
Cassandra and CQL — what they don’t tell you
A lot of companies are using Cassandra. Should you?
Cassandra has a fantastic set of features which makes it very appealing:-
- Low latency reads and writes with tuneable consistency
- Decentralised — no single point of failure
- Linear scalability
It’s clear why the likes of Netflix and Apple have huge Cassandra instances for their data storage needs.
We integrated Cassandra into the THG e-commerce platform as part of our recommendations pipeline. Overall, Cassandra has delivered on its feature set and has earned the title of having the fastest response times of any database technology we have tested. Our Cassandra instance is split across our two data centres in London and Manchester, serving a huge volume of customer traffic every day.
Like any technology that you are unfamiliar with, it’s easy to fall into pitfalls however. Our journey with Cassandra has been a long one and the knowledge we have gained could help developers who are new to Cassandra.
CQL is not SQL
For those who don’t know, the primary method of querying Cassandra is using the Cassandra Query Language (CQL). Let’s create a table of customer order information:-
CREATE TABLE customers (
customer_id int,
order_id int,
order_timestamp int,
PRIMARY KEY (customer_id, order_id)
) WITH CLUSTERING ORDER BY (order_id ASC)
And let’s write a query that gets all of the order ids associated with a particular customer id:-
SELECT order_id FROM customers WHERE customer_id=123456
Doesn’t this look familiar? CQL has been designed to be similar to SQL so its queries are very similar.
Now let’s ask another question, how many orders did we have after a certain date:-
SELECT count(*) as total_orders FROM customers WHERE order_timestamp > '2018-11-09 12:00'
InvalidRequest: Error from server: code=2200 [Invalid query] message="Cannot execute this query as it might involve data filtering and thus may have unpredictable performance. If you want to execute this query despite the performance unpredictability, use ALLOW FILTERING"
What’s going on? This is valid SQL…
The problem revolves around our primary key. For Cassandra, the primary key tells it exactly where to look for the data we want. A primary key of,
(customer_id, order_id)
means that we have a partition keyed by customer_id and within that partition the data is ordered in order of order_id. To perform the query shown above, Cassandra doesn’t know where the data is stored so it will have to perform a full table scan. Essentially this is what the ‘ALLOW FILTERING’ flag is saying we should do.
At this point you have a several options:-
- Re-think your table’s primary key to get the data you want;
- Add an index to the order_timestamp column. What this does is it duplicates your data into another table under the hood in the format you want for that query. This slows down your writes significantly and increases your storage;
- Add ALLOW FILTERING to your query and accept that it will be slow and probably timeout. Speaking from experience, this is nearly always a bad idea;
- Tell your stake holder that has been pestering you for this that it is impossible to get the information they want.
For anyone who has used or read about Cassandra, the above it not hugely controversial. Once you have a basic understanding of how Cassandra is working you should know that you’re never going to be able to get all the features of a relational database, or indeed many of them at all. Still, CQL’s similarities to SQL give you the illusion that you do have those features which can be a real tripping point for new starters to the Cassandra.
When you are creating a query you always need to keep in mind about how Cassandra is storing your data and what is the most efficient way to query it. Another way of phrasing it is that you need the right primary key. The primary key is an instruction set for Cassandra to tell it where your data should go. A good or bad choice here can have a huge impact on performance.
Deleting data and tombstones
Let’s consider a user wanting to insert some data, for example:-
INSERT INTO customers (customer_id, order_id, order_timestamp) VALUES (123456, 100000, toTimestamp(now()))
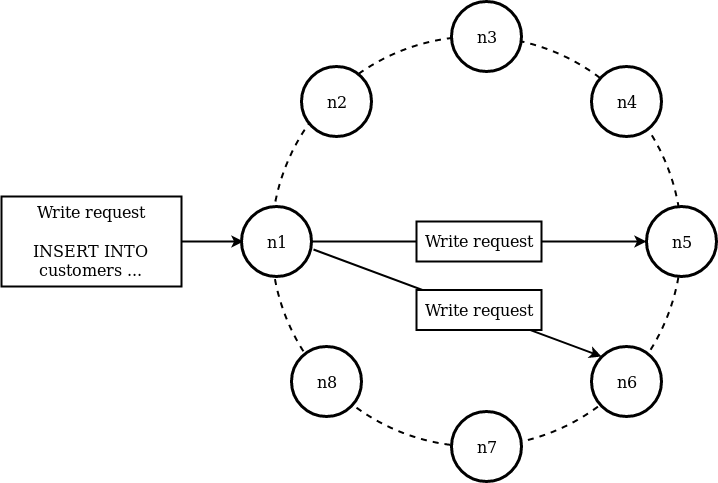
Since Cassandra is a distributed datastore, this write will propagate to multiple nodes/datacentres throughout the cluster. How many nodes it will propagate to will depend on the schema of your keyspace and how data is distributed.
With this write, if the write to nodes n6 and n7 were successful then when we want to read this data, the two nodes will give a consistent response.
Now let’s consider the scenario where we want to delete this row from the database:-
DELETE FROM customers WHERE customer_id=123456
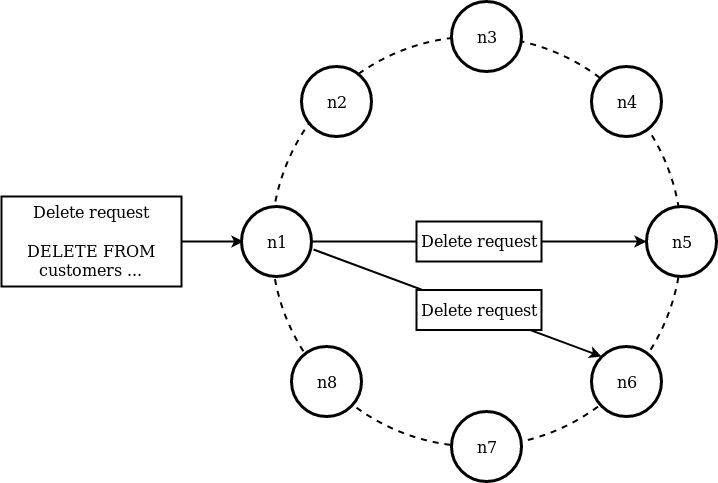
What if one of these requests fails? Depending on the consistency set on your delete query, this may fail entirely or will succeed leading to the two nodes will report inconsistent results. If we consider the second case, when we ask the two nodes for this data again, one will think the data is still there and the other will say it’s deleted. How can Cassandra distinguish the missing data came from a user explicitly deleting data?
The mechanism Cassandra implements to solve this problem is by writing tombstones. When a user requests to delete data, it actually writes a tombstone next to that data and doesn’t delete anything. Deletes are treated just like any other write.
If there is a high churn rate on your data (i.e. lots of deletes/writes) this strategy for storing data won’t be effective in the long run. It will use more disk space and your partitions will be full of junk data. Ultimately Cassandra undergoes a process called compaction to clean up the tombstones.
When we were using Cassandra, we came across a scenario where certain partitions within our Cassandra instance were undergoing very high data churn with lots of conflicting reads and writes on the same partition. As a result of this the entire cluster began to slow down as it was trying to deal with the requests to the partitions which are undergoing a lot of writes. The resolution to this was ultimately to design a new primary key to avoid these scenarios.
NULLs are nearly always bad
Following on from the above discussion of tombstones, we should discuss how NULLs work in Cassandra.
Cassandra treats NULLs as deleted data, meaning they are tombstones. If we add the following to Cassandra:-
INSERT INTO customers (customer_id, order_id, order_timestamp) VALUES (123456, 100000, NULL)
The data which is stored in the database looks like:-
{"partition" : {"key" : [ "123456" ],
"position" : 34
},
"rows" : [
{"type" : "row",
"position" : 66,
"clustering" : [ 100000 ],
"liveness_info" : {
"tstamp" : "2018-11-21T09:30:08.349095Z"
},"cells" : [
{
"name" : "order_timestamp",
"deletion_info" : {
"local_delete_time" : "2018-11-21T09:30:08Z"
}}
]
}
The reason for this is that Cassandra doesn’t try to read if data already exists, as it is too slow. Even if there was no data there originally it will create a row with a tombstone to represent the NULL value.
Unlike deleting a full row, these tombstones never compact and have a big impact on performance. It’s nearly always better to use a placeholder value instead of a null (e.g. an empty string).
In conclusion, Cassandra offers excellent features and performance, but beware of the principles mentioned when starting on your Cassandra implementation journey.
We’re recruiting
Find out about the exciting opportunities at THG here:






