Successfully reported this slideshow.
Cassandra advanced data modeling

Upcoming SlideShare
Loading in …5
×
No Downloads
No notes for slide
- 1. Cassandra Advanced data modeling Lyon Cassandra Users Romain Hardouin 2016-05-31
- 2. $ who Romain $ pgrep -fl work Cassandra architect $ whatis teads No.1 Video Advertising Marketplace
- 3. I. Introduction II. Key principles III. Chebotko methodology IV. Time handling Data modeling
- 4. I. Introduction
- 5. Theory
- 6. Theory Chebotko diagrams E&R
- 7. II. Key principles
- 8. Know your data DenormalizeKnow your queries Key Principles Nest Data Duplicate Data
- 9. Know your domain Conceptual Data Model, E&R ● Entities ● Relationships ● Attributes / Keys ● Cardinalities ● Constraints Know your data
- 10. Entities & relationships Know your data
- 11. Query-driven model Application Workflow New needs? ● New queries => new tables ● Alter table possible? Know your data Know your queries
- 12. Goal: one partition per query Anti-pattern: ● Table scan ● Client joins (a.k.a multi-table) ● Secondary index ● Allow filtering Know your data Know your queries
- 13. Nest Data Clustering columns Collection columns UDT columns Know your data Denormalize
- 14. Nest Data Know your data Denormalize CREATE TABLE actors_by_video ( video_id uuid, actor_name text, character_name text, PRIMARY KEY ((video_id), actor_name, character_name) );
- 15. Duplicate data Writes are cheap: « Joins on write » Duplication occurs at different levels: ● Table: Materialized views ● Partition ● Rows Know your data Denormalize
- 16. III. Chebotko Methodology
- 17. From « A Big Data Modeling Methodology for Apache Cassandra »From « A Big Data Modeling Methodology for Apache Cassandra » Application workflowApplication workflow Query workflow Query list
- 18. From « A Big Data Modeling Methodology for Apache Cassandra »From « A Big Data Modeling Methodology for Apache Cassandra » Chebotko DiagramChebotko Diagram
- 19. actors_by_video video_id uuid K actor_name text C↑ character_name text C↑ CREATE TABLE actors_by_video ( video_id uuid, actor_name text, character_name text, PRIMARY KEY ((video_id), actor_name, character_name) ); Chebotko DiagramChebotko Diagram
- 20. MR 1 Entities & Relationships MR 2 Equality search attributes MR 3 Inequality search attribues Chebotko mapping rules MR 5 Key attributes, uniqueness MR 4 Ordering attributes <>= ↑↓
- 21. From « A Big Data Modeling Methodology for Apache Cassandra »From « A Big Data Modeling Methodology for Apache Cassandra » Chebotko mapping rulesChebotko mapping rules
- 22. Internet of Things Demo Kashlev Data Modeler
- 23. IV. Time handling - Tombstones - TTL - UPSERTs
- 24. IV. Time handling - Tombstones - TTL - UPSERTs
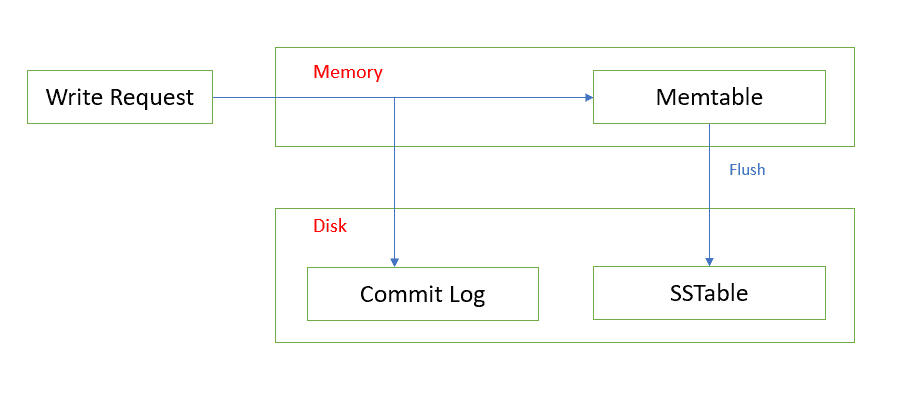
- 25. Eventually consistency No instant deletes Deletes are writes SSTables are immutable files Writes are spread across many files
- 26. Goal: avoid to read too many* tombstones ... ... * see tombstone_warn_threshold & tombstone_failure_threshold
- 27. IV. Time handling - Tombstones - TTL - UPSERTs
- 28. TTLsTTLs Data must be designed to be TTL'ed tombstones
- 29. Why? What we add?
- 30. TIMEdimension
- 31. IV. Time handling - Tombstones - TTL - UPSERTs
- 32. UPSERTsUPSERTs Same INSERT over and over again? UPSERTs hide this behavior What if… one day you want to add time
- 33. Questions?
- 34. Resources « A Big Data Modeling Methodology for Apache Cassandra » - Artem Chebotko, Andrey Kashlev & Shiyong Lu - www.cs.wayne.edu/andrey/papers/TR-BIGDATA-05-2015-CKL.pdf KDM - Andrey Kashlev - kdm.dataview.org
Public clipboards featuring this slide
No public clipboards found for this slide