.
Cassandra Data Modeling Tool
Hackolade has pioneered the field of data modeling for NoSQL databases, introducing a graphical software to perform the schema design of hierarchical and graph structures.

Hackolade is a Cassandra schema design software that dynamically forward-engineers CQL scripts as the user visually builds a Cassandra data model. It can also reverse-engineer an existing Cassandra or DataStax instance to derive the schema so a data modeler or information architect can enrich the model with descriptions, metadata, and constraints.
Retrieving the Cassandra CREATE TABLE CQL script, Hackolade persists the state of the instance data model, and generates HTML documentation of the database schema to serve as a platform for a productive dialog between analysts, designers, architects, developers, and DBAs. The Cassandra schema design tool supports several use cases to help enterprises manage their databases.
Components of a Cassandra Data Model
As a date modeler starts from the application access patterns and query model, physical tables can be created in the tool, including their columns with their properties and constraints.
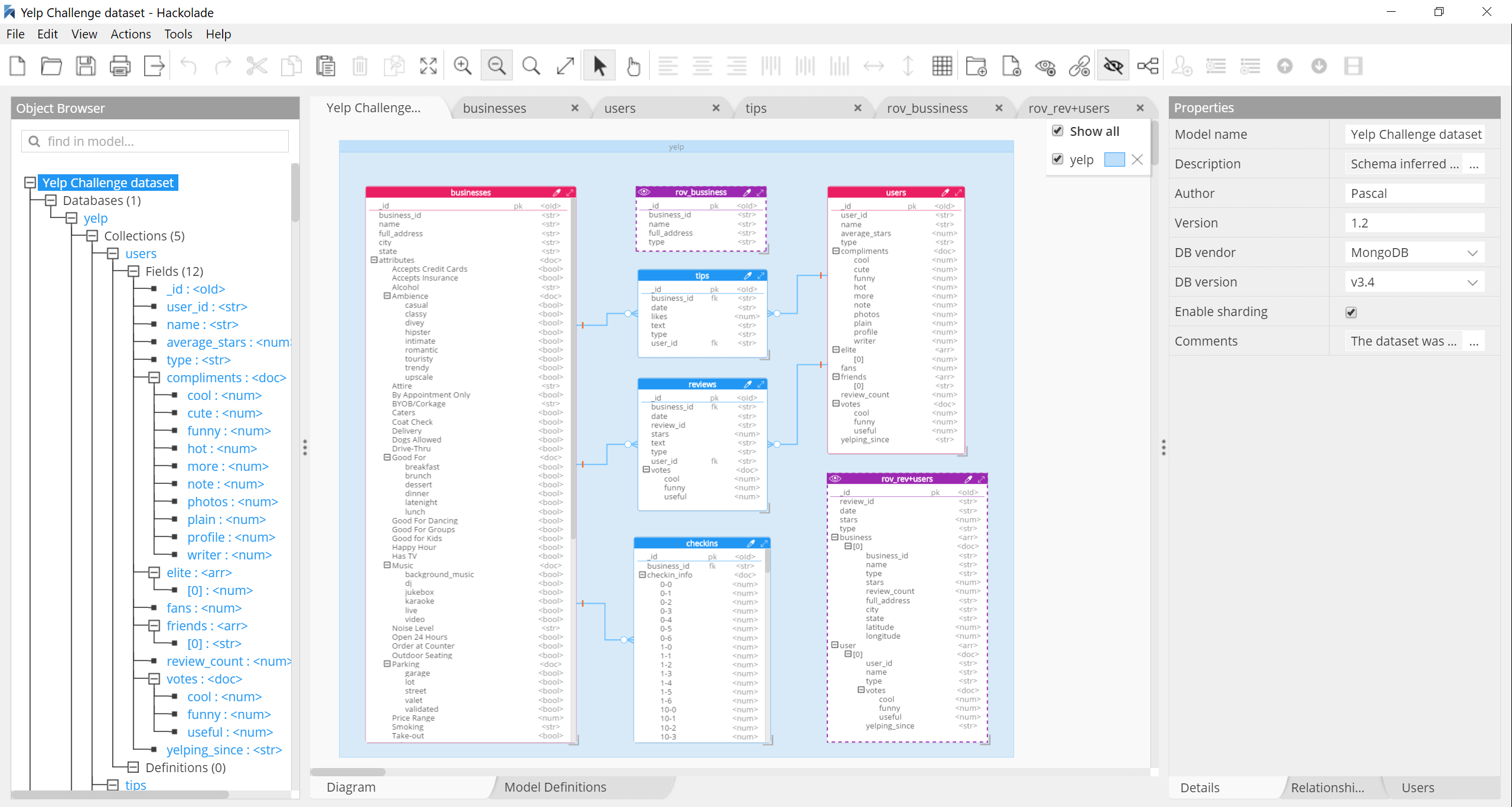
Entity Relationship Diagram (ERD)
Hackolade lets users visualize a Cassandra schema via an Entity-Relationship Diagram of the physical data model.

Hierarchical view of nested objects
As denormalization is applied, implicit relationships can be documented, user-defined types created and referenced in different places. It is also possible to design JSON hierarchical structures with nested objects. This can be supplemented with detailed descriptions and a log of team comments gathered as the Cassandra data model adapts over time for the schema evolution.

Outputs of a Schema Design Tool for Cassandra
In addition to the dynamic CQL script creation to facilitate development, Hackolade provides a rich, human-readable HTML report, including diagrams, collections, relationships and all their metadata. Many additional features have been developed to help data modelers.

Benefits of Data Modeling
A data model provides a blueprint for applications that closely represent the understanding of complex data-centric enterprises. Hackolade increases data agility by making data structures transparent and facilitating its evolution. The benefits of data modeling for Cassandra are widespread and measurable.
NoSQL schema design is a best practice to ensure that applications evolve, scale, and perform well. A good data model helps reduce development time, increase application quality, and lower execution risks across the enterprise.
Free trial
To experience the first Cassandra data modeling tool and try Hackolade free for 14 days, download the latest version of Hackolade and install it on your desktop. There's no risk, no obligation, and no credit card required! The software runs on Windows, Mac, and Linux, plus it supports several other leading NoSQL databases.