Data modelling in Cassandra revolves around two goals:
- Spread data evenly among partitions.
- A read query should (ideally) hit only a single partition.
Often you will find yourself in scenarios, and as you will see later in examples, these rules start conflicting, so you have to balance them according to business requirements.
Data Modelling Tips
Before going through the data modelling examples, let’s review some of the points to keep in mind while modelling the data in Cassandra.
- Model your data around queries and not around relationships. In other words, your data model should be heavily driven by your read requirements and use cases.
- Create tables where you can satisfy your queries by reading (ideally) one or minimum number of partitions.
- Each table should pre-build the answer to a high-level query that you need to support.
- Key point to remember is Optimize for Reads.
- Remember Writes are Cheap, disks are available at very low costs, and data duplication is fact of life in Cassandra. Don’t be afraid of data duplication while trying to optimize for reads.
Data Modelling Examples
Lets look at few examples and try to apply the knowledge we have gained so far on Cassandra.
Example 1
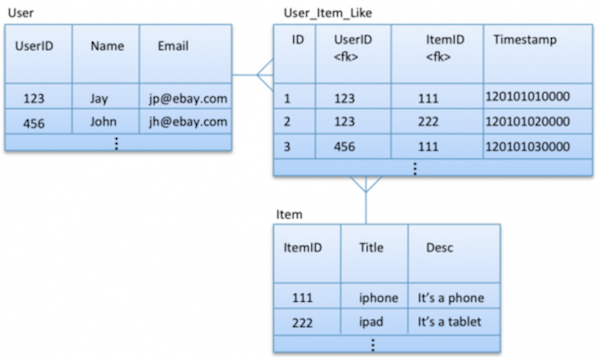
Consider a scenario where we have a large number of users and we want to look up a user by username or by email. With either method, we should get the full details of matching user.

In first implementation we have created two tables. One has partition key username and other one email. Note that we are duplicating information (age) in both tables.
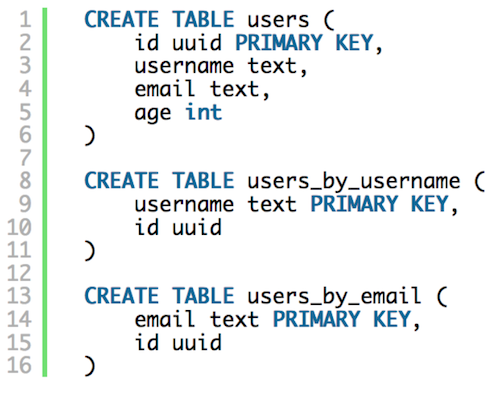
Another way to model this data could be what’s shown above. In this case we have three tables, but we have avoided the data duplication by using last two tables as reference tables. Just like before reference tables are partitioning the data using username and email, but user details are located at a single place.
So which data model is better?
Recall two primary rules of data modelling in Cassandra (1) each partition should have roughly same amount of data (2) read operations should access minimum partitions, ideally only one.
If we apply these rules to model #1, we will only need to access one partition to get full user details. Additionally, we can easily find which partition contains our data as both username and email have been used as partition key. Assuming usernames and emails have uniform distribution, we will have roughly same quantity of data in each partition.
Now, lets evaluate model #2. Although there is no data duplication in this model (keep in mind it’s okay to have data duplication as long as it optimizes read performance) but it comes with one big disadvantage: it violates the rule of reading from a single partition. To find user details, first we will go to a partition using username (or email), and then we will do another partition lookup through uuid.
Therefore, in this scenario it is better to use model #1.
Example 2
Our requirements have been updated. Now, each user belongs to a group. And we want to fetch all users of a group by group name including all details of its users.

Here, data will be distributed among nodes based on group_name (partition key) and sorted within a node by username (clustering key). Each group stores complete information of its users.
Our proposed model satisfies the first data modeling principle, i.e. to read any group’s data we will have to hit only a single partition and there will find all users of that group. But does this model satisfy the 2nd principle? The answer is probably not. Why? Because generally, in the real world, there will be some very populated groups while other groups might be very small. Which means the size of partitions won’t be roughly same, and that is violation of our data modelling principle.
One way to fix this could be this model

Now we are using a composite partition key, where hash_prefix is a just random number. This composite key will ensure that data is uniformly distributed among nodes hence our model no longer violates the 2nd principle. But it comes with a catch. As data will be distributed uniformly among partitions, in order to fetch all users in a particular group we will have to read more than one partition, hence violating the 1st principle.
This example teaches us an interesting lesson in Cassandra data modelling.
The two data modeling principles often conflict, therefore you have to find a balance between the two based on domain understanding and business needs.
Example 3
Continuing on the previous examples, our new requirement is to add support for getting X newest users in a group. Here is one data model

All user data is located at a single place, data is partitioned by group_name and ordered by join date. [Ignoring the issue of data distribution we already discussed in last example] Model looks decent. Lookup by group name would take us to exact partition containing group data, sorting by join date means we only need to read last X records from the end. There is one further improvement we can do on this model which will make our queries more faster.

Here, we are still sorting the partition data by join date, but in descending order. Now, we won’t even need to go to end of partition in order to read last X records. We can simply read top X records from the start of partition, hence reducing the IO cost.
Recall the data distribution problem we touched upon earlier, one way to solve that could be this.

We have made the partition key composite by adding join date. This way a new partition will be created everyday for every group. Assuming each group is roughly inducting same number of users daily, this model can work. But now, in order to get last X joined users in a group, we will have to read more than one partition if number of users who joined that group in last day are less than X. One way to fix this could be to benchmark the number of users joining daily and set the composite key in such a way that last X users query only need to access a single partition.
Example 4
Let’s implement a simple Facebook use case where we need to fetch recent posts posted by a specific user. Here is a possible data model

Here, partition key user_id can easily take us to partition carrying posts of a particular user, sorting by post_id will help us in locating top X posts, and the descending order will further reduce our disk seeks by removing the need to go until the end of partition.
Example 5
Let’s say we are developing an e-commerce site and we need to support following queries.
- Get user by user id.
- Get item by item id.
- Get all the items that a particular user likes.
- Get all the users who like a particular item.
Here is an entity relationship diagram showing relationship between entities described in the use case.
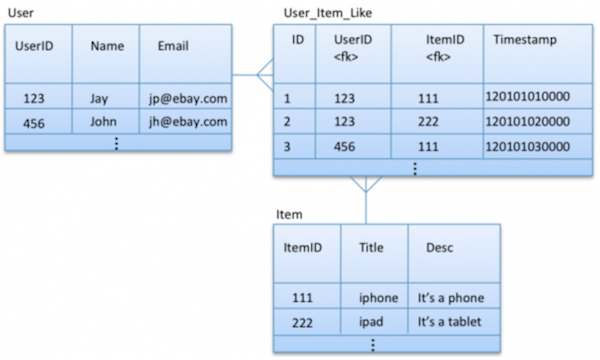
Lets start with a simple relational-like data model where we have three tables. First for keeping users with user Id as partition key, second for items with item Id as partition key, and third for storing user-item likes partitioned by unique Id assigned to each like record.
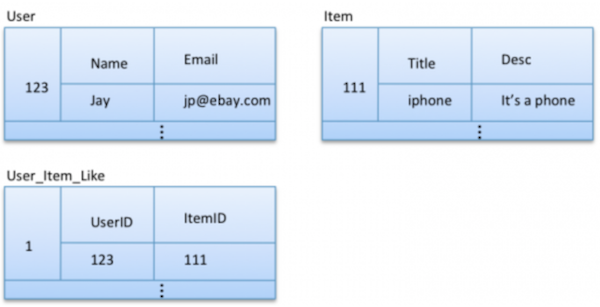
If Ids are being auto generated, each partition will have roughly same amount of data which satisfies our first data modelling goal. Coming to partition reads, this data model will be able to find result of query #1 and #2 very efficiently as Id of each user and item is being used as partition key. But, there is no easy way to access data for query #3 and #4 because there is no way to predetermine what partitions might have the required data. Rather all partitions will have to be scanned, which violates our second data modelling principle.
A better data modelling approach can be following.
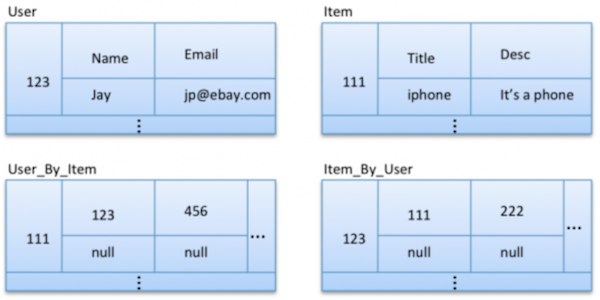
Here, we have divided the user-like relationship table into two by introducing data redundancy. Using this redundancy we are able to partition data by both user Id and item Id separately. This gives us the ability to look at specific partitions when finding results for query #3 and #4.
But there is still one problem, note that we are only getting Ids i.e. user Id and item Id, from the newly introduced tables. In this design, we will still have to look up user and item partitions if we want to show meaningful information about users and items involved. Here is a quick fix, again using data duplication.
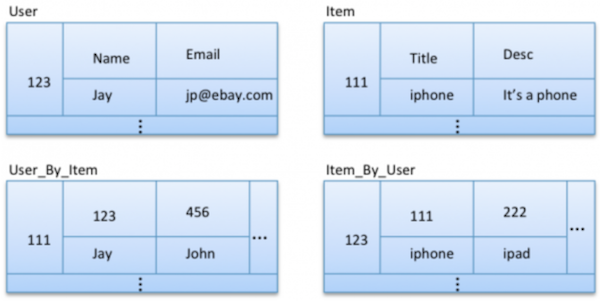
It is important to note here that we are not duplicating entire information of user or item in the relationship tables. For example, to show email or item description a lookup will still be required, but that decision is driven by business context. For example, in this case, we might be showing only user name or item title on initial interface and let user click on user/item for further details.
Next: Apache Cassandra, Part 6: Time Series Modelling in Cassandra