

Successfully reported this slideshow.
Your SlideShare is downloading.
Cassandra 2.1 boot camp, Read/Write path

































Upcoming SlideShare
Loading in …5
×
No notes for slide
- 1. CASSANDRA 2.1 READ/WRITE PATH Cassandra Summit 2014 Boot Camp Josh McKenzie josh.mckenzie@datastax.com
- 2. CORE COMPONENTS
- 3. Core Components • Memtable – data in memory (R/W) • SSTable – data on disk (immutable, R/O) • CommitLog – data on disk (W/O) • CacheService (Row Cache and Key Cache) – in-memory caches • ColumnFamilyStore – logical grouping of “table” data • DataTracker and View – provides atomicity and grouping of memtable/sstable data • ColumnFamily – Collection of Cells • Cell – Name, Value, TS • Tombstone – Deletion marker indicating TS and deleted cell(s)
- 4. MemTable • In-memory data structure consisting of: • Memory pools (on-heap, off-heap) • Allocators for each pool • Size and limit tracking and CommitLog sentinels • Map of Key AtomicBTreeColumns • Atomic copy-on-write semantics for row-data • Flush to disk logic is triggered when pool passes ratio of usage relative to user-configurable threshold • Memtable w/largest ratio of used space (either on or off heap) is flushed to disk
- 5. On heap vs. Off heap Memtables: an overview • http://www.datastax.com/dev/blog/off-heap-memtables-in-cassandra-2-1 • https://issues.apache.org/jira/browse/CASSANDRA-6689 • https://issues.apache.org/jira/browse/CASSANDRA-6694 • memtable_allocation_type • offheap_buffers moves the cell name and value to DirectBuffer objects. The values are still “live” Java buffers. This mode only reduces heap significantly when you are storing large strings or blobs • offheap_objects moves the entire cell off heap, leaving only the NativeCell reference containing a pointer to the native (off-heap) data. This makes it effective for small values like ints or uuids as well, at the cost of having to copy it back on-heap temporarily when reading from it. • Default in 2.1 is heap buffers
- 6. On heap vs. Off heap: continued • Why? • Reduces sizes of objects in memory – no more ByteBuffer overhead • More data fitting in memory == better performance • Code changes that support it: • MemtablePools allow on vs. off-heap allocation (and Slab, for that matter) • MemtableAllocators to allow differentiating between on-heap and off-heap allocation • DecoratedKey and *Cells changed to interfaces to have different allocation implementations based on native vs. heap
- 7. SSTable • Ordered-map of KVP • Immutable • Consist of 3 files: • Bloom Filter: optimization to determine if the Partition Key you’re looking for is (probably) in this sstable • Index file: contains offset into data file, generally memory mapped • Data file: contains data, generally compressed • Read by SSTableReader
- 8. CommitLog • Append-only file structure corresponding – provides interim durability for writes while they’re living in Memtables and haven’t been flushed to sstables • Has sync logic to determine the level of durability to disk you want - either PeriodicCommitLogService or BatchCommitLogService • Periodic: (default) checks to see if it hit window limit, if so, block and wait for sync to catch up • Batch: no ack until fsync to disk. Waits for a specific window before hitting fsync to coalesce • Singleton – façade for commit log operations • Consists of multiple components • CommitLog.java: interface to subsystem • CommitLogManager.java: segment allocation and management • CommitLogArchiver.java: user-defined commands pre/post flush • CommitLogMetrics.java
- 9. CacheService.java • In-memory caching service to optimize lookups of hot data • Contains three caches: • keyCache • rowCache • counterCache • See: • AutoSavingCache.java • InstrumentingCache.java • Tunable per table, limits in cassandra.yaml, keys to cache, size in mb, rows, size in mb • Defaults to keys only, can enable row cache via CQL
- 10. ColumnFamilyStore.java • Contains logic for a “table” • Holds DataTracker • Creating and removing sstables on disk • Writing / reading data • Cache initialization • Secondary index(es) • Flushing memtables to sstables • Snapshots • And much more
- 11. CFS: DataTracker and View • DataTracker allows for atomic operations on a “view” of a Table (ColumnFamilyStore) • Contains various logic surrounding Memtables and flushing, SSTables and compaction, and notification for subscribers on changes to SSTableReaders • 1 DataTracker per CFS, 1 AtomicReference<View> per DataTracker • View consists of current Memtable, Memtables pending flush, SSTables for the CFS, and SSTables being actively compacted • Currently active Memtable is atomically switched out in: • DataTracker.switchMemtable(boolean truncating)
- 12. ColumnFamily.java • A sorted map of columns • Abstract class, extended by: • ArrayBackedSortedColumns • Array backed • Non-thread-safe • Good for iteration, adding cells (especially if in sorted order) • AtomicBTreeColumns (memtable only) • Btree backed • Thread-safe w/atomic CAS • Logarithmic complexity on operations • Logic to add / retrieve columns, counters, tombstones, atoms
- 13. THE READ PATH
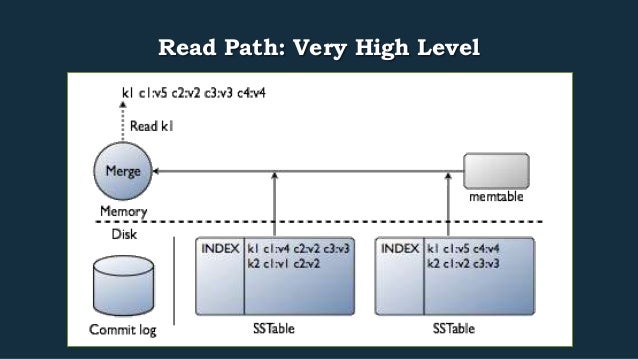
- 14. Read Path: Very High Level
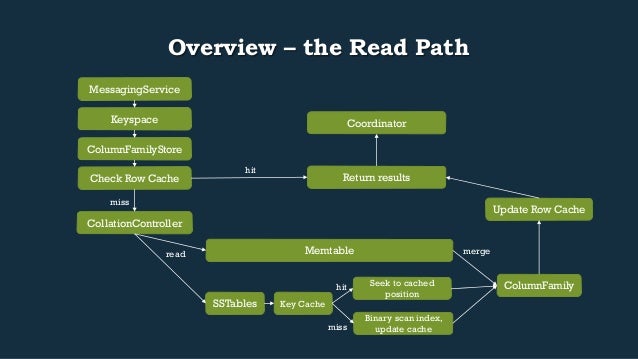
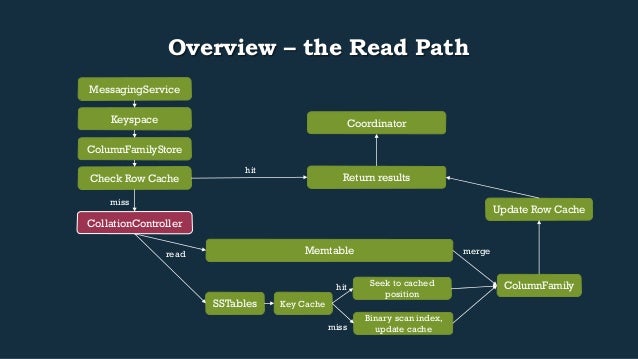
- 15. Overview – the Read Path Return results Keyspace ColumnFamilyStore Check Row Cache CollationController hit miss Memtable read merge SSTables Update Row Cache ColumnFamily Coordinator MessagingService Key Cache Seek to cached position Binary scan index, update cache hit miss
- 16. Read-specific primitive: QueryFilter • Wraps IDiskAtomFilter • IDiskAtomFilter: used to get columns from Memtable, SSTable, or SuperColumn • IdentityQueryFilter, NamesQueryFilter, SliceQueryFilter • Contains a variety of iterators to collate on disk contents, gather tombstones, reduce (merge) Cells with the same name, etc • See: • collateColumns(…) • gatherTombstones(…) • getReducer(final Comparator<Cell> comparator)
- 17. Read-specific class: SSTableReader • Has 2 SegmentedFiles, ifile and dfile, for index and data respectively • Contains a Key Cache, caching positions of keys in the SSTR • Contains an IndexSummary w/sampling of the keys that are in the table • Binary search used to narrow down location in file via IndexSummary • getIndexScanPosition(RowPosition key) • Short running operations guarded by ColumnFamilyStore.readOrdering • See OpOrder.java – producer/consumer synchronization primitive to coordinate readers w/flush operations • Access is reference counted via acquireReference() and releaseReference() for long running operations (See CASSANDRA-7705 re: moving away from this) • Provides methods to retrieve an SSTableScanner which gives you access to OnDiskAtoms via iterators and holds RandomAccessReaders on the raw files on disk
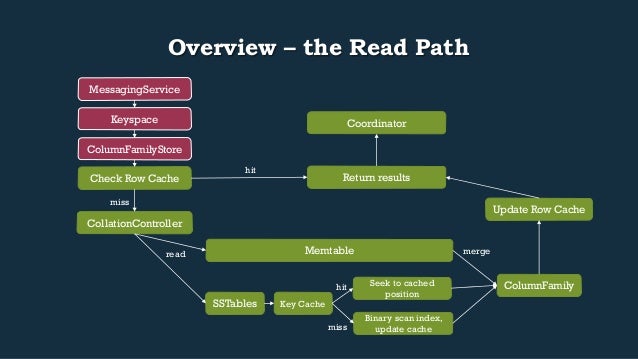
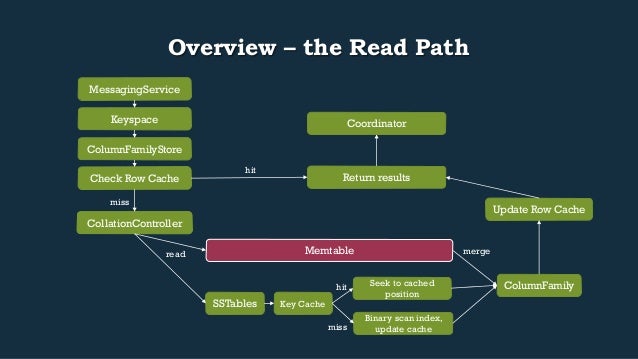
- 18. Overview – the Read Path Return results Keyspace ColumnFamilyStore Check Row Cache CollationController hit miss Memtable read merge SSTables Update Row Cache ColumnFamily Coordinator MessagingService Key Cache Seek to cached position Binary scan index, update cache hit miss
- 19. ReadVerbHandler and ReadCommands • Messages are received by the MessagingService and passed to the ReadVerbHandler for appropriate verbs • ReadCommands: • SliceFromReadCommand • Relies on SliceQueryFilter, uses a range of columns defined by a ColumnSlice • SliceByNamesReadCommand • Relies on NamesQueryFilter, uses a column name to retrieve a single column • Both diverge in calls and converge back into implementers of ColumnFamily • ArrayBackedSortedColumns, AtomicBTreeSortedColumns public Row Keyspace.getRow(QueryFilter filter) { ColumnFamilyStore cfStore = getColumnFamilyStore(filter.getColumnFamilyName()); ColumnFamily columnFamily = cfStore.getColumnFamily(filter); return new Row(filter.key, columnFamily); }
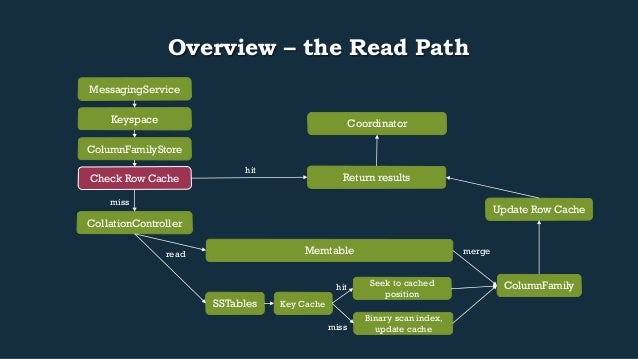
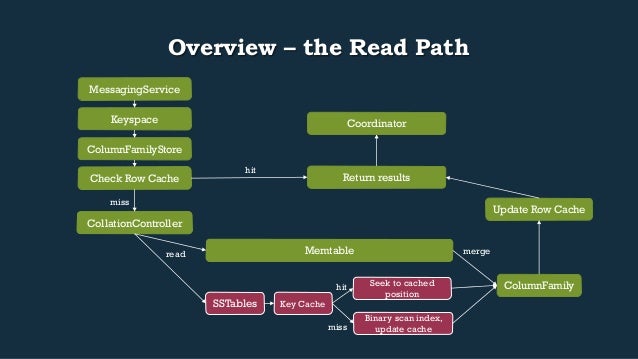
- 20. Overview – the Read Path Return results Keyspace ColumnFamilyStore Check Row Cache CollationController hit miss Memtable read merge SSTables Update Row Cache ColumnFamily Coordinator MessagingService Key Cache Seek to cached position Binary scan index, update cache hit miss
- 21. RowCache • CFS.getThroughCache(UUID cfId, QueryFilter filter) • After retrieving our CFS, the first thing we check is our Row Cache to see if the row is already merged, in memory, and ready to go • If we get a cache hit on the key, we’ll: • Confirm it’s not just a sentinel of someone else in flight. If so, we query w/out caching • If the data for the key is valid, we filter it down to the query we have in flight and return those results as it’ll have >= the count of Cells we’re looking for • On cache miss: • Eventually cache all top level columns for the key queried if configured to do so (after Collation) • Cache results of user query if it satisfies the cache config params • Extend the results of the query to satisfy the caching requirements of the system
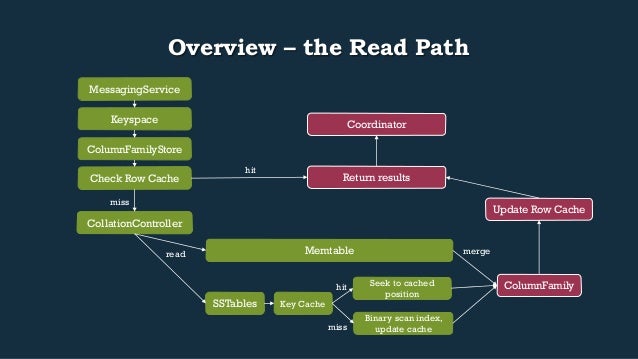
- 22. Overview – the Read Path Return results Keyspace ColumnFamilyStore Check Row Cache CollationController hit miss Memtable read merge SSTables Update Row Cache ColumnFamily Coordinator MessagingService Key Cache Seek to cached position Binary scan index, update cache hit miss
- 23. CollationController.collect*Data (…) • The data we’re looking for may be in a Memtable, an SSTable, multiple of either, or a combination of all of them. • The logic to query this data and merge our results exists in CollationController.java: • collectAllData • collectTimeOrderedData • High level flow: 1. Get data from memtables for the QueryFilter we’re processing 2. Get data from sstables for the QueryFilter we’re processing 3. Merge all the data together, keeping the most recent 4. If we iterated across enough sstables, “hoist up” the now defragmented data into a memtable, bypassing CommitLog and Index update (collectTimeOrderedData only)
- 24. Overview – the Read Path Return results Keyspace ColumnFamilyStore Check Row Cache CollationController hit miss Memtable read merge SSTables Update Row Cache ColumnFamily Coordinator MessagingService Key Cache Seek to cached position Binary scan index, update cache hit miss
- 25. CollationController merging: memtables • Fairly straightforward operations on memtables in the view: • Check all memtables to see if they have a ColumnFamily that matches our filter.key • Add all columns to our result ColumnFamily that match • Keep a running tally of the mostRecentRowTombstone for use in next step.
- 26. Overview – the Read Path Return results Keyspace ColumnFamilyStore Check Row Cache CollationController hit miss Memtable read merge SSTables Update Row Cache ColumnFamily Coordinator MessagingService Key Cache Seek to cached position Binary scan index, update cache hit miss
- 27. CollationController merging: sstables • We have a few optimizations available for merging in data from sstables: • Sort the collection of SSTables by the max timestamp present • Iterate across the SSTables • Skipping any that are older than the most recent tombstone we’ve seen • Create a “reduced” name filter by removing columns from our filter where we have fresher data than the SSTR’s max Timestamp • Get iterator from SSTR for Atoms matching that reduced name filter • Add any matching OnDiskAtoms to our result set (BloomFilter excludes via iterator with SSTR.getPosition() call)
- 28. Overview – the Read Path Return results Keyspace ColumnFamilyStore Check Row Cache CollationController hit miss Memtable read merge SSTables Update Row Cache ColumnFamily Coordinator MessagingService Key Cache Seek to cached position Binary scan index, update cache hit miss
- 29. THE WRITE PATH
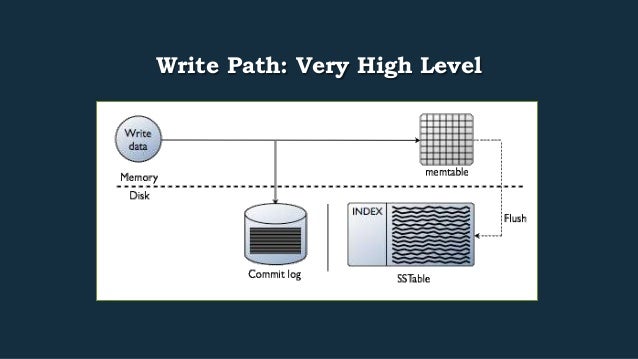
- 30. Write Path: Very High Level
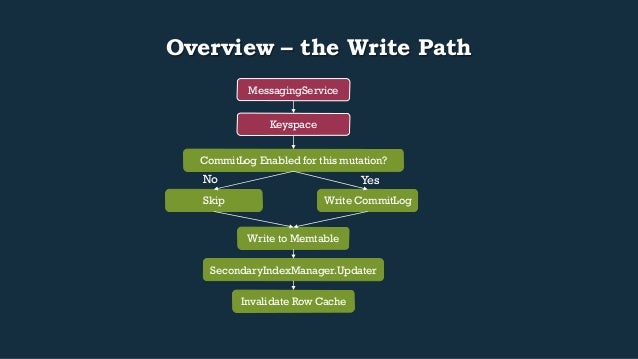
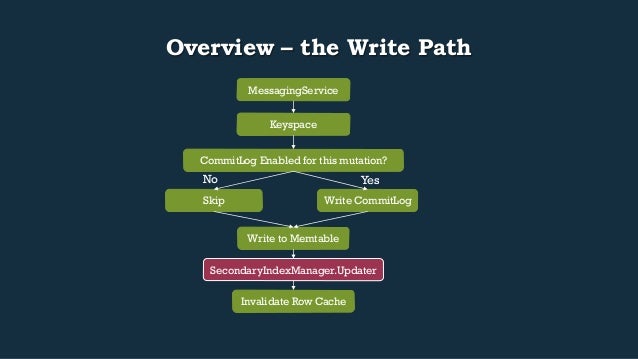
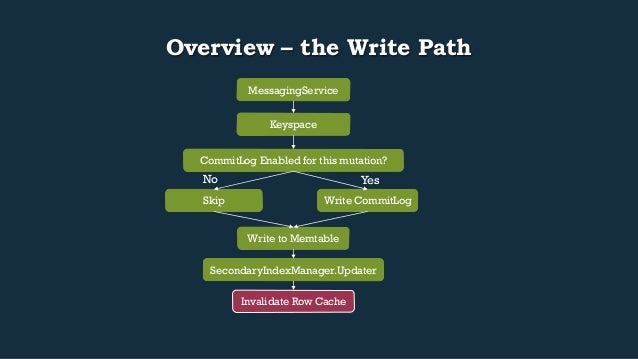
- 31. Overview – the Write Path MessagingService Keyspace CommitLog Enabled for this mutation? Yes Write CommitLog No Skip Write to Memtable SecondaryIndexManager.Updater Invalidate Row Cache
- 32. MutationVerbHandler, Mutation.apply • Contains Keyspace name • DecoratedKey • Map of cfId to ColumnFamily of modifications to perform • MutationVerbHandler Mutation.apply() Keyspace.apply() ColumnFamilyStore.apply()
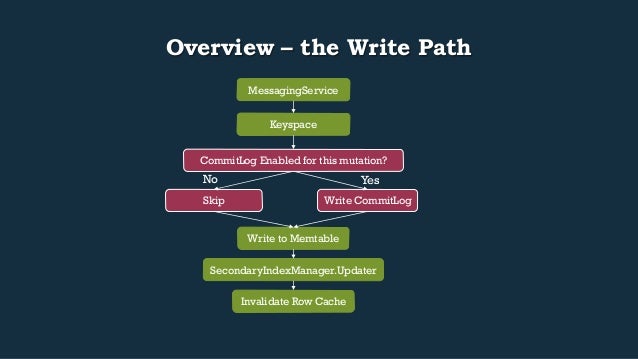
- 33. Overview – the Write Path MessagingService Keyspace CommitLog Enabled for this mutation? Yes Write CommitLog No Skip Write to Memtable SecondaryIndexManager.Updater Invalidate Row Cache
- 34. The CommitLog ecosystem • CommitLogSegmentManager: allocation and recycling of CommitLogSegments • CommitLogSegment: file on disk • CommitLogArchiver: allows user-defined archive and restore commands to be run • Reference conf/commitlog_archiving.properties • An AbstractCommitLogService, one of either: • BatchCommitLogService – writer waits on sync to complete before returning • PeriodicCommitLogService – Check if sync is behind, if so, register w/signal and block until lastSyncedAt catches up
- 35. CommitLogSegmentManager (CLSM): overview • Contains 2 collections of CommitLogSegments • availableSegments: Segments ready to be used • activeSegments: Segments that are “active” and contain unflushed data • Only 1 active CommitLogSegment is in use at any given time • Manager thread is responsible for maintaining active vs. available CommitLogSegments and can be woken up by other contexts when maintenance is needed
- 36. CLSM: allocation on the write path • During CommitLog.add(…), a writer asks for allocated space for their mutation from the CommitLogSegmentManager • This is passed to the active CommitLogSegment’s allocate(…) method • CommitLogSegment.allocate(int size) spins non-blocking until the space in the segment is allocated, at which time it marks it dirty • If the allocate(…) call returns null indicating we need a new CommitLogSegment: • CommitLogSegment.advanceAllocatingFrom(CommitLogSegment old) • Goal is to move CLS from available to active segments so we have more CLS to work with • If it fails to get an available segment, the manager thread is woken back up to do some maintenance, be it recycling or allocating a new CLS
- 37. CLSM: manager thread, new segments, recycling • Constructor creates a runnable that blocks on segmentManagementTasks • Task can either be null indicating we’re out of space (allocate path) or a segment that’s flushed and ready for recycle • If there’s no available segments, we create new CommitLogSegments and add them to availableSegments • hasAvailableSegmentsWaitQueue is signaled by this to awake any blocking writes waiting for allocation • When our CommitLog usage is approaching our allowable “limit”: • If our total used size is > than the size allowed • CommitLogSegmentManager.flushDataFrom on a list of activeSegments • Force flush on any CFS that’s dirty • Which switches Memtables and flushes to SSTable – more on this later
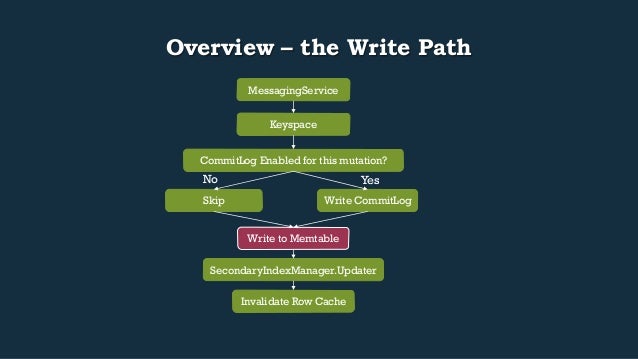
- 38. Overview – the Write Path MessagingService Keyspace CommitLog Enabled for this mutation? Yes Write CommitLog No Skip Write to Memtable SecondaryIndexManager.Updater Invalidate Row Cache
- 39. Memtable writes • We attempt to get the partition for the given key if it exists • If not, we allocate space for a new key and put an empty entry in the memtable for it, backing that out if we race and someone else got there first on allocation • Once we have space allocated, we call addAllWithSizeDelta • Add the record to a new BTree and CAS it into the existing Holder • Updates secondary indexes • Finalize some heap tracking in the ColumnUpdater used by the BTree to perform updates • Further reading: • AtomicBTreeColumns.java (specifically addAllWithSizeDelta) • BTree.java
- 40. MemtablePool • Single MEMORY_POOL instance across entire DB • Get an allocator to the memory pool during construction of a memtable • Interface covering management of an on-heap and off-heap pool via SubPool • HeapPool: On heap ByteBuffer allocations and release, subject to GC w/object overhead • NativePool: Blend of on and off heap based on limits passed in • Off heap allocations and release through NativeAllocator, calls to Unsafe • SlabPool: Blend of on and off heap based on limits passed in • Allocated in large chunks by SlabAllocator (1024*1024) • MemtablePool.SubPool / SubAllocator: • Contains various atomically updated longs tracking: • Limits on allocation • Currently allocated amounts • Currently reclaiming amounts • Threshold for when to run Cleaner thread • Spin and CAS for updates on the above on allocator calls in addAllWithSizeDelta
- 41. Overview – the Write Path MessagingService Keyspace CommitLog Enabled for this mutation? Yes Write CommitLog No Skip Write to Memtable SecondaryIndexManager.Updater Invalidate Row Cache
- 42. Secondary Indexes: an overview • Essentially a separate table stored on disk / in memtable • Contains a ConcurrentNavigableMap of ByteBuffer SecondaryIndex • There are quite a few SecondaryIndex implementations in the code base, ex: • PerRowSecondaryIndex • PerColumnSecondaryIndex • KeysIndex • On Write Path: • SecondaryIndex updater passed down through to ColumnUpdater ctor • On ColumnUpdater.apply(), insert for secondary index is called • Essentially amounts to a 2nd write on another “table”
- 43. Overview – the Write Path MessagingService Keyspace CommitLog Enabled for this mutation? Yes Write CommitLog No Skip Write to Memtable SecondaryIndexManager.Updater Invalidate Row Cache
- 44. FLUSHING MEMTABLES
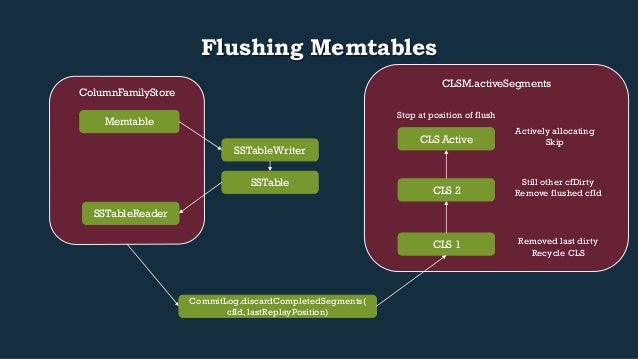
- 45. CLSM.activeSegments ColumnFamilyStore Flushing Memtables Memtable SSTableWriter SSTable SSTableReader CommitLog.discardCompletedSegments( cfId, lastReplayPosition) CLS Active CLS 2 CLS 1 Actively allocating Skip Still other cfDirty Remove flushed cfId Removed last dirty Recycle CLS Stop at position of flush
- 46. MemtableCleanerThread: starting a flush • When MemtableAllocator adjusts the size of the data it has acquired the MemtablePool checks whether or not we need to flush to free up space in memory • If our used memory is > than the total reclaiming memory + the limit * ratio defined in conf.memtable_cleanup_threshold, a memtable needs to be cleaned • Cleaner thread is currently: ColumnFamilyStore.FlushLargestColumnFamily()) • We find the memtable with the largest Ownership ratio as determined by the currently owned memory vs. limit, taking the max of either on or off heap • Signals to CommitLog to discard completed segments on PostFlush stage of flush
- 47. Memtable Flushing • Reference ColumnFamilyStore$Flush • 1st, switch out memtables in CFS.DataTracker.View so new ops go to new memtable • Sets lifecycle in memtable to discarding • Runs the FlushRunnable in the Memtable • Memtable.writeSortedContents • Uses SSTableWriter to write sorted contents to disk • Returns SSTableReader created by SSTableWriter.closeAndOpenReader • Memtable.setDiscarded() MemtableAllocator.setDiscarded() • Lifecycle to Discarded • Free up all memory from the allocator for this memtable
- 48. Memtable Flushing: the commit log • ColumnFamilyStore$PostFlush • All relative to a timestamp of the most recent data in the flushed memtable • Record sentinel for when this cf was cleaned (to be used later if it was active and we couldn’t purge at time of flush) • Walk through CommitLogSegments and remove dirty cfid • Unless it’s actively being allocated from • If the CLS is no longer in use: • Remove it from our activeSegments • Queue a task for Management thread to wake up and recycle the segment
- 49. Switching out memtables • CFS.switchMemtableIfCurrent / CFS.switchMemtable • There’s some complex non-blocking write-barrier operations on Keyspace.writeOrder to allow us to wait for writes to finish in this context before swapping out with new memtables regardless of dirty status • Reference: OpOrder.java,OpOrder.Barrier • Write sorted contents to disk (Memtable.FlushRunnable.runWith(File sstableDirectory) • cfs.replaceFlushed, swapping the memtable with the new SSTableReader returned from writeSortedContents
Cassandra Summit Boot Camp, 2014 Deep dive on Read/Write path, Josh McKenzie presenter
Public clipboards featuring this slide
No public clipboards found for this slide





