
In this guide, I’ll walk through what Cassandra generally is — and is not — its specific capabilities, and some recent examples of Cassandra’s use in projects at Insight Data Engineering (where I was a Fellow during the summer of 2017) and in industry.
I hope this guide is helpful for future Insight Data Engineering Fellows as they refine their projects and build their pipelines (especially Fellows who don’t have a lot of experience with distributed computing), as well as members of the public interested in data engineering!
This is not meant to be a comprehensive explanation of pipeline development with Cassandra, and as always, the documentation is the best place to start for answering technical questions, including installation and configuration.
What Cassandra is — and is not
Cassandra is a distributed NoSQL data storage system from Apache that is highly scalable and designed to manage very large amounts of structured data. It provides high availability with no single point of failure.
Cassandra’s data model is a partitioned row store with tunable consistency where each row is an instance of a column family that follows the same schema, and the first component (a component is a Cassandra data type) of a table’s primary key is the partition key.
Cassandra has been designed from the ground up with scalability and write speed in mind, which is a design choice reflected in the partitioning structure of a Cassandra keyspace. A keyspace is analogous to a SQL database, and a column family is analogous to a relational database table. For the rest of this guide, I’ll use the terms “database” and “table” to refer to a Cassandra keyspace and column family.
When first learning about the storage and computational resources required by Cassandra, I found it helpful to throw out my idea of relational database tables — Cassandra tables are stored as nested sorted maps, with all the write speed and overhead requirements that data structure implies. Within a partition, rows are stored by the remaining columns of the key and may be indexed separately, a parameter tunable within the Cassandra configuration.
This partitioning paradigm is the key to Cassandra’s fast write speed and a key tradeoff to consider compared to a relational database — because no matter how simple a Cassandra table query is, read/write efficiency is entirely dependent on the amount of partitions that must be accessed to answer a query.
Another basic property of Cassandra tables is the replication factor, which is the total number of nodes a copy of a row exists on. There is no master node in a Cassandra cluster, so the replication factor is easily tunable and Cassandra can support a replication factor of 1 (minimum) or more for any data type.
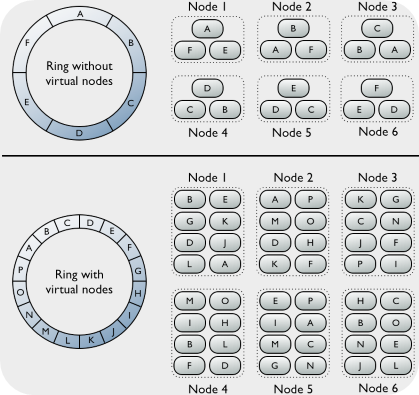
The replication factor is a key consideration when setting up a Cassandra cluster, as different use cases will have different needs for consistency and fault tolerance. For a very basic illustration of cluster size, replication factor, write/read level, and their impacts on cluster performance, please see this calculator. Modern Cassandra clusters also use a virtual node system to improve load balance for high volumes of reads to the cluster and compensate for heterogeneous machines.
Gossip is the message system that Cassandra nodes/virtual nodes use to make their data consistent with each other, and is used to enforce the replication factor in a cluster. Imagine a Cassandra cluster as a ring system where each node contains certain partitions of each table in a database and can only communicate with adjacent nodes.
Because of the replication factor, reads/writes in Cassandra are often managed by quorum, which is the last important concept I’d like to outline in this section.
Quorum is a tunable parameter where a strict majority of the nodes in the cluster must agree on the existing value of an object in a table to accept a read or write request. With the read level, R, and write level, W, of a cluster configurable for a cluster of size, N (e.g.; N is 5 for a 5-node cluster), if R+W>N, the cluster is said to be strongly consistent — a desirable property for many use cases where the user can be confident that writes and reads they make to any node will propagate reliably to the entire cluster.
Whether a cluster has strong or weak consistency, it will always be eventually consistent. Weakly consistent systems depend on quorum to evaluate timestamps of values and resolve conflicts in the event of partial writes. The key tradeoff is that strongly consistent systems have higher overhead for a standard read/write operation in terms of time to consistency.
One more thing: Cassandra is not a silver bullet for all your data storage needs, and is not the best choice for any arbitrary distributed database project. If you have a strong requirement for immediate consistency accompanied by high read speed, there are other databases with robust ACID tolerance for highly structured data, and you could consider playing to their strengths. Or, if you are ingesting data from sources of different priority where quorum cannot be used to evaluate write priority, Cassandra is not for you!
Other NoSQL applications specialize in different areas, and traditional RDBMS are not out of style yet for a good reason.
Recent Insight projects using Cassandra
Insight Data Engineering Fellow Adam Costarino used Cassandra in his project, Reddit Rank, a tool to map user influence and construct a graph to analyze subreddit similarity. Cassandra was an important part of his pipeline because he needed to construct a large number of adjacency lists — large enough to contain the entire post history on Reddit from the past 7 years! In his tables, adj_year was used to construct adjacency lists for distinct users by year. Adam chose a final Cassandra cluster size of 5 with a replication factor of 3 to accommodate the large amount of reads queries (via Spark) that his Cassandra tables would need.
Another Fellow, Kyle Schmidt used Cassandra in his project, Instabrand, to evaluate user relationships for a large Instagram-like social network. He fabricated user data from the Instagram API and used Cassandra to store information on events (likes, follows, and comments) and make results accessible to a web-based interface. His Cassandra cluster was able to manage real-time stream processing and writes to Cassandra from Spark for millions of users.
Yours truly also used Cassandra in my Insight project, discorecs. My project used release data from Discogs (a vinyl record database and marketplace) along with synthesized activity for 10M users to power a recommendation engine for new friends and album purchases. Cassandra was used to store the results from my recommendation calculations (in Spark) as well as a copy of the release metadata in Discogs to display on my web UI. Cassandra was run with full replication on 5 nodes in order to support writes from my batch and stream processing in Spark.
Recent enterprise projects using Cassandra in industry
Raptor Smart Advisor uses Cassandra to read and write user behavior for thousands of clients, along with Spark to batch process updates from data mining models. The linear scaling of nodes and easy retrieval of simple queries with CQLSH have allowed them to scale their service rapidly to create personalized recommendations for relevant products and improve UX on their clients’ sites.
AdVoice is a telecom-focused ad network and uses Cassandra to seamlessly serve ads to clients and monitor customers’ audio/text inventory in real time in an accessible environment. Along with Cassandra’s scalability and functionality, they use enterprise features only present in DataStax Enterprise to monitor analytics tools and enable in-memory caching of table views for clusters of variable size.
SmarterWeb has implemented an electronic invoicing system for a rapidly growing client base of Mexican and Central American customers in Cassandra. Easy integration with Solr and scalability of the cluster were key considerations for their use case, and Cassandra was able to compensate for issues they had with read consistency due to deadlock and timeouts in SQL Server and Azure.
Conclusion
Cassandra is a flexible and scalable tool that’s perfect for handling a high volume of incoming data. Because of its virtual node, replication factor, and partitioning paradigms, Cassandra is particularly well-suited to ingesting structured data and making it eventually consistent with a high degree of fault tolerance. While not perfect for every use case, it’s popular among Insight fellows and enterprise applications, and has many tutorials available online. I hope this guide has been a useful primer to Cassandra, and good luck to any future Insight Data Engineering Fellows reading this on your projects! You’re gonna do great!
Special thanks to Adam and Kyle for the code snippets from their Insight projects, used here with permission.





