
The Fortis project is a social data ingestion, analysis, and visualization platform. Originally developed in collaboration with the United Nations Office for the Coordination of Humanitarian Affairs (UN OCHA), Fortis provides planners and scientists with tools to gain insight from social media, public websites and custom data sources. UN OCHA mobilizes humanitarian aid for crises such as famines, epidemics, and war.
To understand crisis situations and formulate appropriate mitigations, UN OCHA needs access to tremendous amounts of data and intelligence, from a wide range of sources including newspapers, social media, and radio.
Fortis already has support for social media and web content, but UN OCHA wanted to be able to incorporate content from local radio broadcasts. Working together, we created a solution based on Spark Streaming to extract textual information from radio in near real-time by developing a new Java client for Azure Cognitive Services’ speech-to-text APIs. This code story delves into our Fortis solution by providing examples of Spark Streaming custom receivers needed to consume Azure Cognitive Service’s speech-to-text API and showing how to integrate with Azure Cognitive Service’s speech-to-text protocol.
A Spark Streaming pipeline for analyzing radio
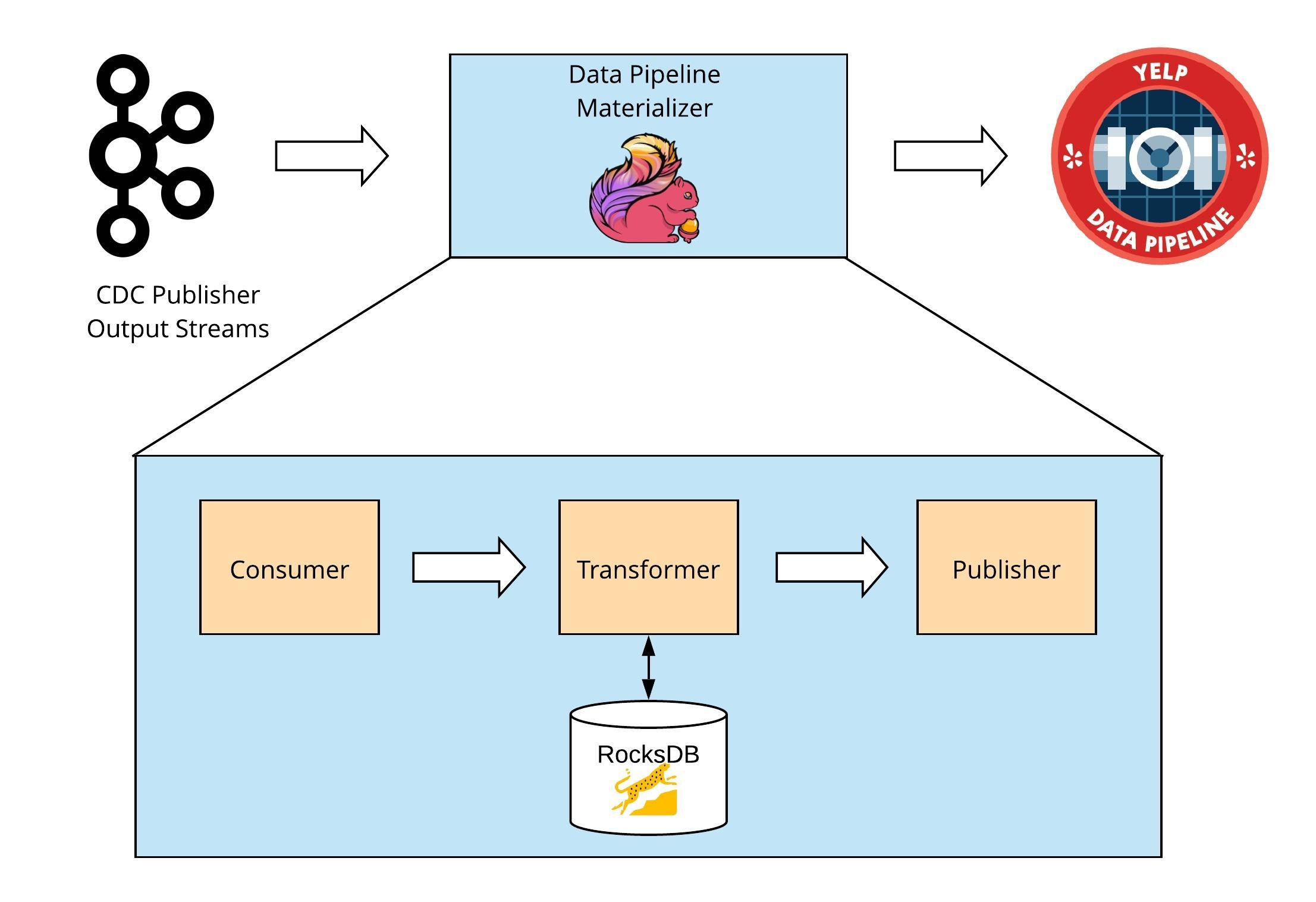
We covered the Fortis pipeline in a previous code story. Below is a brief summary of the pipeline:
- Real-time data sources (such as Facebook, Twitter, and news feeds) generate events
- Events are filtered and analyzed by Spark Streaming
- Spark stores events and aggregations in Cassandra for reporting uses
A NodeJS and GraphQL services layer sends the data from Cassandra to a ReactJS dashboard.

To add radio analysis to this pipeline, we made three simplifying assumptions:
- The raw radio stream is freely accessible on the web via HTTP
- The content published via the radio stream can be discretized into short segments
- The radio content can be meaningfully analyzed via its textual transcription
Once framed in this way, we see that we need two pieces to ingest radio into a Spark Streaming pipeline:
- A mechanism to get transcribed radio content into our Spark cluster for processing via our text-based analyses as described in a previous code story
- A process to receive audio from a radio feed (such as the BBC World Service or Radio France International) and convert it to text
The following sections will cover each of these pieces.
Consuming arbitrary APIs via Spark Streaming custom receivers
Spark’s custom receivers are a powerful mechanism to turn APIs into real-time data sources for Spark Streaming. A custom receiver needs to implement just a few methods. For example, in Scala:
After we define our custom receiver, we can now turn its underlying data source into a Spark stream that is easy to consume via the usual high-level Spark APIs:
We make heavy use of custom receivers in the Fortis project as a simple way to turn APIs into streaming data-sources. Fortis has published packages to integrate with the Facebook API, Reddit API, Instagram API, Bing News API and RSS feeds. Similarly, the radio-to-text functionality described below is wrapped in a custom radio receiver to integrate it into our Spark pipeline.
Converting radio to text in near real-time
After solving the problem of how to integrate custom data sources into Spark, we next require a solution to convert a stream of audio, such as from an online radio broadcast, to a stream of text.
Azure Cognitive Services has been offering speech-to-text capabilities for more than 10 languages for a long time via the Bing Speech API. However, the API is based on a request-response paradigm which is not suited to our streaming use case as it would require us to buffer large audio clips in the radio receiver, send the chunks to the speech-to-text service and wait for a transcribed response. This approach would introduce latency and HTTP request overhead.
However, Azure Cognitive Services recently published a speech-to-text protocol that works via WebSockets which are well suited for a streaming scenario. We simply open a single bi-directional communication channel via a WebSocket connection and use it to continuously send audio to the speech-to-text service and receive back the transcribed results via the same channel.
A reference implementation of this speech-to-text approach via WebSockets exists for Javascript and an unofficial implementation exists for NodeJS. We created a new implementation of the protocol in Java so that we can leverage the WebSocket speech-to-text from our Scala-on-Spark pipeline.
How does the WebSocket speech-to-text protocol work?
After creating a Bing Speech API resource in Azure and noting the access key, we’re ready to start implementing the speech-to-text WebSocket protocol.

The speech-to-text WebSocket protocol specifies three phases that clients must implement:
- Establishing the speech-to-text WebSocket connection
- Transcribing audio via the speech-to-text WebSocket
- Closing the speech-to-text WebSocket connection
In the first phase, the client identifies itself with the speech-to-text service and establishes the WebSocket connection. After identification, the client is free to send audio to the speech-to-text service and receive back transcriptions. Eventually, the speech-to-text service will detect the end of the audio stream. When the end is detected, the speech-to-text service will send the client an alert that the audio stream is done getting messages. The client will respond to the service’s end-of-the-audio message by closing the WebSocket speech-to-text connection.
The full end-to-end flow is illustrated in the diagram below and each phase is described in more detail in the following sections.

Phase 1: Establishing the speech-to-text WebSocket connection
To kick off a speech-to-text session, we need to establish a connection with the Bing speech-to-text WebSocket service and identify our client via our API token for the Bing service. Note that all authentication and configuration information must be passed in via query parameters on the WebSocket connection URL since many WebSocket clients don’t have support for headers that would typically be used for sending information like API tokens. For example, using the Java NV WebSocket client, we’d connect to the speech-to-text service as follows:
After the WebSocket connection is established, we must send additional identifying information about our client (like the operating system used, the audio source being transcribed, etc.) to the speech-to-text service via a WebSocket text message and then we’re ready to transcribe audio:
Phase 2: Transcribing audio via the speech-to-text WebSocket
Once the client has successfully identified itself with the speech-to-text service, it can start sending chunks of audio for transcription, via binary WebSocket messages:
The messages follow a specific schema:

Note that the audio data sent to the speech-to-text service must be single-channel mono WAV audio sampled at 16kHz with 16 bits per sample. The speech-to-text service does not validate the format of the audio messages and will silently return incorrect transcriptions on receipt of messages with malformed encodings.
Most online radio is in MP3 rather than WAV format, making an audio format conversion step necessary for the radio input to be processed by the speech-to-text service. The Java ecosystem has a lack of great open source, permissively licensed streaming MP3 decoders; as a result, our client resorts to converting small batches of MP3 audio to WAV on disk using the javazoom converter and then resampling the WAV using the javax.sound APIs with the Tritonus plugin. Hopefully, in the future, the trip to disk will be made unnecessary by moving to a streaming or in-memory MP3 decoder.
After the client starts sending audio messages to the speech-to-text service, the service will transcribe the audio and send the transcription results back to the client. Via WebSocket, transcriptions will be sent with a JSON payload for the client to parse and process. Note that the service may choose to batch multiple input audio messages sent by the client into a single output transcription message returned to the client.
Phase 3: Closing the speech-to-text WebSocket connection
When the client wishes to close the connection with the speech-to-text service, it must execute three steps in sequence:
- Send an audio message as described in Phase 2, but with a zero-byte audio payload
- Send telemetry as a JSON WebSocket text message about its perception of the speech-to-text service’s performance
- Shut down the WebSocket connection
Sending the connection-end telemetry is like the client-information telemetry described in Phase 1 above. The schema for the JSON payload of the message is well documented.
Summary
In many parts of the world, essential information is broadcast via traditional sources such as radio. To formulate effective crisis response plans, the United Nations Office for the Coordination of Humanitarian Affairs needs to be able to access and analyze these data sources in a timely manner.
To solve this problem, we created a Java client for the Azure Cognitive Services speech-to-text WebSocket protocol. We then fed the transcribed radio into a pipeline based on Spark Streaming for further analysis, augmentation, and aggregation. This solution enabled us to ingest and analyze radio in near real-time.
Our Java client is reusable across a wide range of text-to-speech scenarios that require time-efficient speech-to-text transcription in more than 10 languages including English, French, Spanish, German and Chinese.